
1 说明:
=====
1.1 ggplot2:
1.1.1 是由Hadley Wickham创建的一个十分强大的可视化R包。
1.1.2 就是说ggplot2,是R语言下的一款强大的、大名鼎鼎的数据可视化绘图库。
1.2 plotnine:
1.2.1 plotnine是Python中图形语法的一种实现,它基于ggplot2,绘图精美而简单。
1.2.2 德国学者借鉴R语言ggplot2包的语法开发了plotnine包,几乎实现了对R语言ggplot2语法的直接移植。

2 准备:
=====
2.1 官网:
https://github.com/has2k1/plotnine
https://plotnine.readthedocs.io/en/stable/index.html2.2 环境:
华为笔记本电脑、深度deepin-linux操作系统、python3.8和微软vscode编辑器。
2.3 安装:
#部分安装
pip install plotnine
#本机安装
sudo pip3.8 install plotnine
#推荐国内源安装,超快
sudo pip3.8 install -i https://mirrors.aliyun.com/pypi/simple plotnine
#全部安装
pip install 'plotnine[all]' # includes extra/optional packages
#本机全部安装
sudo pip3.8 install -i https://mirrors.aliyun.com/pypi/simple 'plotnine[all]'3 自带数据集:
==========
3.1 代码:R语言的语法
#自带数据集
#实际意义不大,看看效果和语法
from plotnine import *
from plotnine.data import *
#导入数据集
mpg.head()
#格式和语法
d=(
ggplot(mpg, aes(x='cty', color='drv', fill='drv'))
+ geom_density(alpha=0.1)
)
#显示,区别,不是show,而是打印:print
print(d)3.2 图:
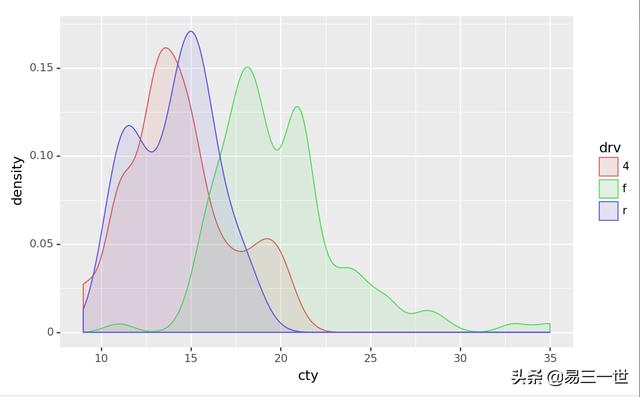
4 虚拟数据:
========
4.1 嵌入式数据:字典法:
4.1.1 代码:
from plotnine import *
import pandas as pd
#导入数据
median_age_dict={
'Country': ['New Zealand','Spain','Ireland','Israel','Denmark','Norway','Netherlands','Australia','Italy','Sweden'],
'Age': [39.0, 37.0, 35.0, 34.0, 34.0, 34.0, 34.0, 34.0, 34.0, 34.0]
}
median_age=pd.DataFrame(median_age_dict)
#绘图,公式最后添加
d=(
ggplot(median_age,aes(x='Country',y='Age',fill='Country'))#创建图象,传入数据来源和映射
+ geom_bar(stat='identity',width=0.5)#建立几何对象,画直方图
+ geom_text(aes(x='Country',y='Age',label='Age'),nudge_y=2)#添加数据标签
+ coord_flip()#纵向直方图转换为横向直方图
+ xlim(median_age['Country'][::-1])#x轴排序,横向直方图的关系
+ theme_grey(base_family = "DejaVu Sans" ) #字体,暂时不支持中文
)
#显示图片
print(d)4.1.2 图:
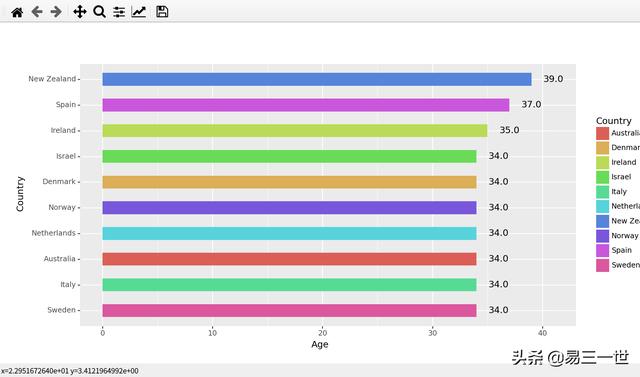
4.2 嵌入式数据:pd内:
4.2.1 代码:
import pandas as pd
from plotnine import *
#嵌入式数据在pd内
df = pd.DataFrame({
'variable': ['gender', 'gender', 'age', 'age', 'age', 'income', 'income', 'income', 'income'],
'category': ['Female', 'Male', '1-24', '25-54', '55+', 'Lo', 'Lo-Med', 'Med', 'High'],
'value': [60, 40, 50, 30, 20, 10, 25, 25, 40],
})
df['variable'] = pd.Categorical(df['variable'], categories=['gender', 'age', 'income'])
df['category'] = pd.Categorical(df['category'], categories=df['category'])
#绘图
d=(ggplot(df, aes(x='variable', y='value', fill='category'))
+ geom_col())
#dpi是分辨率的单位,是dot per inch(每英寸所打印的点数或线数)
#PPI(Pixel Per Inch)表示数字影像的解析度,以区分二者
#保存图片
#d.save('/home/xgj/Desktop/datavis/plotnine/test.pdf',width=20,height=15,dpi = 300)
#显示图片
print(d)4.2.2 图:
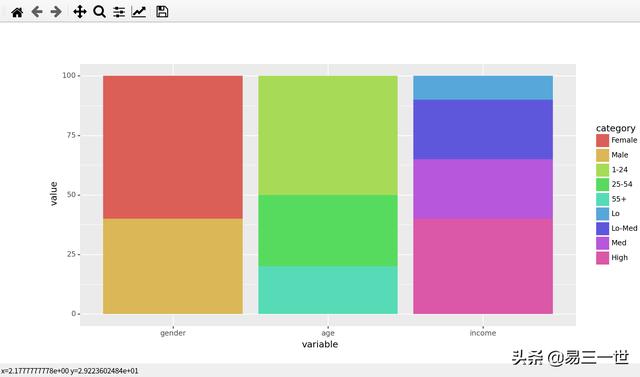
5 csv文件数据:
===========
5.1 生成csv文件:
5.1.1 复习:《Tablib:是一款简单好用、多种格式的数据管理的Python库》
5.1.2 代码:
#---数据导出csv
import tablib
#表头,支持中文
headers = ('variable', 'category', 'value')
#数据
data = [
('gender', 'Female', 60),
('gender', 'Male', 40),
('age', '1-24', 50),
('age', '25-54', 30),
('age', '55+', 20),
('income', 'Lo', 10),
('income', 'Lo-Med', 25),
('income', 'Med', 25),
('income', 'High', 40),
]
#数据集合
data=tablib.Dataset(*data, format='csv', headers=headers) #表头显示,注意这里不是True
#csv的特色
data.export('csv', delimiter=' ', quotechar='|')
#指定路径和文件名
with open('/home/xgj/Desktop/datavis/plotnine/csvoutdata.csv', 'w', newline='') as f:
f.write(data.export('csv'))5.2 读取csv文件并作图:
5.2.1 代码:
import pandas as pd
from plotnine import *
#读取csv文件
data = pd.read_csv('/home/xgj/Desktop/datavis/plotnine/csvoutdata.csv')
#pd格式化数据
df = pd.DataFrame(data)
#设定和分类
df['variable'] = pd.Categorical(df['variable'], categories=['gender', 'age', 'income'])
df['category'] = pd.Categorical(df['category'], categories=df['category'])
#绘图
d=(ggplot(df, aes(x='variable', y='value', fill='category'))
+ geom_col())
#显示图片
print(d)5.2.2 图:和4.2.2图一样,此处省略。
===其他方法都是ggplot2的R语言的语法===
===自己整理并分享出来===















