
缓存是互联网高并发系统里常用的组件,由于多增加了一层,如果没有正确的使用效果可能适得其反,诸如“缓存是删除还是更新?”,“先操作数据库还是先操作缓存?”都是些老生常谈的话题,今天我们就来聊一聊缓存与数据库的双写一致性的解决方案。
在一开始先科普下最经典的缓存+数据库读写的模式,就是 Cache Aside Pattern。

为什么是删除缓存,而不是更新缓存?
更新缓存在并发下会带来种种问题,直接删除缓存比较简单粗暴,稳妥。而且还有懒加载的思想,等用到的时候在去数据库读出来放进去,不用到你每次去更新他干嘛,浪费时间资源,而且还有更新失败、产生脏数据的一些风险, 达成这一点共识以后,我们来开始今天的讨论。
1、更新数据库成功,删除缓存成功,没毛病。
2、更新数据库失败,程序捕获异常,不会走到下一步,不会出现数据不一致情况。
3、更新数据库成功,删除缓存失败。数据库是新数据,缓存是旧数据,发生了不一致的情况。这里我们来看下怎么解决
总之,我们要达到最终一致性!
1、删除缓存成功,更新数据库成功,没毛病。
2、删除缓存失败,程序捕获异常,不会走到下一步,不会出现数据不一致情况。
3、删除缓存成功,更新数据库失败,此时数据库中是旧数据,缓存中是空的,那么数据不会不一致。因为读的时候缓存没有,则读数据库中旧数据,然后更新到缓存中。
虽然没有发生数据不一致的情况,看上去好像一切都很完美,但是以上是在单线程的情况下,如果在并发的情况下可能会出现以下场景
1)线程 A 需要更新数据,首先删除了 redis 缓存
2)线程 B 查询数据,发现缓存不存在,到数据库查询旧值,写入 Redis,返回
3)线程 A 更新了数据库
复制代码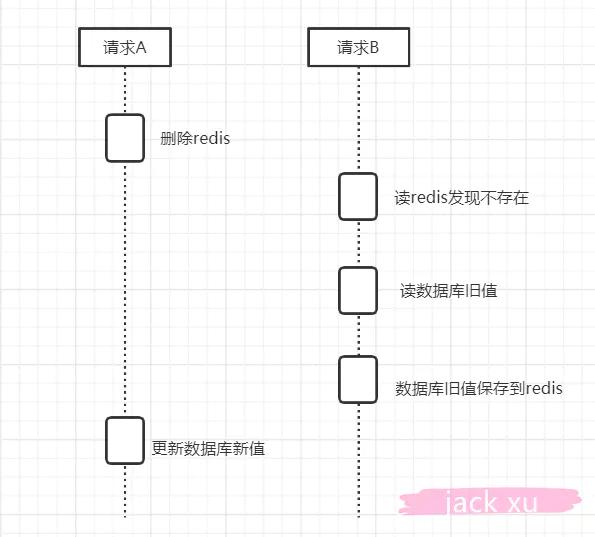
这个时候,Redis是旧的值,数据库是新的值,还是发生了数据不一致的情况。
针对上面这种情况,我们有一种延时双删的方法
1)删除缓存
2)更新数据库
3)休眠 500ms(这个时间,依据读取数据的耗时而定)
4)再次删除缓存
复制代码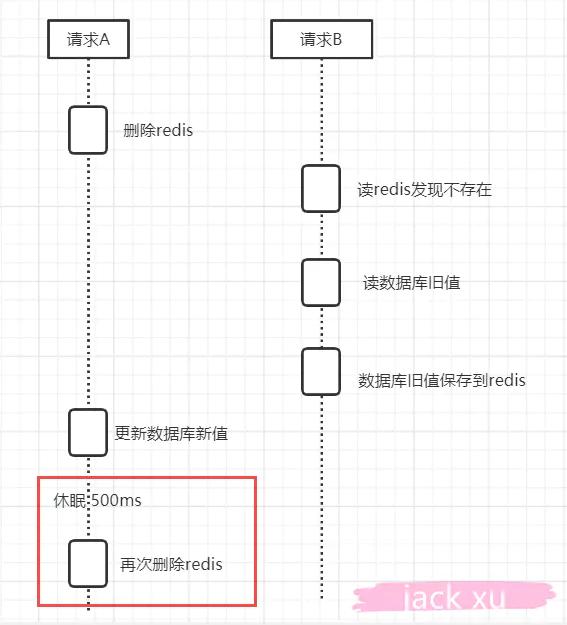
你把旧值存在Redis以后,过一段时间我在删除一次,这时把旧值给删掉了,这样就能保证Redis和数据库是同步的了,这么做在一定程度上可以缓解这个问题,但也不是十分完美,比如第一次缓存删除成功了,第二次缓存删除失败,又该怎么办?
除了延时双删这个方法,还有个方案就是内存队列,他的思想是串行化,我们在JVM中维护一个内存队列。当更新数据的时候,我们不直接操作数据库和缓存,而是把数据的Id放到内存队列;当读数据的时候发现数据不在缓存中,我们不去数据库查放到缓存中,而是把数据的Id放到内存队列。
后台会有一个线程消费内存队列里面的数据,然后一条一条的执行。这样的话,一个更新数据的操作,先删除缓存,然后再去更新数据库,但是还没完成更新。此时如果一个读请求过来,读到了空的缓存,那么先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成。
这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤,如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可。
等内存队列中将更新数据的操作完成之后,才会去执行下一个操作,也就是读数据的操作,此时会从数据库中读取最新的值,然后写入缓存中。 如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回;如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取。
上面说的几种方案,都是比较常见的,也比较简单,没有十全十美的,最后的内存队列也会影响性能以及增加系统的复杂度。今天讨论的Redis和数据库的数据更新是不可能通过事务达到统一的,什么叫做事务,就是一损俱损一荣俱荣,要么都成功要么都失败,这是不能保证的。
我们只能根据相应的场景和所需要付出的代价来采取一些措施,降低数据不一致的问题出现的概率,在数据一致性和性能之间取得一个权衡,具体场景具体使用。
作者:jack_xu
链接:https://juejin.im/post/5edafcb051882543023c0cd0


















