
这个问题相信对学编程的朋友们来说过于简单了,大家想必都是增删改查的好手。
但如果让你说出 10 种不同类型的数据库,阁下该如何应对?
这篇文章,是对数据库技术的一个小科普,希望能帮大家了解到更多元化的数据库,便于拓宽学习思路和项目的技术选型。
首先是我们接触最多的、也是入门后端必学的 关系型数据库 。
在关系型数据库中,数据以 表 的形式进行组织和存储,每个表就像一个 Excel 表格,包含多个 行 和多个 列 。
就比如我们经典的学生管理系统,把学生信息存储到关系型数据库中,结构大概是这样的:
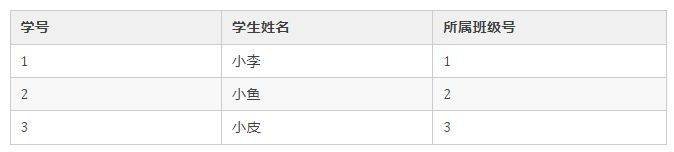
上述学生表格中,每一行代表一个学生的信息,每一列代表学生的一个属性。我们可以使用结构化查询语言 SQL 来对关系型数据库表的数据进行灵活地查询、选择、过滤等。
而关系型数据库最大的特点,就是表和表之间可以 存在关系 。比如学生管理系统中还可以有班级表,结构如下:
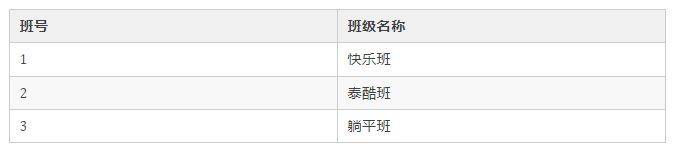
那如果我想知道某个学生所属的班级信息,只需要在查询时将学生表的 所属班级号 和班级表的 班号 进行关联,而不用把所有表格的列存储在一起,非常灵活。
通过 SQL 可以连接查询多张表,得到下面的查询结果:
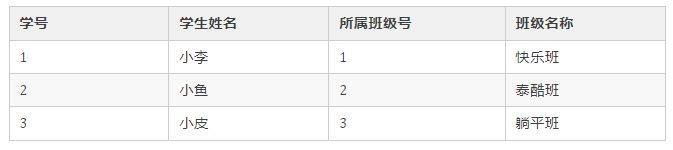
除了查询灵活、数据表间存在关系外,关系型数据库还具有很多其他的优点。
比较重要的是 数据一致性 ,关系型数据库遵循 ACID 原则(原子性、一致性、隔离性和持久性),支持事务,可以保证多个操作同时进行时,数据的状态保持一致。比如 A 给 B 转账,A 扣钱 的同时 B 也会加钱,不会出现 A 扣了钱 B 却没收到钱的情况。
兼顾查询的灵活和写入的准确性,使得关系型数据库几乎可以被应用于任何项目中!比如 CRM(客户关系管理)和 HRM(人力资源管理)等各类管理系统、数据分析系统、金融银行系统等。
比较经典的关系型数据库产品有 MySQL、Oracle、PostgreSQL、Microsoft SQL Server 等。其中,MySQL 由于开源又易学,已经成为后端开发同学必学的数据库技术。
关系型数据库的底层核心实现是 基于关系模型的数学理论 ,最常见的实现方式是使用 B+ 树来存储索引结构,基于其平衡性,能够在存储大量数据时保持高效的查询性能,并且兼顾增删改操作的性能。
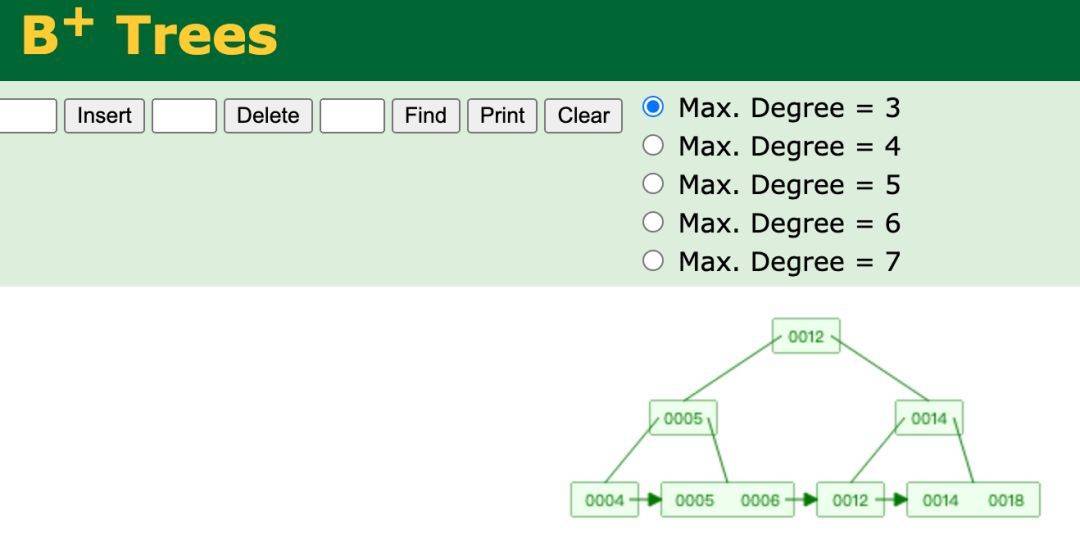
对于大多数项目,用 MySQL 等关系型数据库来存储数据就足够了。但关系型数据库不是银弹!在某些场景下,比如要存储的数据间没有关系时,它并不是最佳的选择。
举个例子,当我们要写一篇文章,没有必要把数据存储到 Excel 表格里,可能直接将单篇文本放到 word 里会更方便阅读和修改。
这个时候,我们就需要与之互补的 非关系型数据库 。
非关系型数据库又叫 NoSQL。最简单的理解方式:关系型数据库适用于存储相互之间 存在关系的数据表 ,那么非关系型数据库适用于关系不强的、结构相对灵活的、需要被快速访问的数据,比如字符串、JSON 等。
实际项目开发中,最常用的非关系型数据库当属 KV 数据库。
KV 即 Key-Value,数据是以 键值对 的方式存储在数据库中的。可以理解为一个 HashMap,数据库中存储的每个键都 唯一对应 一个值。键和值都可以是任意类型的数据,例如字符串、数字、数组等,非常灵活。
比如存储每位用户的个人信息,结构大概是这样的:
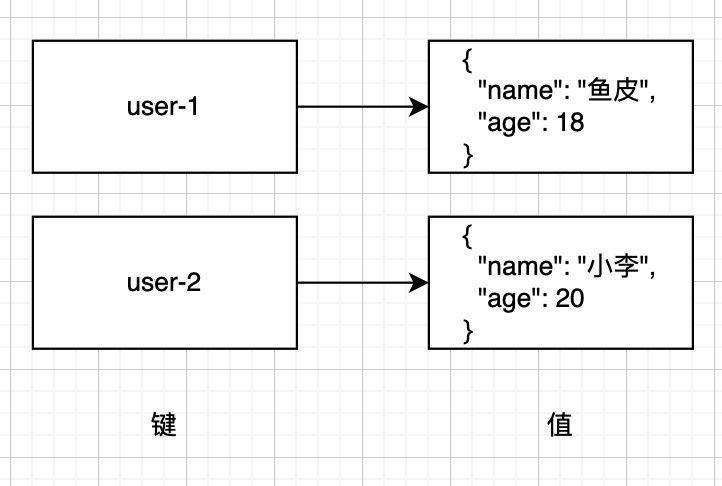
由于 KV 存储的结构简单清晰,我们能够很轻松地根据某个键查找出对应的值,无论是读写数据性能都非常高。
此外,KV 数据库还具备良好的可扩展性,由于数据间不存在直接关联,我们可以把键值对放到多个机器上存储,通过数据分片、负载均衡等策略来支持海量数据的高并发访问。
由于高性能和高可扩展性,KV 数据库被广泛应用于缓存、分布式会话、分布式锁、实时统计等场景。
最经典的 KV 数据库当属 redis 了,它是开源的、基于内存的、高性能的数据库,不仅支持丰富的数据类型和功能,还有持久化等重要特性,也是后端同学必学的技术。其他的常用 KV 数据库有 LevelDB、RocksDB、Apache Cassandra 等。
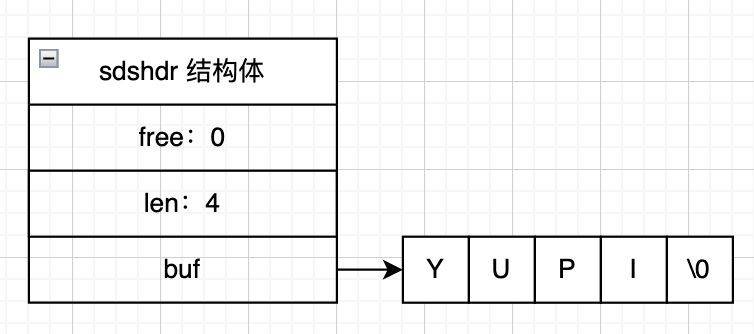
KV 数据库的底层实现比较灵活,常见的实现方式是使用哈希表来存储键值对。不同类型的值对应的实现方式也不同,比如 Redis 的字符串存储采用简单动态字符串(SDS)实现。
相信很多同学对数据库的印象就停留在 MySQL 和 Redis。的确,以上两类数据库几乎已经可以解决所有问题!
但是,未必是最适合的。
就像你完全可以用电脑自带的记事本软件来查看和编辑 html 网页文件,但是往往会选择一个更专业的开发工具来替代它。
数据库也是一样,除了传统的关系和非关系型数据库之外,还有很多用于解决特定问题的数据库。它们往往针对特定的数据结构和应用场景进行了专门的优化和设计,能够提供更高效快捷的数据查询和存储,满足特定领域的需求。
比如下面 8 种数据库:
顾名思义,搜索引擎数据库是为了实现搜索引擎功能的数据库。
它适用于存储和管理大量的文本内容数据,并提供更快速、准确、灵活的全文检索功能。
比如想要让用户更轻松地在你的博客内搜索文章,就可以使用搜索引擎数据库。
为什么它能做到更快更灵活的搜索呢?这是因为在搜索引擎数据库中,数据一般是以 倒排索引 的方式存储的。
倒排索引和传统的关系表有什么区别呢?
以存储博客文档为例,传统的关系型数据库存储结构是:
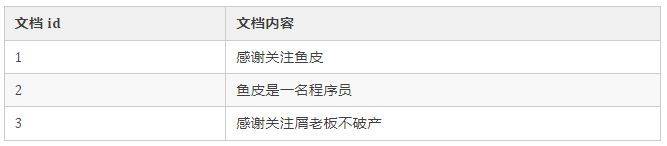
我们能够根据 id 来查找到对应的单篇文档,也可以通过搜索精确的关键词,来查找到多篇文档。
比如搜索 “鱼皮”,能搜出文档 1、2。
但是,如果你搜索 “鱼皮程序员”,是无法得到搜索结果的,因为没有任何一个文档的内容,完全包含 “鱼皮程序员” 这个词(文档内容 2 只有 “鱼皮”、“程序员” 这两个词)。
而在搜索引擎数据库中,首先会将文档内容按照单词进行分割,也就是 分词 。然后再构建单词到文档 id 的映射,示例结构如下:
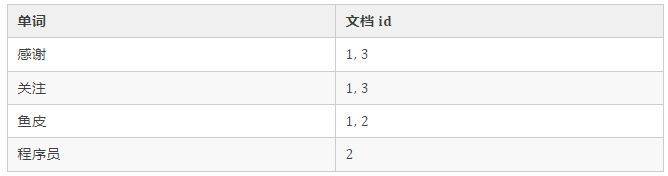
有了上述的倒排索引,当用户搜索 “鱼皮程序员” 时,搜索引擎数据库会先对搜索词进行分词,得到 “鱼皮” 和 “程序员”,然后根据这两个词汇就能找到文档 id 1、2 了。不用再去遍历表内所有的数据,实现了更灵活、快速的 模糊搜索 。
此外,搜索引擎数据库还支持 相关性排序 ,能够根据用户的搜索词对所有搜索结果进行打分,把最接近的文档排到最上面。
主流的搜索引擎数据库技术有 Elasticsearch、Apache Solr、Apache Lucene 等,一般更建议大家学习 Elasticsearch,这玩意更新迭代地老快了。
顾名思义,文档数据库适用于存储和管理 半结构化的 文档数据,比如存储 JSON 格式。
相比于关系型数据库中明确定义的表格行列,文档数据库的数据结构是类似于文档的层次化结构,每个文档都是独立的,可以包含多个不同类型和格式的数据。
比如存储博客文章,示例结构如下:

当我们要给某个文档新增一个字段时,不需要像关系型数据库一样改变表结构,非常灵活!
除了灵活之外,文档数据库也有很高的可扩展性,适用于内容管理系统(比如博客)、文档协同编辑系统等。
个人比较推荐学习的文档数据库是 MongoDB,入门难度极低,对前端同学也很友好。当然,Couchbase 也是不错的。
时序数据库是一种专门用于高效存储和处理 时间序列 的数据库系统。
时间序列是指以时间作为主要维度的数据序列,即每个数据单元都包含 时间戳。
举个例子,在实时温度监测系统中,我们需要 每分钟连续 收集并观察当前的温度,数据结构示例如下:
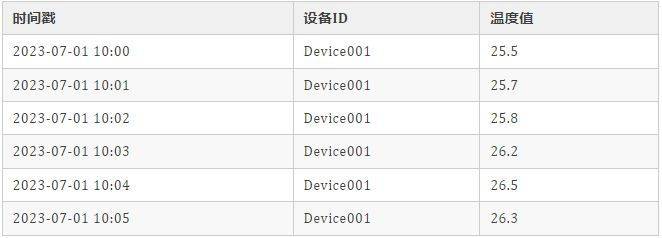
有了这些数据,我们就能够按照时间范围进行高效查询、聚合分析、数据可视化。
因此,时序数据库非常适用于物联网(比如传感器数据)、日志监控、金融交易数据分析等场景。
主流的时序数据库技术有 InfluxDB、TimescaleDB 等。一般情况下,建议将时序数据库配合 Grafana 监控看板一起使用,实现数据存储 + 快速可视化。
不同时序数据库底层的存储方式也不同,我们可以简单理解为,时序数据库会根据 时间 字段构建索引,查询时通过索引去定位实际数据。比如 InfluxDB 使用 TSM(Time-Structured Merge Tree)作为存储引擎,底层使用 B+ 树来存储时间索引。
向量数据库是专门用于存储和处理 高维向量数据 的数据库系统。
什么是向量?每个向量可以表示一个实体,并且包含多个维度的数值。
举个例子,在人脸识别系统中,我们可以通过人脸的 特征 来判断是否为熟人。每张人脸图像,都对应一个向量;每个人脸向量有可能包含成百上千个特征,比如鼻子大小、眼睛大小等,每个特征就是一个维度。
对应的数据结构示例如下:

在上述表格中,人脸特征向量是一个浮点数数组。数组的每个下标就表示一个特征(维度),比如下标 0 的数值表示鼻子的大小,下标 1 的数值表示眼睛大小,以此类推。。。
我们只需要对比向量,就能够判断出人脸的相似度。
向量数据库能够高效存储多维向量数据、计算向量的相似度、并实现各种不同算法的相似性搜索,适用于图像识别、特征提取和匹配、推荐系统等场景。值得一提的是,AI 技术的发展也带来了一波向量数据库技术的热潮,可以利用向量数据库存储投喂给 AI 的训练 Embeddings 数据。
主流的向量数据库技术有 Milvus、Pinecone、Faiss 等,有些数据库(比如 PostgreSQL)可能也支持存储向量类型的字段。
关于向量数据库的底层实现,还是比较复杂的。类似于上面提到的时序数据库,向量数据库的实现关键也是索引的设计。常见的向量索引结构有倒排索引、KD 树、球树等,可以理解为对相似的向量数据进行了分组和编码,从而实现更快速地检索匹配相似向量。此外,向量数据库往往也会采用并行计算来加速处理。
空间数据库是专门用于存储和处理 地理空间数据 的数据库系统。
地理空间数据是指基于地理 坐标系 的 几何对象 ,比如某个物体所处的经纬度或三维坐标(点)、某个物体的轮廓(线)、某个物体的表面(面)等。
举个例子,假如你想存储自己房间内每个物体的位置信息,对应的数据结构可能是:
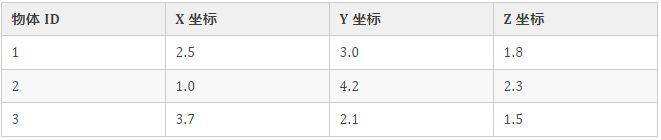
使用空间数据库,能够高效地存储、查询和分析空间数据,比如计算两个空间是否相交、对路径进行规划、可视化地理空间等。
空间数据库不仅是地理信息系统(GIS)的核心组件,还能用于实现位置导航、城市路面规划等场景。
对于具体的空间数据库技术,我了解得不多,只知道可以用 PostGIS 插件来为 PostgreSQL 支持空间数据管理能力,朋友们可以帮忙补充下。

至于空间数据库的底层实现,最关键的部分依然是索引。常见的 空间索引 结构有 R 树、Quadtree 等,这些结构可以对空间数据进行划分、聚合和编码,从而加速空间范围的查询处理。此外,空间数据库涉及大量的空间分析算法,比如最近邻查询、空间关系查询等。时间有限,不做展开说明了。
图形数据库是专门用于存储和处理 图形结构数据 的数据库系统。
注意,这里的图形可不是三角形、长方形,而是指 由节点和边构成 的图形结构。
比如我们要存储一个朋友圈关系网(即 FoF:朋友的朋友),对应的图形可能是:
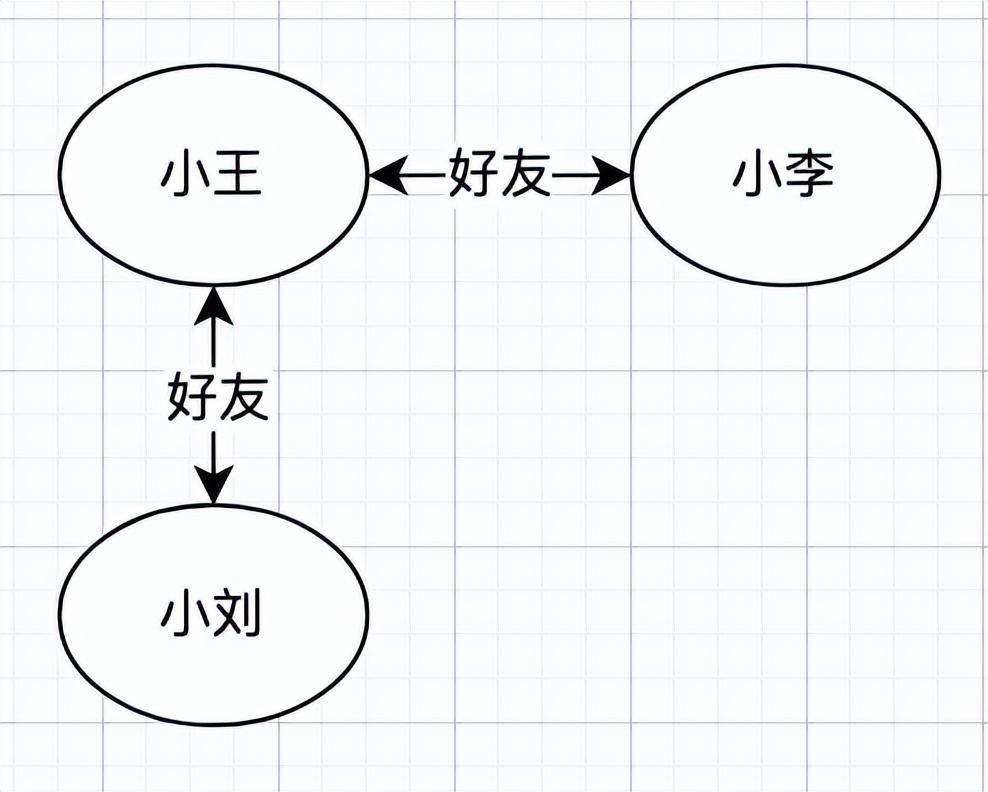
上图中,每个用户可以表示为一个节点,用户之间的好友关系可以表示为边。
在图形数据库中,需要 2 个表格来存储。
节点信息表:
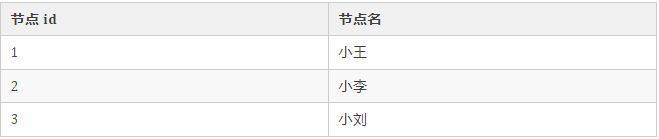
边信息表:

通过存储这些节点和边的信息,图形数据库就能实现快速 查询及分析 朋友圈网中的用户关系,并且挖掘出用户的社交情况、和其他用户的隐藏关系等。
由此,图形数据库非常适于构建社交网络关系图谱、推荐系统、知识图谱等。
比较主流的图形数据库有 Neo4j、TigerGraph 等,都支持复杂的图形操作和算法、以及分布式扩展,能够通过并行计算加速图形处理。
图形数据库的核心实现相信学过算法的朋友们并不陌生,主要是用了类似邻接表、邻接矩阵等方式实现节点和边数据的存储,并且通过构建图形索引进行加速。
这是一种 非常主流 的数据库!区别于传统的行式数据库,列存数据库以列作为基本的存储单位,把每列的数据存储在一起。
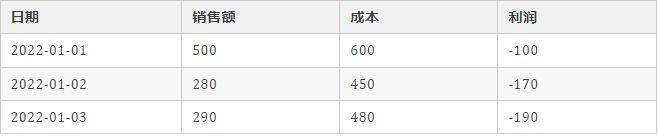
拿鱼皮公司每天的收入来举个例子,传统的行式(关系型)数据库是这么存储的:
而在列存数据库中,底层大概是这么存储的,相当于对矩阵做了一次转置:
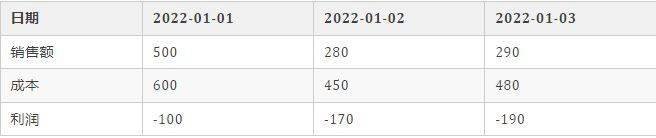
这样一来,如果我们要统计这几天公司的总利润,不需要依次读取每一行的数据,直接 读取所需 的利润那一列进行计算即可,从而提高了数据分析和聚合操作的效率。
此外,从计算机底层来分析,把相同类型的数据在同一列中连续存储,可以实现更好的数据压缩效果、节约空间。
因此,列存数据库适用于实时数据分析、OLAP、大规模数据仓库等场景。
比较主流的列存数据库技术有 Apache HBase、ClickHouse、Druid 等,都是大数据方向同学的必修课。
ClickHouse 官方演示
最后要讲的数据库也最特别,区别于上面所有存储单一数据模型的数据库,多模数据库能够 同时存储处理多种不同类型的数据 ,比如关系型数据、文档数据、图形数据等,非常灵活。
就拿大家学编程时最常做的电商系统来举例。如果没有多模数据库,你要用关系型数据库来存储商品简略信息(比如商品名称、价格),要用文档数据库来存储可能长达几十页的商品详情,要用图数据库来存储商品推荐关系。每次看数据库信息时,要分别到三个数据库中查看。
如果使用多模数据库,可以直接在同一个数据库里统一存储和管理不同类型的数据,非常方便。
此外,多模数据库还支持事务,能够更轻松地实现数据的一致性和完整性,不需要手动实现跨库事务、跨库数据同步等等。
比较常用的多模态数据库技术有 ArangoDB、OrientDB 等,不过一般情况下,我们在开发中也很少会用到这种数据库,感兴趣的话再学习即可。























