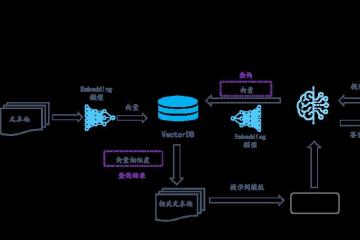
在人工智能领域,有大量的数据需要有效的处理。随着我们对人工智能应用,如图像识别、语音搜索或推荐引擎的深入研究,数据的性质变得更加复杂。这就是向量数据库发挥作用的地方。与存储标量值的传统数据库不同,向量数据库专门设计用于处理多维数据点(通常称为向量)。这些向量表示多个维度的数据,可以被认为是指向空间中特定方向和大小的箭头。

随着数字时代将我们推进到一个以人工智能和机器学习为主导的时代,向量数据库已经成为存储、搜索和分析高维数据矢量的不可或缺的工具。本文旨在全面介绍向量数据库,并介绍2023年可用的最佳向量数据库。

向量数据库是一种特殊的数据库,它以多维向量的形式保存信息。根据数据的复杂性和细节,每个向量的维数变化很大,从几个到几千个不等。这些数据可能包括文本、图像、音频和视频,使用各种过程(如机器学习模型、词嵌入或特征提取技术)将其转换为向量。
矢量数据库的主要优点是它能够根据数据的矢量接近度或相似性快速准确地定位和检索数据。这允许基于语义或上下文相关性的搜索,而不是像传统数据库那样仅仅依赖于精确匹配或设置标准。

传统数据库以表格格式存储简单的数据,然向量数据库处理称为向量的复杂数据,并使用独特的搜索方法。
常规数据库搜索精确的数据匹配,而向量数据库使用特定的相似性度量来查找最接近的匹配。向量数据库使用称为“近似最近邻”(Approximate Nearest Neighbor)搜索的特殊搜索技术,其中包括哈希和基于图的搜索等方法。
要真正理解矢量数据库是如何工作的,以及它与传统的关系数据库(如SQL)有何不同,我们必须首先理解嵌入的概念。
非结构化数据(如文本、图像和音频)缺乏预定义的格式,这给传统数据库带来了挑战。为了在人工智能和机器学习应用中利用这些数据,我们需要使用嵌入将其转换为数字表示。
嵌入就像给每一个项(无论是一个词,图像,或其他东西)一个独特的高维数字表示,捕捉其意义或本质。这段数字帮助计算机以更有效和更有意义的方式理解和比较这些项。
这种嵌入过程通常使用为该任务设计的一种特殊的神经网络来实现。例如,单词嵌入将单词转换为向量,这样具有相似含义的单词在向量空间中更接近。这种转换允许算法理解项之间的关系和相似性,设置可以针对不同的数据进行编码,比如CLIP。
从本质上讲,嵌入作为一个桥梁,将非数字数据转换为机器学习模型可以使用的形式,使它们能够更有效地识别数据中的模式和关系。


向量数据库在实现“相似性搜索”方面是非常有效率的,所以它可以用于以下一些场景:
这个列表没有特别的顺序。

Chroma是开源嵌入数据库。通过为LLM提供可插入的知识,事实和技能,使构建LLM应用程序变得容易,可以轻松地管理文本文档,将文本转换为嵌入,并进行相似度搜索。
主要特点:

Pinecone是一个可以托管向量数据库平台。也就是说有背后的而商业公司,有免费使用方案。Pinecone的主要特点包括:

Weaviate是一个开源向量数据库。它可以无缝扩展到数十亿个数据对象。Weaviate的一些关键特性是:

Faiss是一个用于快速搜索相似性和密集向量的聚类的开源库。它包含能够在不同大小的向量集中搜索的算法,甚至可以处理那些超过内存容量的向量集。此Faiss还提供了用于评估和调整参数的辅助代码。
虽然它主要是用c++编写的,但它完全支持Python/NumPy集成。它的一些关键算法也可用于GPU执行。Faiss的主要开发工作由Meta的基础人工智能研究小组承担。

Qdrant可以作为API服务运行,支持搜索最接近的高维向量。使用Qdrant,可以将嵌入或神经网络编码器转换为应用程序,用于匹配,搜索,推荐等任务。以下是Qdrant的一些关键功能:
人工智能和机器学习领域的不断发展凸显了向量数据库在当今以数据为中心的世界中的不可或缺性。这些数据库具有存储、搜索和分析多维数据向量的独特能力,在推动人工智能驱动的应用程序(从推荐系统到基因组分析)方面发挥了重要作用。
我们介绍了5个常用的向量数据库如Chroma、Pinecone、Weaviate、Faiss和Qdrant,它们每个都提供了独特的功能和创新。随着人工智能的不断发展,向量数据库在塑造数据检索、处理和分析的未来方面的作用无疑会越来越大,有望在各个领域提供更复杂、更高效、更个性化的解决方案。