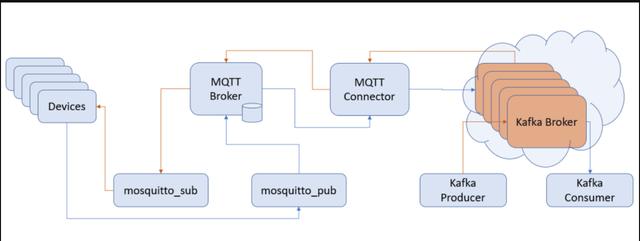
经过上次文章的铺垫,相信大家对 JAVA 的 NIO 有了一些感性的认识,也初步了解了它的 API 了,可以开始去阅读 Kafka Producer 端的发送消息的部分了。
突然想感叹一下,阅读 Kafka 这个全世界著名的开源项目,多多少少会让人赏心悦目
先大致扫一眼,发送消息的八个主流程,然后再逐个击破。
发送消息的主流程主要是在 Sender 方法里的,Sender 是一个后台线程,在构造 Producer 的时候,就已经被启动在后台运行了。所以我们主要看它的 run 方法。
run 方法是一个 while 循环,我们看里面的 run 方法。(当前位置:Sender 类)
在上一篇文章可以知道,我们已经在 KafkaProducer 类的 doSend 方法中,完成了元数据的拉取,所以这里是可以获取到元数据的了。
这个是一些容错
(1)首先我们来到这个 ready 方法里面(当前位置:RecordAccumulator)
(2)来看这一行:
boolean exhausted = this.free.queued() > 0;
free 是指 BufferPool,queued 方法:
waiters 里面是 Condition,表示是否有等待释放内存的线程,如果有,那么就是内存不足的意思。
也就是说,内存不足,exhausted 为 true,否则 为 false。
(3)遍历所有的分区和批次
拿出一个批次出来,下面开始判断是否可发送的条件:
(4)第一次发送为 false;下次重试时间到了,false;重试时间没到,true。
boolean backingOff = batch.attempts > 0 && batch.lastAttemptMs + retryBackoffMs > nowMs;
batch.attempts :表示是否尝试过了
batch.lastAttemptMs :表示分区的上次尝试时间,初始值为当前时间
retryBackOffMs :表示重试的时间间隔,默认为 100 ms
nowMs:表示当前时间
那么这句是什么意思?
这句话可能不好理解,可以假设,上次重试时间点是 10:00:00.000,重试的时间间隔是 100ms,下次重试时间是 10:00:00.100,而当前时间是 10:00:00.020,即还没到下次重试的时间。
那么 batch.lastAttemptMs + retryBackoffMs > nowMs 为 true,即还没到下次重试时间。
(5)计算出已经等待的时间
long waitedTimeMs = nowMs - batch.lastAttemptMs;
nowMs:表示当前时间
batch.lastAttemptMs:上次重试时间
waitedTimeMs:已经等待的时间
(6)等待的时间
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
retryBackoffMs :表示重试的时间间隔,默认是 100 ms
lingerMs:这个值默认是 0,即来一条发送一条。所以在生产上,一定要配置这个值,充分利用 batch 来缓存批次,避免过多和服务器的通信。
如果是第一次发送,backingOff 为 false,那么 timeToWaitMs 为 lingerMs。
(7)还需要等待多久
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
timeToWaitMs:一共需要等待的时间
waitedTimeMs:已经等待的时间
timeLeftMs:还需要等待的时间
(8)是否有批次满了
boolean full = deque.size() > 1 || batch.records.isFull();
如果队列里的批次数量大于 1,则表示已经有批次已经满了。
如果批次数量为 1,但是这个批次的消息已经满了
(9)是否超时,即已经等待的时长,是否大于一共需要等待的时长
boolean expired = waitedTimeMs >= timeToWaitMs;
(10)最后是发送条件,下面的五个条件是或的关系,任意一个满足,都可以发送
boolean sendable = full || expired || exhausted || closed || flushInProgress();
(11)如果达到了发送消息的条件,并且重试的时间到了(或者是第一次发送)
则把当前消息所在的分区的 Leader Partition 对应的主机,加到 readyNodes 数据结构中来
if (sendable && !backingOff) {
readyNodes.add(leader);
}
至此,已经找到了需要发送消息的主机,那么接下来就是建立到这台主机的连接。
到建立网络连接的时候,看到这段代码:
可以看到具体的实现是在 NetwordClient 里面
第一个条件就是发送消息不能是在更新元数据的时候;
第二个条件点进去:
发现这边有个核心的对象,selector,它是 NetworkClient 里的一个属性。(NetworkClient 是 Kafka 网络连接的一个很重要的对象!):
我们再点进去,找它的实现类,Selector:
可以看到有两个核心属性,第一个 nIOSelector 就是对于 Java 的 Nio 的封装。
第二个是一个 Map,Map 的 key 是 broker 的编号,value 是 KafkaChannel,KafkaChannel 可以理解为是 SocketChannel。
好,然后再继续看一下 KafkaChannel:
最终,如下图所示:
我们从第四步的代码开始看:
第一个条件,表示是否建立好了连接,如果建立好了,会在 nodeState 的结构中缓存起来的。
第二个条件:通道是否准备好了:
第三个条件:
max.in.flight.requests.per.connection
这个参数,是在初始化 NetworkClient 对象的时候,传递进来的,默认值是 5.
表示最多默认有多少次请求没有得到服务端的响应。
这里第三个条件,就是说,是否小于 5 个请求发送出去了,没有得到响应。
但现在我们是第一次判断与主机的网络是否连接好,网络肯定是没有建立好的,所以这个方法会返回 false。
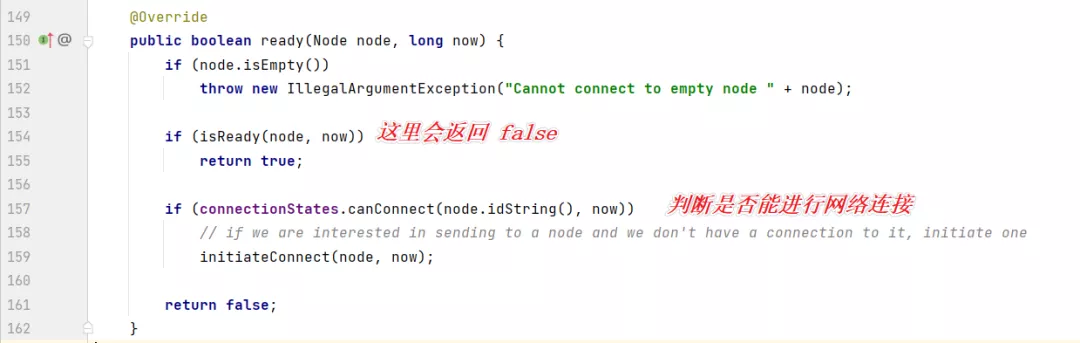

然后就开始初始化网络连接了:
这里连接的代码和平时写的 Java NIO 的代码是一样的
socket.setTcpNoDelay(true);
注意,他这里有一句这个代码,这个默认值是 false,意思是它会把网络中的一些小的数据包收集起来,组合成一个大的数据包然后再发送出去。
它认为如果网络中有大量小的数据包,会影响网络拥塞。
所以这里,一定是要把它设置为 true 的。因为有时候,数据包就是比较小,这里不帮我们发送,明细是不合适的。
这里,建立网络连接,最终往 selector 上绑定了一个 OP_CONNECT 事件,和我们平时写的代码是一样的。
最终这个方法返回了 false:
那么回到主流程上,返回 false 之后,这些主机都会被移除。
然后是步骤七,创建一个请求。
最后执行到这里:
点进去看,核心代码在这里:
继续往里面看,核心代码在这里:
点进去:
再点进去,(当前位置:PlaintextTransportLayer)
这里,如果已经连接网络了,则移除 OP_CONNECT 事件,并且增加 OP_READ 事件,这样的话,就可以读取到 服务端发送回来的响应了。
到这里位置,第一遍就建立好了网络连接。
刚刚我们第一遍执行,建立好了网络连接,现在开始第二次执行
这里网络已经准备好了,所以 if 的方法不执行,节点也不会被移除了
这个时候是可以合并批次的,因为这个 nodes 不为空
然后创建一个请求,并且发送这个请求:
点进去:
在点进去 send 方法里,这里有一个很重要的操作,绑定了 OP_WRITE 事件
绑定了 OP_WRITE 事件,才能把数据发送出去!!
现在我们再退回到 这个方法:
点到 poll 方法里来:
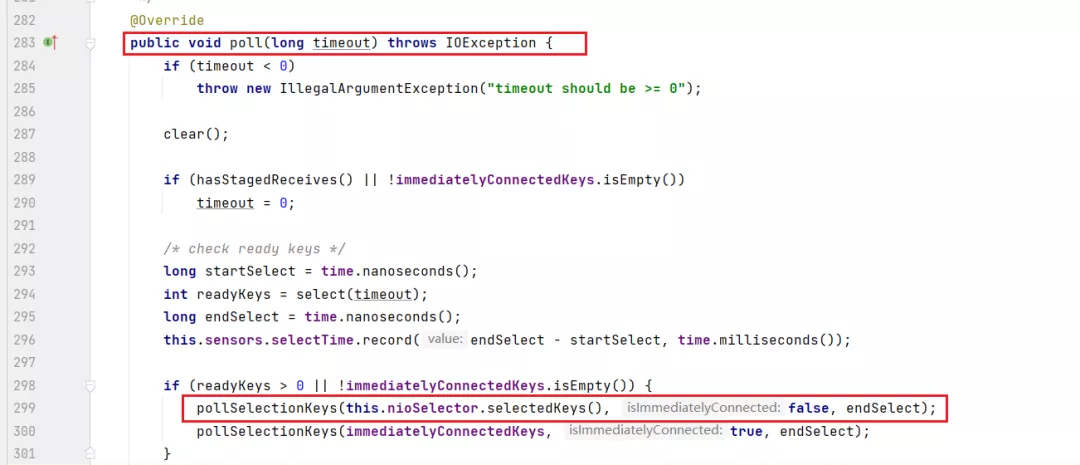
然后这里会从 selector 上拿到 SelectionKey,如果是写事件:
点到 send 方法里来:
把消息写出去,并且移除 OP_WRITE 事件。
我们可以想到,客户端发送出去的肯定是多个请求,那么服务端返回的也是多个请求,那客户端如何从响应中解析出这多个请求呢?这就是拆包处理。
比如,服务端返回的响应是这样的:
响应成功响应失败
我们要拆分成:
响应成功
响应失败
但是,由于网络原因,返回的可能是这样的
响应成
功响应失败
也就是分两次发回给客户端
客户端该如何处理?
Kafka 是在响应消息的前面加上了每个响应的长度编码
40响应成功30响应失败
那这个长度会发生拆包吗?也很简单,申请一定长度的字节,比如2个字节来存长度,把这个2字节的长度满了,就是长度了。
等到读满了2字节,就转换成 int 类型,再申请这个 int 类型长度的内存,再去接收这么多长度的字节,一直到读满为止。
然后来看看 Kafka 的代码如何处理的,看到 poll 方法里处理 OP_READ 的方法的部分
最终,拆包和粘包的代码:
size.hasRemaining, size 是一个 4 字节的 ByteBuffer
然后开始读4个字节的数据
int bytesRead = channel.read(size);
读取完了之后,再看有没有剩余空间了,如果读满了,那么把这个4字节的数变成一个 int 值,并且继续分配这个 int 值大小的 ByteBuffer
if (!size.hasRemaining()) {
size.rewind();
int receiveSize = size.getInt();
if (receiveSize < 0)
throw new InvalidReceiveException("Invalid receive (size = " + receiveSize + ")");
if (maxSize != UNLIMITED && receiveSize > maxSize)
throw new InvalidReceiveException("Invalid receive (size = " + receiveSize + " larger than " + maxSize + ")");
this.buffer = ByteBuffer.allocate(receiveSize);
}
然后一直读取内容:
if (buffer != null) {
int bytesRead = channel.read(buffer);
if (bytesRead < 0)
throw new EOFException();
read += bytesRead;
}
然后再来看:
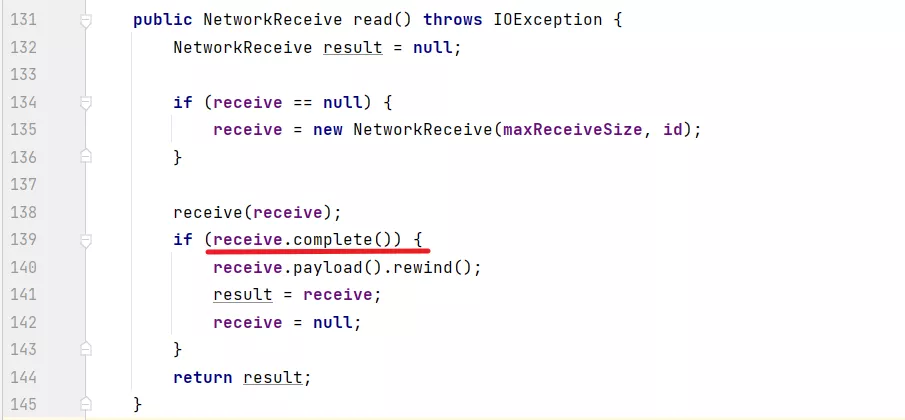
这个 complete 方法,是判断 size 已经读满了,并且 内容也已经读满了,那么就表示读取到了一个完整的响应了。
那么这就是完整的拆包和粘包的处理了,大概也就是20行代码,也是很精彩的。
本次我们完整的看了 Sender 线程发送消息的完整过程,里面包括了 Kafka 如何封装 Java NIO 代码,并且合理的建立连接,绑定 OP_READ,OP_WRITE 事件,并且读取服务端的响应,代码质量还是非常高的,看起来也是赏心悦目。
希望大家对着源码再好好看一遍,一定会有收货的。