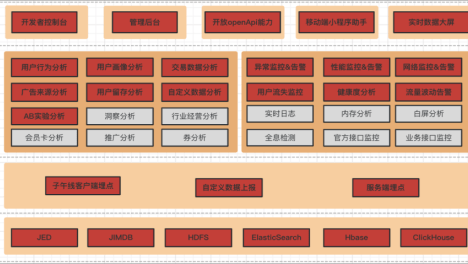
每次数据中心中断都代价高昂。随着数字化步伐的加快,维持正常运行时间的压力极具挑战性。考虑到数据中心负载的增加,仅靠人类来处理由于复杂性的增加而产生的大量问题已经不可能了。如今,IT运营团队比以往任何时候都更需要管理复杂的IT基础设施。再加上不断增长的数据量,使得IT团队的任务更加难以管理当今动态的、不断变化的IT环境。这增加了中断的可能性。

虽然有许多技术进步,但中断很常见,且还在增加。Uptime Institute的2022年年度中断分析报告强调,五分之一的组织报告在过去三年中经历了“严重”或“严重”中断,涉及重大财务损失、声誉损害、合规违规,在某些严重情况下,还会造成人员伤亡,这标志着重大中断的发生率略有上升趋势。根据Uptime的2022年数据中心弹性调查,80%的数据中心经理和运营商在过去三年中经历过某种类型的中断,比正常情况略有增加,在70%到80%之间波动。超过60%的数据中心失败导致至少10万美元的总损失,远高于2019年的39%。在同一时期,损失超过100万美元的中断所占比例从11%上升到15%。
数据中心中断的原因
中断的原因各不相同。从网络故障到硬件或软件故障,再到断电、网络攻击和人为错误,导致数据中心中断的原因有很多。
下面来看看服务中断的主要原因,并推荐最佳实践来缓解这些问题:
防止中断的最佳实践
弹性是数据中心的一个关键属性,每个企业都必须努力通过一系列举措来防止中断。首先,组织必须定期分析数据中心生态系统的每个重要组成部分的弹性,如电源、冷却、连接、服务提供商。数据中心温度与数据中心设备故障有直接关系。因此,监测温度对于防止任何可能的故障或设备关闭变得极其重要。
UPS系统的故障也可能导致中断。由于大多数UPS系统在电源故障之前都没有进行真正的测试,因此对UPS系统的一致远程监控有助于提供实时警报,并在潜在问题导致中断之前向管理员发出警报。
软件故障也可能导致中断和停机。因此,有必要定期更新软件和打补丁。为了确保定期更新补丁,人工智能可用于扫描漏洞,并在需要时进行软件更新或补丁。AI还可用于主动识别与数据中心设备或应用程序性能或安全相关的问题。
通过结合使用主动网络监控和使用自动化将人为错误的可能性降至最低,可以防止与网络相关的中断。网络冗余也是可取的,这意味着如果一个网络出现故障,可以使用不同服务提供商的替代网络。
理想情况下,雇佣第三方服务提供商,可以对弹性进行审计,并提供独立的、无偏见的评估,以理解和对标弹性。选择正确的DR流程还可以帮助快速从中断中恢复。
为了确保免受勒索软件的攻击,企业必须减少用户权限,消除任何终端用户管理员,并使用多因素身份验证(MFA),因为这极大地限制了攻击者横向移动的机会。网络分割可以减少攻击向量,而基于策略隔离的用户端点检测和响应(EDR)解决方案的实现可以帮助防止恶意软件的传播。研究表明,许多数据中心的中断是完全可以预防和避免的。如果组织投资于正确的设备、技术和流程,则可以避免大多数中断的发生。