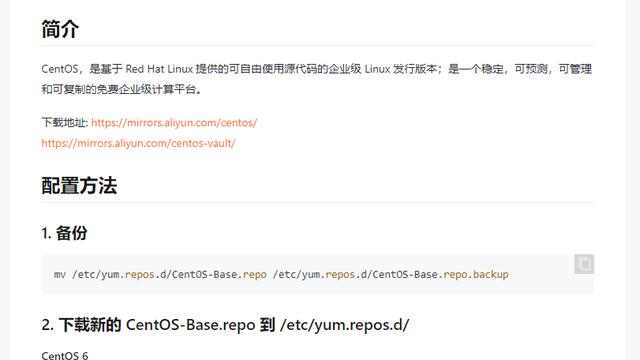
一、4大具有代表性的并发模型及其优缺点
4大具有代表性的并发模型:Apache模型(Process Per Connection,简称PPC),TPC(Thread PerConnection)模型,select模型和poll模型、Epoll模型。
Apache(PPC)模型和TPC模型是最容易理解的,Apache模型在并发上是通过多进程实现的,而TPC模型是通过多线程实现的,但是这2种方式在大量进程/线程切换时会造成大量的开销。
select模型是通过一种轮询机制来实现的。需要注意select模型有3大不足:
a.Socket文件数量限制:该模式可操作的Socket数由FD_SETSIZE决定,内核默认32*32=1024.
b.操作限制:通过遍历FD_SETSIZE(1024)个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍,这样效率就会随文件数量的增多呈现线性下降,把FD_SETSIZE改大的后果就是遍历需要更久的时间。管理文件数量和管理效率成反比。
c.内存复制限制:内核/用户空间的信息交换是通过内存拷贝来完成的,这样在高并发情况下就会存在大量的数据拷贝,浪费时间。
poll模型与select类似,也是通过轮询来实现,但它与select模型的区别在于Socket数量没有限制,所以poll模型有2大不足:操作限制和内存复制限制。
Epoll模型改进了poll和sellect模型。Epoll没有文件数量限制,上限是当前用户单个进程最大能打开的文件数;使用事件驱动,不使用轮询,而使用基于内核提供的反射模式。有“活跃Socket”时,内核访问该Socket的callback,直接返回产生事件的文件句柄;内核/用户空间信息交换通过共享内存mmap实现,避免了数据复制。
目前市场用得比较多的就是Apache、Nginx、Lighttpd. Apache的占有率是最高是毋庸置疑的,但它主要是采用select模式开发。当前主流的异步web服务器Lighttpd和Nginx都是基于Epoll的。它们具有非常好的架构,可以运行在简单的web集群中。但在数据结构、内存管理都多个细节方面处理nginx考虑更加完善。nginx从event、跨平台、基础数据结构都很多细节方面进行了考虑和优化。nginx必定是未来的apache,未来的主流。
二、主机环境对高并发应用程序的天然限制
高并发的应用程序至少需要考虑3大限制条件:用户进程的默认内存空间为4G,线程栈默认为8M,用户进程最大能管理的文件描述符默认为1024个,网卡对客户端端口号数量的限制。
linux下高并发socket服务器端和客户端最大连接数所受的限制问题(修改软限制和硬限制)
1、配置用户进程可打开的最多文件数量的限制
在Linux平台上,无论编写客户端程序还是服务端程序,在进行高并发TCP连接处理时,最高的并发数量都要受到系统对用户单一进程同时可打开文件数量的限制(这是因为系统为每个TCP连接都要创建一个socket句柄,每个socket句柄同时也是一个文件句柄)。可使用ulimit命令查看系统允许当前用户进程打开的文件数限制:[speng@as4 ~]$ ulimit -n1024 #系统默认对某一个用户打开文件数的用户软限制是1024,用户硬限制是4096个
这表示当前用户的每个进程最多允许同时打开1024个文件,这1024个文件中还得除去每个进程必然打开的标准输入,标准输出,标准错误,服务器监听 socket,进程间通讯的unix域socket等文件,那么剩下的可用于客户端socket连接的文件数就只有大概1024-10=1014个左右。也就是说缺省情况下,基于Linux的通讯程序最多允许同时1014个TCP并发连接。
如果想支持更高数量的TCP并发连接的通讯处理程序,就必须修改Linux对当前用户的进程同时打开的文件数量的软限制(soft limit)和硬限制(hardlimit)。其中软限制是指Linux在当前系统能够承受的范围内进一步限制用户同时能打开的文件数;硬限制则是根据系统硬件资源状况(主要是系统内存)计算出来的系统最多可同时打开的文件数量。通常软限制小于或等于硬限制。修改上述限制的最简单的办法就是使用ulimit命令:[speng@as4 ~]$ ulimit -n 100 #(只能设置比当前soft限制更小的数)上述命令中,指定要设置的单一进程允许打开的最大文件数。如果系统回显类似于"Operation notpermitted"之类的话,说明上述限制修改失败,实际上是因为在此指定的数值超过了Linux系统对该用户打开文件数的软限制或硬限制。因此,就需要修改Linux系统对用户的关于打开文件数的软限制和硬限制。如果需要设置比当前软限制和硬限制更大的数,只能修改配置文件,步骤如下:
第一步,修改/etc/security/limits.conf文件,在文件中添加如下行:speng soft nofile 10240speng hard nofile 10240其中speng指定了要修改的用户的用户名,可用'*'号表示修改所有用户的限制;soft或hard指定要修改软限制还是硬限制;10240则指定了想要修改的新的限制值,即最大打开文件数(请注意软限制值要小于或等于硬限制)。修改完后保存文件。
第二步,修改/etc/pam.d/login文件,在文件中添加如下行:session required
/lib/security/pam_limits.so 这是告诉Linux在用户完成系统登录后,应该调用pam_limits.so模块来设置系统对该用户可使用的各种资源数量的最大限制(包括用户可打开的最大文件数限制),而pam_limits.so模块就会从/etc/security/limits.conf文件中读取配置来设置这些限制值。修改完后保存此文件。
第三步,查看Linux系统级的最大打开文件数限制-硬限制,使用如下命令:[speng@as4 ~]$ cat
/proc/sys/fs/file-max12158这表明这台Linux系统最多允许同时打开(即包含所有用户打开文件数总和)12158个文件,是Linux系统级硬限制,所有用户级的打开文件数限制都不应超过这个数值。通常这个系统级硬限制是Linux系统在启动时根据系统硬件资源状况计算出来的最佳的最大同时打开文件数限制,如果没有特殊需要,不应该修改此限制,除非想为用户级打开文件数限制设置超过此限制的值。修改此硬限制的方法是修改/etc/rc.local脚本,在脚本中添加如下行:echo 22158 > /proc/sys/fs/file-max这是让Linux在启动完成后强行将系统级打开文件数硬限制设置为22158.修改完后保存此文件。
第四步,完成上述步骤后重启系统,一般情况下就可以将Linux系统对指定用户的单一进程允许同时打开的最大文件数限制设为指定的数值。如果重启后用 ulimit-n命令查看用户可打开文件数限制仍然低于上述步骤中设置的最大值,这可能是因为在用户登录脚本/etc/profile中使用ulimit -n命令已经将用户可同时打开的文件数做了限制。由于通过ulimit-n修改系统对用户可同时打开文件的最大数限制时,新修改的值只能小于或等于上次 ulimit-n设置的值,因此想用此命令增大这个限制值是不可能的。所以,如果有上述问题存在,就只能去打开/etc/profile脚本文件,在文件中查找是否使用了ulimit-n限制了用户可同时打开的最大文件数量,如果找到,则删除这行命令,或者将其设置的值改为合适的值,然后保存文件,用户退出并重新登录系统即可。 通过上述步骤,就为支持高并发TCP连接处理的通讯处理程序解除关于打开文件数量方面的系统限制。
2、修改网络内核对TCP连接的有关限制
在Linux上编写支持高并发TCP连接的客户端通讯处理程序时,有时会发现尽管已经解除了系统对用户同时打开文件数的限制,但仍会出现并发TCP连接数增加到一定数量时,再也无法成功建立新的TCP连接的现象。出现这种现在的原因有多种。
第一种原因可能是因为Linux网络内核对本地端口号范围有限制(客户端能使用的端口号限制)。此时,进一步分析为什么无法建立TCP连接,会发现问题出在connect()调用返回失败,查看系统错误提示消息是"Can't assign requestedaddress".同时,如果在此时用tcpdump工具监视网络,会发现根本没有TCP连接时客户端发SYN包的网络流量。这些情况说明问题在于本地Linux系统内核中有限制。其实,问题的根本原因在于Linux内核的TCP/IP协议实现模块对系统中所有的客户端TCP连接对应的本地端口号的范围进行了限制(例如,内核限制本地端口号的范围为1024~32768之间)。当系统中某一时刻同时存在太多的TCP客户端连接时,由于每个TCP客户端连接都要占用一个唯一的本地端口号(此端口号在系统的本地端口号范围限制中),如果现有的TCP客户端连接已将所有的本地端口号占满(端口耗尽),因此系统会在这种情况下在connect()调用中返回失败,并将错误提示消息设为"Can't assignrequested address".有关这些控制逻辑可以查看Linux内核源代码,以linux2.6内核为例,可以查看tcp_ipv4.c文件中如下函数:static int tcp_v4_hash_connect(struct sock *sk)请注意上述函数中对变量sysctl_local_port_range的访问控制。变量sysctl_local_port_range的初始化则是在tcp.c文件中的如下函数中设置:void __init tcp_init(void)内核编译时默认设置的本地端口号范围可能太小,因此需要修改此本地端口范围限制,方法为
第一步,修改/etc/sysctl.conf文件,在文件中添加如下行:
net.ipv4.ip_local_port_range = 1024 65000这表明将系统对本地端口范围限制设置为1024~65000之间。请注意,本地端口范围的最小值必须大于或等于1024;而端口范围的最大值则必须<=65535.修改完后保存此文件。
第二步,执行sysctl命令:[speng@as4 ~]$ sysctl -p如果系统没有错误提示,就表明新的本地端口范围设置成功。如果按上述端口范围进行设置,则理论上单独一个进程最多可以同时建立60000多个TCP客户端连接。
第二种无法建立TCP连接的原因可能是因为Linux网络内核的IP_TABLE防火墙对最大跟踪的TCP连接数有限制。此时程序会表现为在 connect()调用中阻塞,如同死机,如果用tcpdump工具监视网络,也会发现根本没有TCP连接时客户端发SYN包的网络流量。由于 IP_TABLE防火墙在内核中会对每个TCP连接的状态进行跟踪,跟踪信息将会放在位于内核内存中的conntrackdatabase中,这个数据库的大小有限,当系统中存在过多的TCP连接时,数据库容量不足,IP_TABLE无法为新的TCP连接建立跟踪信息,于是表现为在connect()调用中阻塞。此时就必须修改内核对最大跟踪的TCP连接数的限制,方法同修改内核对本地端口号范围的限制是类似的:
第一步,修改/etc/sysctl.conf文件,在文件中添加如下行:net.ipv4.ip_conntrack_max = 10240这表明将系统对最大跟踪的TCP连接数限制设置为10240.请注意,此限制值要尽量小,以节省对内核内存的占用。
第二步,执行sysctl命令:[speng@as4 ~]$ sysctl -p如果系统没有错误提示,就表明系统对新的最大跟踪的TCP连接数限制修改成功。如果按上述参数进行设置,则理论上单独一个进程最多可以同时建立10000多个TCP客户端连接。
三、高并发采用的IO访问方案
使用支持高并发网络I/O的编程技术在Linux上编写高并发TCP连接应用程序时,必须使用合适的网络I/O技术和I/O事件分派机制。可用的I/O技术有同步I/O(当前I/O访问完成再进行下一次访问),非阻塞式同步I/O(也称反应式I/O,select,poll,epoll实现),以及异步I/O.在高TCP并发的情形下,如果使用同步I/O,这会严重阻塞程序的运转,除非为每个TCP连接的I/O创建一个线程。但是,过多的线程又会因系统对线程的调度造成巨大开销。因此,在高TCP并发的情形下使用同步 I/O是不可取的.
这时可以考虑使用非阻塞式同步I/O或异步I/O.非阻塞式同步I/O的技术包括使用select(),poll(),epoll等机制。异步I/O的技术就是使用AIO. 从I/O事件分派机制来看,使用select()是不合适的,因为它所支持的并发连接数有限(通常在1024个以内)。如果考虑性能,poll()也是不合适的,尽管它可以支持的较高的TCP并发数,但是由于其采用"轮询"机制,当并发数较高时,其运行效率相当低,并可能存在I/O事件分派不均,导致部分TCP连接上的I/O出现"饥饿"现象。而如果使用epoll或AIO,则没有上述问题(早期Linux内核的AIO技术实现是通过在内核中为每个 I/O请求创建一个线程来实现的,这种实现机制在高并发TCP连接的情形下使用其实也有严重的性能问题。但在最新的Linux内核中,AIO的实现已经得到改进)。
综上所述,在开发支持高并发TCP连接的Linux应用程序时,应尽量使用epoll或AIO技术来实现并发的TCP连接上的I/O控制,这将为提升程序对高并发TCP连接的支持提供有效的I/O保证。
epoll是Linux内核为处理大批量文件描述符而作了改进的poll,是Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。另一点原因就是获取事件的时候,它无须遍历整个被侦听的描述符集,只要遍历那些被内核IO事件异步唤醒而加入Ready队列的描述符集合就行了。epoll除了提供select/poll那种IO事件的水平触发(Level Triggered)外,还提供了边缘触发(Edge Triggered),这就使得用户空间程序有可能缓存IO状态,减少epoll_wait/epoll_pwait的调用,提高应用程序效率。
1.为什么是epoll,而不是select?
(1)epoll支持在一个用户进程内打开最大系统限制的文件描述符select 最不能忍受的是一个进程所打开的FD是有一定限制的,由FD_SETSIZE设置,默认值是1024。对于那些需要支持的上万连接数目的IM服务器来说显然太少了。这时候一般有2种选择:一是可以选择修改这个宏然后重新编译内核,不过资料也同时指出这样会带来网络效率的下使用epoll进行高性能网络编程 降,二是可以选择多进程的解决方案(传统的Apache方案),不过虽然linux上面创建进程的代价比较小,但仍旧是不可忽视的,加上进程间数据同步远比不上线程间同步的高效,所以也不是一种完美的方案。不过 epoll则没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max查看,一般来说这个数目和系统内存关系很大。
(2)epoll的IO读取效率不随FD数目增加而线性下降传统的select/poll另一个致命弱点就是当你拥有一个很大的socket集合,不过由于网络延时,任一时间只有部分的socket是“活跃”的,但是select/poll每次调用都会线性扫描全部的集合,导致效率呈现线性下降。但是epoll不存在这个问题,它只会对“活跃”的socket进行操作---这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的。那么,只有“活跃”的socket才会主动的去调用 callback函数,其他idle状态socket则不会,在这点上,epoll实现了一个“伪”AIO,因为这时候推动力在os内核。在一些 benchmark中,如果所有的socket基本上都是活跃的---比如一个高速LAN环境,epoll并不比select/poll有什么效率,相反,如果过多使用epoll_ctl,效率相比还有稍微的下降。但是一旦使用idle connections模拟WAN环境,epoll的效率就远在select/poll之上了。传统的select以及poll的效率会因为在线人数的线形递增而导致呈二次乃至三次方的下降,这些直接导致了网络服务器可以支持的人数有了个比较明显的限制。select/poll线性扫描文件描述符,epoll事件触发
(3)epoll使用mmap加速内核与用户空间的消息传递(文件描述符传递)这点实际上涉及到epoll的具体实现了。无论是select,poll还是epoll都需要内核把FD消息通知给用户空间,如何避免不必要的内存拷贝就很重要,在这点上,epoll是通过内核与用户空间mmap同一块内存实现的。
(4)epoll有2种工作方式epoll有2种工作方式:LT和ET。LT(level triggered电平触发)是缺省的工作方式,并且同时支持block和no-block socket(阻塞和非阻塞).在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的fd进行IO操作。如果你不作任何操作,内核还是会继续通知你的(如果你不作任何操作,会通知多次),所以,这种模式编程出错误可能性要小一点。传统的select/poll都是这种模型的代表。ET (edge-triggered边缘触发)是高速工作方式,只支持no-block socket。在这种模式下,当描述符从未就绪变为就绪时,内核通过epoll告诉你。然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知(无论如何,只通知一次),直到你做了某些操作导致那个文件描述符不再为就绪状态了(比如,你在发送,接收或者接收请求,或者发送接收的数据少于一定量时导致了一个EWOULDBLOCK 错误)。但是请注意,如果一直不对这个fd作IO操作(从而导致它再次变成未就绪),内核不会发送更多的通知(only once),不过在TCP协议中,ET模式的加速效用仍需要更多的benchmark确认。ET和LT的区别就在这里体现,LT事件不会丢弃,而是只要读buffer里面有数据可以让用户读或写buffer为空,则不断的通知你。而ET则只在事件发生之时通知。可以简单理解为LT是水平触发,而ET则为边缘触发。LT模式只要有事件未处理就会触发,而ET则只在高低电平变换时(即状态从1到0或者0到1)触发。综上所述,epoll适合管理百万级数量的文件描述符。
2.epoll相关的系统调用总共不过3个API:epoll_create, epoll_ctl, epoll_wait。
(1)int epoll_create(int maxfds) 创建一个epoll的句柄,返回新的epoll设备句柄。在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。int epoll_create1(int flags)是int epoll_create(int maxfds) 的变体,已将maxfds废弃不用。flags只有2种取值:flags=0表示epoll_create(int maxfds) 一样,文件数上限应该是系统用户进程的软上限;flags=EPOLL_CLOEXEC 表示在新打开的文件描述符里设置 close-on-exec (FD_CLOEXEC) 标志。相当于先调用pfd=epoll_create,在使用fcntl设置pfd的FD_CLOEXEC选项。意思是在使用execl产生的子进程里面,将此描述符关闭,不能再使用它,但是在使用fork调用的子进程中,此描述符并不关闭,仍可使用。
(2)int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event) epoll的事件注册函数,返回0表示设置成功。第一个参数是epoll_create()的返回值。第二个参数表示动作,用三个宏来表示:EPOLL_CTL_ADD:注册新的fd到epfd中;EPOLL_CTL_MOD:修改已经注册的fd的监听事件;EPOLL_CTL_DEL:从epfd中删除一个fd;第三个参数是需要监听的fd。第四个参数是告诉内核需要监听什么事,struct epoll_event结构如下:typedef union epoll_data { void *ptr; int fd; __uint32_t u32; __uint64_t u64;} epoll_data_t; //感兴趣的事件和被触发的事件struct epoll_event { __uint32_t events; /* Epoll events */ epoll_data_t data; /* User data variable */};epoll能监控的文件描述符的7个events可以是以下7个宏的集合:EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);EPOLLOUT:表示对应的文件描述符可以写;EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);EPOLLERR:表示对应的文件描述符发生错误;EPOLLHUP:表示对应的文件描述符被挂断;EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于电平触发(Level Triggered)来说的。如果不设置则为电平触发。EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
(3)int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);收集在epoll监控的事件中已经发生的事件,返回发生的事件个数。参数events是分配好的epoll_event结构体数组,epoll将会把发生的事件赋值到events数组中(events不可以是空指针,内核只负责把数据复制到这个events数组中,不会去帮助我们在用户态中分配内存)。maxevents告之内核这个events数组有多大,这个 maxevents的值不能大于创建epoll_create()时的maxfds。参数timeout是epoll_wait超时时间毫秒数,0会立即返回非阻塞,-1永久阻塞。如果函数调用成功,返回对应I/O上已准备好的文件描述符数目,如返回0表示已超时。 Linux-2.6.19又引入了可以屏蔽指定信号的epoll_wait: epoll_pwait
。3.epoll的使用过程
(1)首先通过kdpfd=epoll_create(int maxfds)来创建一个epoll的句柄,其中maxfds为你epoll所支持的最大句柄数。这个函数会返回一个新的epoll句柄,之后的所有操作将通过这个句柄来进行操作。在用完之后,记得用close()来关闭这个创建出来的epoll句柄。
(2)之后在你的网络主循环里面,每一帧的调用epoll_wait(int epfd, epoll_event *events, int max events, int timeout)来查询所有的网络接口,看哪一个可以读,哪一个可以写了。基本的语法为: nfds=epoll_wait(kdpfd,events,maxevents,-1); 其中kdpfd为用epoll_create创建之后的句柄,events是一个epoll_event*的指针,当epoll_wait这个函数操作成功之后,epoll_events里面将储存所有的读写事件。maxevents是最大事件数量。最后一个timeout是epoll_wait的超时,为0的时候表示马上返回,为-1的时候表示一直等下去,直到有事件发生,为任意正整数的时候表示等这么长的时间,如果一直没有事件,则返回。一般如果网络主循环是单独的线程的话,可以用-1来等,这样可以保证一些效率,如果是和主逻辑在同一个线程的话,则可以用0来保证主循环的效率。
epoll_wait范围之后应该是一个循环,遍历所有的事件:
while(true)
{
nfds = epoll_wait(epfd,events,20,500);
for(n=0;n<nfds;++n)
{
if(events[n].data.fd==listener)
{ //如果是主socket的事件的话,则表示
//有新连接进入了,进行新连接的处理。
client=accept(listener,(structsockaddr*)&local,&addrlen);
if(client<0) //在此最好将client设置为非阻塞
{ perror("accept"); continue; }
setnonblocking(client);//将新连接置于非阻塞模式
ev.events=EPOLLIN|EPOLLET; //并且将新连接也加入EPOLL的监听队列。注意: 并没有设置对写socket的监听
ev.data.fd=client;
if(epoll_ctl(kdpfd,EPOLL_CTL_ADD,client,&ev)<0)
{ //设置好event之后,将这个新的event通过epoll_ctl加入到epoll的监听队列里面, 这里用EPOLL_CTL_ADD来加一个新的epoll事件,通过EPOLL_CTL_DEL来减少一个 ,epoll事件,通过EPOLL_CTL_MOD来改变一个事件的监听方式。 fprintf(stderr,"epollsetinsertionerror:fd=%d0,client); return-1;
}
}
elseif(event[n].events&EPOLLIN) { //如果是已经连接的用户,并且收到数据, 那么进行读入
int sockfd_r;
if((sockfd_r=event[n].data.fd)<0)
continue;
read(sockfd_r,buffer,MAXSIZE);
//修改该sockfd_r上要处理的事件为EPOLLOUT,这样可以监听写缓存是否可写,直到可写时才写入数据
ev.data.fd=sockfd_r;
ev.events=EPOLLOUT|EPOLLET;
epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd_r,&ev) );//修改标识符,等待下一个循环时发送数据,异步处理的精髓 }
elseif(event[n].events&EPOLLOUT) //如果有数据发送
{
intsockfd_w=events[n].data.fd;
write(sockfd_w,buffer,sizeof(buffer)); //修改sockfd_w上要处理的事件为EPOLLIN ev.data.fd=sockfd_w;
ev.events=EPOLLIN|EPOLLET;
epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd_w,&ev) //修改标识符,等待下一个循环时接收数据 }
do_use_fd(events[n].data.fd);
}
}
epoll实例:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
#include <sys/socket.h>
#include <netdb.h>
#include <fcntl.h>
#include <sys/epoll.h>
#include <string.h>
#define MAXEVENTS 64
//函数:
//功能:创建和绑定一个TCP socket
//参数:端口
//返回值:创建的socket
static int create_and_bind (char *port)
{
struct addrinfo hints;
struct addrinfo *result, *rp;
int s, sfd;
memset (&hints, 0, sizeof (struct addrinfo));
hints.ai_family = AF_UNSPEC; /* Return IPv4 and IPv6 choices */
hints.ai_socktype = SOCK_STREAM; /* We want a TCP socket */
hints.ai_flags = AI_PASSIVE; /* All interfaces */
s = getaddrinfo (NULL, port, &hints, &result);//getaddrinfo解决了把主机名和服务名转换成套接口地址结构的问题。
if (s != 0)
{
fprintf (stderr, "getaddrinfo: %sn", gai_strerror (s));
return -1;
}
for (rp = result; rp != NULL; rp = rp->ai_next)
{
sfd = socket (rp->ai_family, rp->ai_socktype, rp->ai_protocol);
if (sfd == -1)
continue;
s = bind (sfd, rp->ai_addr, rp->ai_addrlen);
if (s == 0)
{
/* We managed to bind successfully! */
break;
}
close (sfd);
}
if (rp == NULL)
{
fprintf (stderr, "Could not bindn");
return -1;
}
freeaddrinfo (result);
return sfd;}
//函数//功能
:设置socket为非阻塞的
static in
tmake_socket_non_blocking (int sfd)
{
int flags, s;
//得到文件状态标志
flags = fcntl (sfd, F_GETFL, 0);
if (flags == -1)
{
perror ("fcntl");
return -1;
}
//设置文件状态标志
flags |= O_NONBLOCK;
s = fcntl (sfd, F_SETFL, flags);
if (s == -1)
{
perror ("fcntl");
return -1;
}
return 0;
}
//端口由参数argv[1]指定
int main (int argc, char *argv[])
{
int sfd, s;
int efd;
struct epoll_event event;
struct epoll_event *events;
if (argc != 2)
{
fprintf (stderr, "Usage: %s [port]n", argv[0]);
exit (EXIT_FAILURE);
}
sfd = create_and_bind (argv[1]);
if (sfd == -1) abort ();
s = make_socket_non_blocking (sfd);
if (s == -1)
abort ();
s = listen (sfd, SOMAXCONN);
if (s == -1)
{
perror ("listen");
abort ();
}
//除了参数size被忽略外,此函数和epoll_create完全相同
efd = epoll_create1 (0);
if (efd == -1)
{
perror ("epoll_create");
abort ();
}
event.data.fd = sfd;
event.events = EPOLLIN | EPOLLET;//读入,边缘触发方式
s = epoll_ctl (efd, EPOLL_CTL_ADD, sfd, &event);
if (s == -1)
{
perror ("epoll_ctl");
abort ();
}
/* Buffer where events are returned */
events = calloc (MAXEVENTS, sizeof event);
/* The event loop */
while (1)
{
int n, i;
n = epoll_wait (efd, events, MAXEVENTS, -1);
for (i = 0; i < n; i++)
{
if ((events[i].events & EPOLLERR) ||
(events[i].events & EPOLLHUP) ||
(!(events[i].events & EPOLLIN)))
{
/* An error has occured on this fd, or the socket is not
ready for reading (why were we notified then?) */
fprintf (stderr, "epoll errorn");
close (events[i].data.fd);
continue;
}
else if (sfd == events[i].data.fd)
{
/* We have a notification on the listening socket, which
means one or more incoming connections. */
while (1)
{
struct sockaddr in_addr;
socklen_t in_len;
int infd;
char hbuf[NI_MAXHOST], sbuf[NI_MAXSERV];
in_len = sizeof in_addr;
infd = accept (sfd, &in_addr, &in_len);
if (infd == -1)
{
if ((errno == EAGAIN) ||
(errno == EWOULDBLOCK))
{
/* We have processed all incoming
connections. */
break;
}
else
{
perror ("accept");
break;
}
}
//将地址转化为主机名或者服务名
s = getnameinfo (&in_addr, in_len,
hbuf, sizeof hbuf,
sbuf, sizeof sbuf,
NI_NUMERICHOST | NI_NUMERICSERV);//flag参数:以数字名返回
//主机地址和服务地址
if (s == 0)
{
printf("Accepted connection on descriptor %d "
"(host=%s, port=%s)n", infd, hbuf, sbuf);
}
/* Make the incoming socket non-blocking and add it to the
list of fds to monitor. */
s = make_socket_non_blocking (infd);
if (s == -1)
abort ();
event.data.fd = infd;
event.events = EPOLLIN | EPOLLET;
s = epoll_ctl (efd, EPOLL_CTL_ADD, infd, &event);
if (s == -1)
{
perror ("epoll_ctl");
abort ();
}
}
continue;
}
else
{
/* We have data on the fd waiting to be read. Read and
display it. We must read whatever data is available
completely, as we are running in edge-triggered mode
and won't get a notification again for the same
data. */
int done = 0;
while (1)
{
ssize_t count;
char buf[512];
count = read (events[i].data.fd, buf, sizeof(buf));
if (count == -1)
{
/* If errno == EAGAIN, that means we have read all
data. So go back to the main loop. */
if (errno != EAGAIN)
{
perror ("read");
done = 1;
}
break;
}
else if (count == 0)
{
/* End of file. The remote has closed the
connection. */
done = 1;
break;
}
/* Write the buffer to standard output */
s = write (1, buf, count);
if (s == -1)
{
perror ("write");
abort ();
}
}
if (done)
{
printf ("Closed connection on descriptor %dn",
events[i].data.fd);
/* Closing the descriptor will make epoll remove it
from the set of descriptors which are monitored. */
close (events[i].data.fd);
}
}
}
}
free (events);
close (sfd);
return EXIT_SUCCESS;}运行方式:
在一个终端运行此程序:epoll.out PORT
另一个终端:telnet 127.0.0.1 PORT