Logstash

logstash基于JRuby实现,可以跨平台运行在JVM上
优点
主要的优点就是它的灵活性,这还主要因为它有很多插件。然后它清楚的文档已经直白的配置格式让它可以再多种场景下应用。这样的良性循环让我们可以在网上找到很多资源,几乎可以处理任何问题。
劣势
Logstash 致命的问题是它的性能以及资源消耗(默认的堆大小是 1GB)。尽管它的性能在近几年已经有很大提升,与它的替代者们相比还是要慢很多的。因为logstash是jvm跑的,资源消耗比较大,所以后来作者又用golang写了一个功能较少但是资源消耗也小的轻量级的logstash-forwarder。不过作者只是一个人,elastic.co公司以后,因为es公司本身还收购了另一个开源项目packetbeat,而这个项目专门就是用golang的,有整个团队,所以es公司干脆把logstash-forwarder的开发工作也合并到同一个golang团队来搞,于是新的项目就叫filebeat了。logstash 和filebeat都具有日志收集功能,filebeat更轻量,占用资源更少,但logstash 具有filter功能,能过滤分析日志。一般结构都是filebeat采集日志,然后发送到消息队列,redis,kafaka。然后logstash去获取,利用filter功能过滤分析,然后存储到elasticsearch中。
Filebeat
使用Go语言编写
工作原理:
Filebeat可以保持每个文件的状态,并且频繁地把文件状态从注册表里更新到磁盘。这里所说的文件状态是用来记录上一次Harvster读取文件时读取到的位置,以保证能把全部的日志数据都读取出来,然后发送给output。如果在某一时刻,作为output的ElasticSearch或者Logstash变成了不可用,Filebeat将会把最后的文件读取位置保存下来,直到output重新可用的时候,快速地恢复文件数据的读取。在Filebaet运行过程中,每个Prospector的状态信息都会保存在内存里。如果Filebeat出行了重启,完成重启之后,会从注册表文件里恢复重启之前的状态信息,让FIlebeat继续从之前已知的位置开始进行数据读取。
Prospector会为每一个找到的文件保持状态信息。因为文件可以进行重命名或者是更改路径,所以文件名和路径不足以用来识别文件。对于Filebeat来说,都是通过实现存储的唯一标识符来判断文件是否之前已经被采集过。
如果在你的使用场景中,每天会产生大量的新文件,你将会发现Filebeat的注册表文件会变得非常大
优势
Filebeat 只是一个二进制文件没有任何依赖。它占用资源极少,尽管它还十分年轻,正式因为它简单,所以几乎没有什么可以出错的地方,所以它的可靠性还是很高的。它也为我们提供了很多可以调节的点,例如:它以何种方式搜索新的文件,以及当文件有一段时间没有发生变化时,何时选择关闭文件句柄。开始时,它只能将日志发送到 Logstash 和 Elasticsearch,而现在它可以将日志发送给 Kafka 和 Redis,在 5.x 版本中,它还具备过滤的能力。这也就意味着可以将数据直接用 Filebeat 推送到 Elasticsearch,并让 Elasticsearch 既做解析的事情,又做存储的事情。也不需要使用缓冲,因为 Filebeat 也会和 Logstash 一样记住上次读取的偏移。
filebeat只需要10来M内存资源;
典型应用场景
Filebeat 在解决某些特定的问题时:日志存于文件,我们希望
将日志直接传输存储到 Elasticsearch。这仅在我们只是抓去(grep)它们或者日志是存于 JSON 格式(Filebeat 可以解析 JSON)。或者如果打算使用 Elasticsearch 的 Ingest 功能对日志进行解析和丰富。
将日志发送到 Kafka/Redis。所以另外一个传输工具(例如,Logstash 或自定义的 Kafka 消费者)可以进一步丰富和转发。这里假设选择的下游传输工具能够满足我们对功能和性能的要求
Flume

Flume 是Apache旗下使用JRuby来构建,所以依赖JAVA运行环境。Flume本身最初设计的目的是为了把数据传入HDFS中(并不是为了采集日志而设计,这和Logstash有根本的区别.
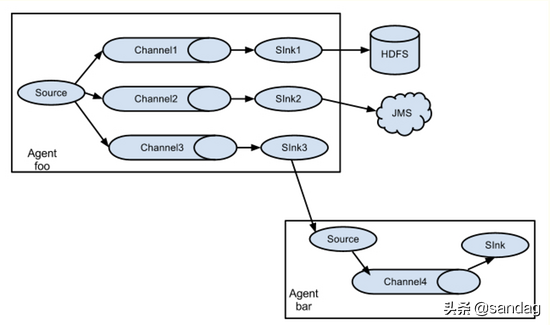
Flume设计成一个分布式的管道架构,可以看作在数据源和目的地之间有一个Agent的网络,支持数据路由。

每一个agent都由Source,Channel和Sink组成。
Source:Source负责接收输入数据,并将数据写入管道。Flume的Source支持HTTP,JMS,RPC,NetCat,Exec,Spooling Directory。其中Spooling支持监视一个目录或者文件,解析其中新生成的事件。
Channel:Channel 存储,缓存从source到Sink的中间数据。可使用不同的配置来做Channel,例如内存,文件,JDBC等。使用内存性能高但不持久,有可能丢数据。使用文件更可靠,但性能不如内存。
Sink:Sink负责从管道中读出数据并发给下一个Agent或者最终的目的地。Sink支持的不同目的地种类包括:HDFS,HBASE,Solr,ElasticSearch,File,Logger或者其它的Flume Agent。
优势
Flume已经可以支持一个Agent中有多个不同类型的channel和sink,我们可以选择把Source的数据复制,分发给不同的目的端口,比如:
Flume还自带了分区和拦截器功能,因此不是像很多实验者认为的没有过滤功能
缺点
Luentd和其插件都是由Ruby开发
Logagent
优势
可以获取 /var/log 下的所有信息,解析各种格式(Elasticsearch,Solr,MongoDB,Apache HTTPD等等),它可以掩盖敏感的数据信息,例如,个人验证信息(PII),出生年月日,信用卡号码,等等。它还可以基于 IP 做 GeoIP 丰富地理位置信息(例如,access logs)。同样,它轻量又快速,可以将其置入任何日志块中。在新的 2.0 版本中,它以第三方 node.js 模块化方式增加了支持对输入输出的处理插件。重要的是 Logagent 有本地缓冲,所以不像 Logstash ,在数据传输目的地不可用时会丢失日志。
劣势
尽管 Logagent 有些比较有意思的功能(例如,接收 Heroku 或 CloudFoundry 日志),但是它并没有 Logstash 灵活。
典型应用场景
Logagent 作为一个可以做所有事情的传输工具是值得选择的(提取、解析、缓冲和传输)。
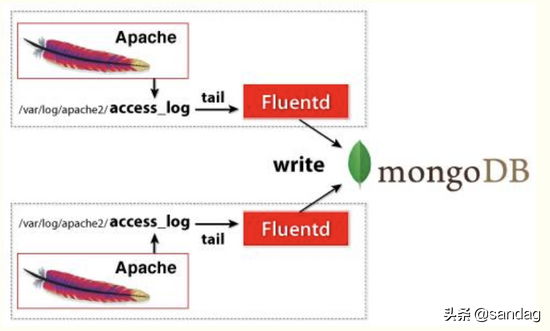
Fluentd
fluentd基于CRuby实现,并对性能表现关键的一些组件用C语言重新实现,整体性能不错。
fluentd设计简洁,pipeline内数据传递可靠性高。相较于logstash,其插件支持相对少一些。
开源社区中流行的日志收集工具,所以支持相对较好
rsyslog
优势
rsyslog 是经测试过的最快的传输工具。如果只是将它作为一个简单的 router/shipper 使用,几乎所有的机器都会受带宽的限制,但是它非常擅长处理解析多个规则。它基于语法的模块( mmnormalize )无论规则数目如何增加,它的处理速度始终是 线性增长 的。这也就意味着,如果当规则在 20-30 条时,如解析 Cisco 日志时,它的性能可以大大超过基于正则式解析的 grok ,达到 100 倍(当然,这也取决于 grok 的实现以及 liblognorm 的版本)。
它同时也是我们能找到的最轻的解析器,当然这也取决于我们配置的缓冲。
劣势
rsyslog 的配置工作需要更大的代价(这里有一些例子),这让两件事情非常困难:
文档难以搜索和阅读,特别是那些对术语比较陌生的开发者。
5.x 以上的版本格式不太一样(它扩展了 syslogd 的配置格式,同时也仍然支持旧的格式),尽管新的格式可以兼容旧格式,但是新的特性(例如,Elasticsearch 的输出)只在新的配置下才有效,然后旧的插件(例如,Postgres 输出)只在旧格式下支持。
尽管在配置稳定的情况下,rsyslog 是可靠的(它自身也提供多种配置方式,最终都可以获得相同的结果),它还是存在一些 bug
syslog-ng
可以将 syslog-ng 当作 rsyslog 的替代品(尽管历史上它们是两种不同的方式)。它也是一个模块化的 syslog 守护进程,但是它可以做的事情要比 syslog 多。它可以接收磁盘缓冲并将 Elasticsearch HTTP 作为输出。它使用 PatternDB 作为语法解析的基础,作为 Elasticsearch 的传输工具,它是一个不错的选择。
优势
和 rsyslog 一样,作为一个轻量级的传输工具,它的性能也非常好。它曾经比 rsyslog 慢很多,但是 2 年前能达到 570K Logs/s 的性能 并不差。并不像 rsyslog ,它有着明确一致的配置格式以及完好的文档。
劣势
linux 发布版本转向使用 rsyslog 的原因是 syslog-ng 高级版曾经有很多功能在开源版中都存在,但是后来又有所限制。我们这里只关注与开源版本,所有的日志传输工具都是开源的。现在又有所变化,例如磁盘缓冲,曾经是高级版存在的特性,现在开源版也有。但有些特性,例如带有应用层的通知的可靠传输协议(reliable delivery protocol)还没有在开源版本中。
logtail
阿里云日志服务的生产者,目前在阿里集团内部机器上运行,经过3年多时间的考验,目前为阿里公有云用户提供日志收集服务。
采用C++语言实现,对稳定性、资源控制、管理等下过很大的功夫,性能良好。相比于logstash、fluentd的社区支持,logtail功能较为单一,专注日志收集功能。
以下为对比图: