今天准备谈下ESB总线平台建设项目中的服务运行统计分析,服务心跳监测,服务监控预警方面的设计和实现。可以看到,在一个ESB服务总线平台上线后,SOA治理管控就变得相当重要,而这些运行监控分析本身也是提升ESB总线平台高可用性的关键。
对于ESB总线本身的高可用性建设,我在前面写过一篇文章可以参考。
今天主要分享下对于这类大型ESB总线平台建设项目在服务运行统计分析,服务心跳监测,服务监控,服务预警等配合高可用性能力方面的一些实践总结。
对于ESB服务运行监控,从SOA服务管控和治理层面来看,经常会涉及到的KPI性能指标并不多,主要还是体现在运行次数,运行时间等关键的维度,如果考虑到指标本身之间的关联关系方便分析,那么还需要增加服务运行的并发数(分钟级),服务调用的数据量等关键指标。
举例来说,当我们发现服务调用变慢了,即服务运行时间明显增加了,那么我们需要分析是否是该服务本身的并发量是否增加了,还是说服务本身调用的数据量增加了,还是说其它服务调用的并发量和数据量增加了导致该服务的资源被占用等。这些都是可能需要涉及到关联分析的地方。
首先我们来看下单次服务运行能够采集和记录的关键数据

接着再来看某个时间周期的情况,比如1个小时,1天,1周或1个月的统计时间周期
对于时间周期只我们我们统计的一个维度,而对服务进行分析的时候还需要考虑如下维度
经过以上分析,我们看到一个最底层的服务运行日志信息,就有了按时间维度,按组织,服务类型,系统等多个维度进行维度分析和统计的可能。而这些恰好又是我们进行自定义报表和维度分析的基础。所有的统计分析基本都会基于以上基础运行信息展开进行。
基于以上思考,我们整合了一个面向组织和业务系统的服务运行统计分析报表,可以按系统的维度详细的查看到自己提供和消费的接口服务的运行情况,异常情况,并发量和数据量,异常和告警等各种关键信息。如下参考:
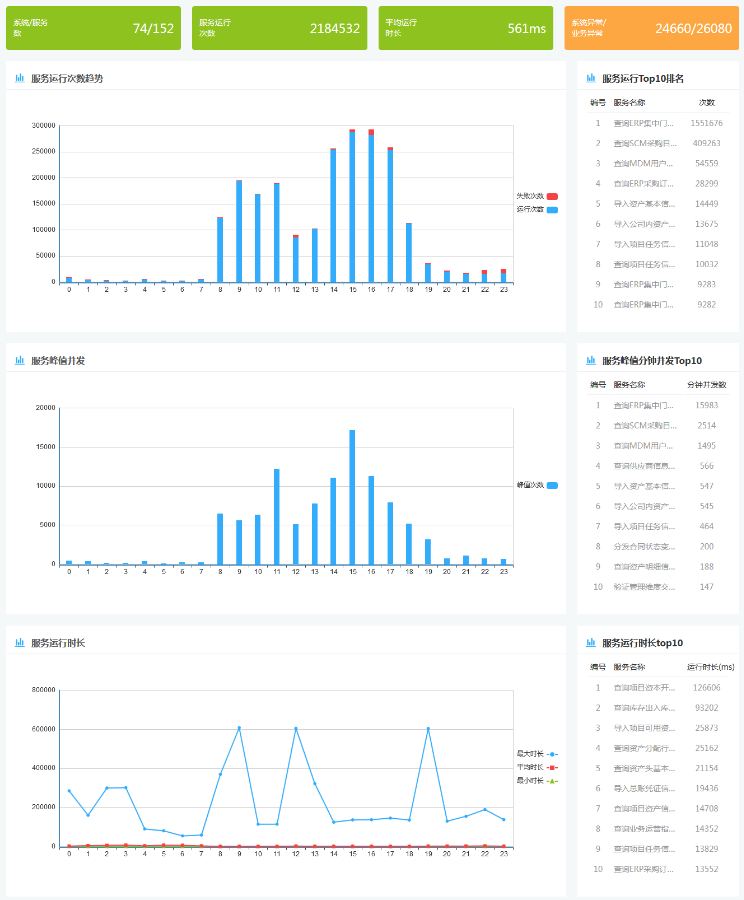
为了做完整的服务运行和性能分析,我们最好还需要对中间件资源池(应用服务器和数据库服务器)的CPU,内存利用率,存储使用量等关键指标进行实时的性能分析和监控。在实际的性能分析和监控中往往也是首先会从CPU和内存告警上第一时间反应出服务当前运行出现异常(如大并发,超大数据传输等),然后我们在通过实际的日志监控分析功能快速的查看当前服务运行的并发情况,传递的数据量情况等。
当我们发现如果一个服务经常运行大并发,大数据量的异常调用的时候,则需要对服务单独启用流量控制策略等。比如:
服务运行指标相关之间的关联分析是我们进行服务运行问题排查,异常告警问题根源分析的基础。在前面谈SOA治理管控平台中,我们曾经画过一个图来说明,服务运行过程中的基础物理资源,数据库和应用服务器中间件资源,服务运行KPI和SLA设置之间的关联关系,如下:

基于上图,我们进一步做下扩展分析,先做下基本的关联关系判别:
JVM内存持续增加不释放,一个是服务并发量增加同时服务调用时间增长,其次是出现大数据量,长执行时间的服务调用,导致服务连接和内存无法快速回收。CPU使用率高升,但是内存利用率一般,一般为出现大并发量的服务调用,其次对于服务调用过程中有过多的数据映射,转换等处理导致CPU利用率增加。
服务调用运行时间长,首先要分析是否是原始服务本身调用时间就变长,如果不是,则一般是在ESB服务调用上出现大量长周期服务调用,但是连接不能快速是否,线程池满一直排队的情况。
如果JVM内存溢出,首先要通过Jstat工具监控下内存GC回收的情况,究竟是新时代,老生代,还是PermSize出现溢出。如果是PermSize需要进一步分析是否是程序本身有问题。
如果没有做流量控制,单个服务本身的大并发,大数据量调用往往会侵占所有资源,对整个ESB上其它运行的服务都造成性能影响。
对于ESB总线本身的等待线程数增加一定会涉及到内存持续增加,涉及到服务调用响应周期增加。如果是服务调用超时,则需要分析具体是在哪段引起的超时,是原始服务本身超时,还是在ESB中间件上进行服务处理的时候超时。
对于服务告警和预警,前面也讲到过,再强调下具体场景包括
注意对于服务告警策略可以是针对所有服务,也可以是针对某个具体的服务,对于阈值可以是一个百分比数,也可以是一个绝对值。接下来我们再看下服务运行各个指标本身之间的一些关联关系:
而对于整个ESB中间件的性能监控和分析,从最底层的IT基础设施,存储和服务器,到ESB中间件资源池,再到具体运行的服务运行包,相互之间存在密切的关联,需要达到的效果往往是第一时间反馈出预警。并且通过预警去采取后续的行动措施和SLA策略设置等。
1. 从资源池监控发现的CPU和内存异常第一时间找到非法调用服务?

如果有CPU和内存利用率出现异常,同时某个服务或某几个服务出现运行性能告警,那么我们就有了分析的依据究竟是哪个服务导致的。并快速定位到具体的服务。在定位到具体的服务后,可以再详细查看服务调用的并发数,数据量等信息,然后有针对性的对服务展开流量控制策略。
2. 如果JVM内存持续上升而没有释放,如何快速定位到服务?
这个也是经常遇到的问题,当JVM内存持续增加,或者连接数不断的增加而不释放的时候,如果我们不进行及时的处理往往就导致整个JVM内存溢出而影响到所有ESB服务的运行。因此在这种场景下我们需要尽快的发现导致问题的服务,并对服务采取相应的措施。
3. 从服务运行告警到自动熔断
为了不因为一个具体服务的异常非法调用而影响到所有服务的运行,对于单个服务在出现持续性的告警后,应该有策略直接对该服务进行熔断处理。比如直接对服务进行禁用处理。
在前面部分已经详细分析了服务本身的运行并发,次数和数据量与JVM内存,与CPU和内存利用率等各个关键指标之间的勾稽关系。
这些指标之间本身相互影响和作用,我们对指标的监控本身应该是风险驱动的,即在系统出现宕机或内存溢出等故障问题前快速的发现问题并进行处理。
因此,我们就需要对各种关键指标进行心跳监控和实时预警。
对JVM内存利用率进行监控
在前面我们已经谈到了,实际上出现JVM溢出的时候,往往会由于请求漂移影响到整个集群大量节点内存溢出而导致集群不可用。
因此需要时刻监控JVM内存利用率的情况,如果发现JVM内存持续在某个高位,无法通过Gc操作将内存回收下来的时候就应该实时进行预警。
在预警后我们既可以进行人工处理,也可以设置策略直接对问题节点进行重启操作。
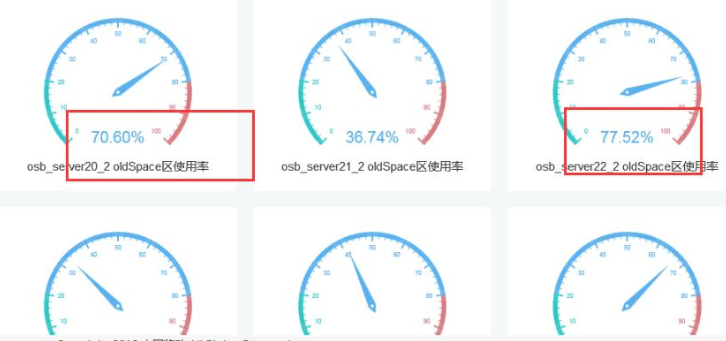
如上,我们对所有集群节点的JVM内存利用率进行实时监控,当发现利用率持续大于70%的时候就进行相应的预警操作,如果超过80%就推送严重警告信息。
对后端业务系统和服务本身可用性监控
其次,ESB服务总线如果出现服务调用异常,除了ESB总线本身的异常故障外,更大的可能性是后端业务系统不可用,或者说后端业务系统提供的业务服务不可用导致。
对于ESB总线本身,我们可以实时心跳检查ESB总线暴露的服务可用性,如下:

如果是后端系统本身不可用,那么往往会快速的返回connection timeout异常信息,这样不会影响到整个ESB总线平台稳定性。但是如果是后端业务系统服务假死或处于长时间无响应的状态,那么就会导致大量的连接无法释放,最终导致资源被消耗完。
因此对后端系统和后端服务进行实时心跳监控也是有必要的。
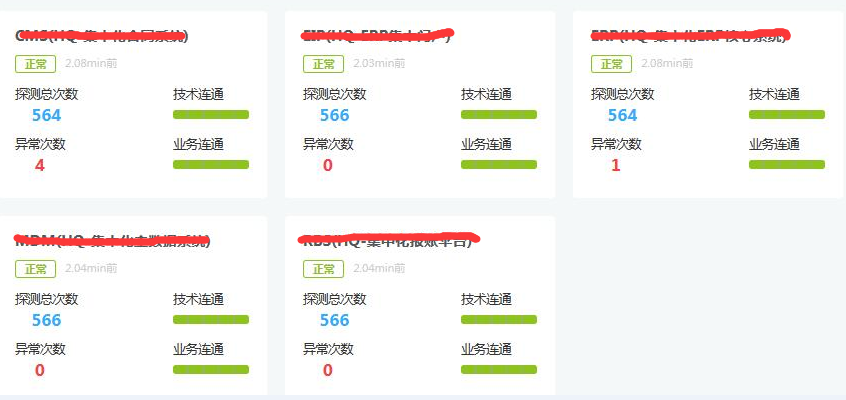
不论是对于ESB集群还是后端业务系统的监控,实际上都包括两个方面的监控,一个我们叫技术联通性监控,一个叫业务联通性监控。
技术连通性即是否出现conneciton timeout访问超时,是就返回异常。而对于业务联通性,则是调用真实的某个业务服务接口,如果出现read time out则返回业务连通失败错误。
对服务运行进行实时心跳监控
其次,我们还需要对服务运行进行实时心跳监控,即时刻监控服务运行的并发量,数据量,运行时长等几个关键数据指标。
在前面已经谈到过以上几个指标本身存在勾稽关系,比如发现服务运行平均时长增加,那么很可能是服务并发量增加或调用数据量增加导致。其次,如果发现服务调用的消息报文数据量猛增,那么很可能导致服务运行时长增加。
因此需要对以上几个关键指标进行实时监控,时刻监控是否发生了峰值突变情况。
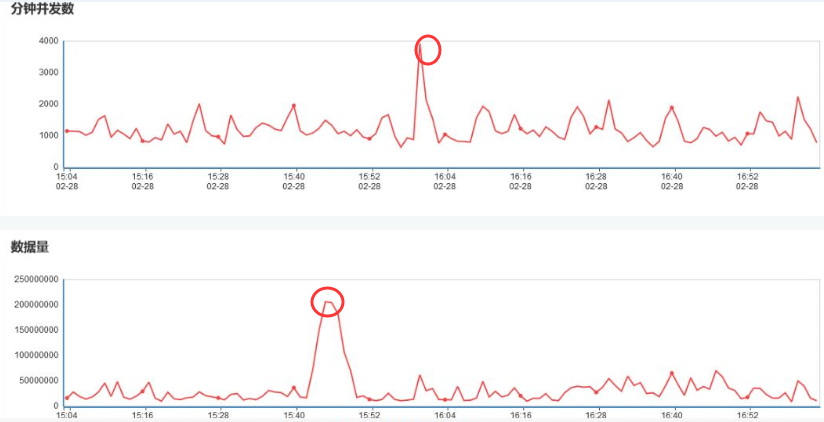
当发现了峰值或突变的时候,我们就需要进行预警,并分析发生大并发或大数据量调用的原因并及时采取相应的流量管控措施,以确保整个ESB平台的稳定性。

监控大屏更多的是展示基于服务集成层面的总览数据,同时对关键的异常告警信息,关键指标心跳,关键指标排名信息进行展示。这些都应该在Level1级层面的视图或报表。
我们举一个简单场景,一个企业实施了ESB总线后,集成了20个业务系统,上100个服务接口,每天大概产生100万条服务调用示例记录,高峰时期的分钟级并发在1万次左右。
总线实际上和硬件类网关很类似,当所有的服务调用全部都有经过总线的时候,我们就更加关心总线上实际的实时并发量,数据流量大小数据。而且这两个数据最好是要实现准实时的监控。以分钟级为例,我们需要监控分钟级的服务调用次数,分钟级的服务调用传输数据量。
监控着两个指标是否出现突然的峰值调用,如果没有一般来说总线运行本身也不好出现问题。如果出现了各种异常大并发,大数据量调用,则一定会体现到我们的监控时序图上面。这两个数据实际上是适合在大屏上面实时心跳检测并显示的。
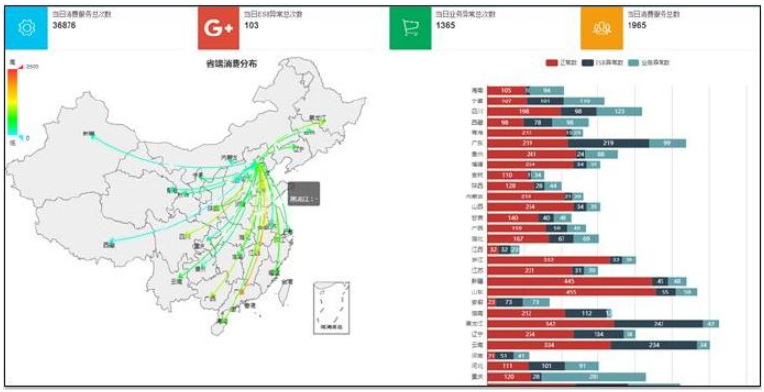
对于大屏可视化展示,我们可以理解为总览,即更多的是当前ESB总线服务,集成的业务系统的总体健康情况。因此在大屏上我们可以考虑对当天的一些统计数据进行统计展示。
这些统计数据包括了服务调用总次数,平均时长,总数据量,平均数据量,分钟级最大并发,接入总系统数,接入总服务数,总异常数,总告警次数等。对于异常告警往往是一个比较重要的展示内容,特别是异常信息本身还分为了系统级的异常和业务级的异常,对于告警本身又分为严重,一般,轻微等各种级别的告警。这些都需要在大屏进行一个统计的展示。
如果是做集团到省两级ESB总线实施,在大屏上我们就可以考虑来实现结合地图的可视化效果展示。这个前面有文章说过,可以通过连线,端点节点大小,颜色等来体现服务调用流量,状态等信息。
即使是单级ESB总线,在大屏展示的时候我们也需要考虑是否能够展示一个集成架构视图,能够展示出当前总线集成的多个业务系统,类似Bus总线的展示方式,可以通过该图将集成的关键系统全部标注出来。同时对于集成的系统上本身可以显示更多的关键信息。
如果集成的业务系统用一个方框进行展示,那么在方框里面可以考虑展示。
最后,大屏本身也可以展示一些列表数据,但是从大屏可视化效果来说,列表数据不适合展示太多。可以考虑的列表数据展示主要包括了服务运行次数,服务调用异常,服务调用耗时或数据量的Top10排名信息显示等。