作者介绍
小火牛,项目管理高级工程师,具有多年大数据平台运维管理及开发优化经验。管理过多个上千节点集群,擅长对外多租户平台的维护开发。信科院大数据性能测试、功能测试主力,大厂PK获得双项第一。
前言
某业务导致NameNode RPC通信频繁,后来观察监控发现,是由于该业务获取HDFS列表文件的频率过于频繁。检查代码后,优化由20s获取一次目录列表改为5分钟获取一次,获取列表的RPC操作次数下降了约1.5倍,平均每秒减少了2~3w次的RPC操作。

还有很多业务场景,通过分析观察RPC画像,都发现了其不合理性,这里就不一一列举了。本文主要记录如何通过ELK快速分析NameNode RPC操作并对接Grafana展示。
通过ELK快速分析NameNode RPC操作
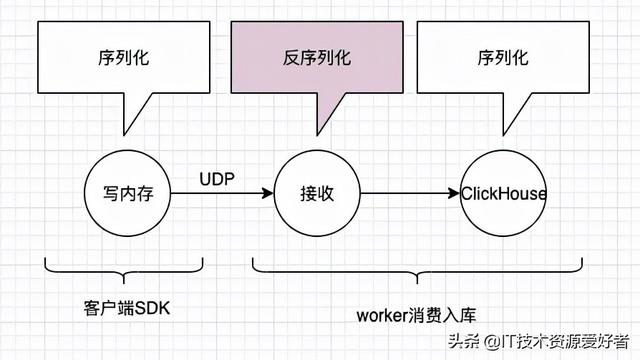
ELK是当前比较主流的分布式日志收集处理工具。这里采用Filebeat→Kafka集群→Logstash→ES→Kibana。
采用原因:
1)Filebeat是基于原先logstash-forwarder的源码改造出来的。换句话说:Filebeat就是新版的logstash-forwarder,也会是Elastic Stack在shipper端的第一选择。
2)小贴士:虽然LogStash::Inputs::TCP用Ruby的Socket和OpenSSL库实现了高级的SSL功能,但Logstash本身只能在SizedQueue中缓存20个事件。这就是我们建议在生产环境中换用其他消息队列的原因。
而redis服务器是Logstash官方推荐的Broker选择,Broker角色也就意味着会同时存在输入和输出两个插件。
Kafka是一个高吞吐量的分布式发布订阅日志服务,具有高可用、高性能、分布式、高扩展、持久性等特性。目前已经在各大公司中广泛使用。和之前采用Redis做轻量级消息队列不同,Kafka利用磁盘作队列,所以也就无所谓消息缓冲时的磁盘问题。此外,如果公司内部已有Kafka服务在运行,Logstash也可以快速接入,免去重复建设的麻烦。
3)目前Logstash1.5版本已自带支持Kafka插件,所以只需要学会如何书写Logstash规则,并且Kafka消费使用high-level消费。
4)Filebeat部署在应用服务器上(只负责Logstash的读取和转发,降低CPU负载消耗,确保不会抢占应用资源),Logstash、ES、Kibana在一台服务器上(此处的Logstash负责日志的过滤,会消耗一定的CPU负载,可以考虑如何优化过滤的语法步骤来达到降低负载)。
具体搭建步骤:Filebeat安装使用(思考后决定Filebeat使用Zip安装或者tar.gz方便修改配置打包分发。)→Logstash插件配置。
以下是架构图:

1、Filebeat采集hdfs-audit.log日志传输给Kafka或者Logstash
[hadoop@lf319-m3-002 filebeat]$ vi dynamically.config/audit-logstash.yml
filebeat.prospectors:
- input_type: log
paths:
- "/var/log/hadoop-hdfs/hdfs-audit.log"
harvester_buffer_size: 32768
scan_frequency: 1s
backoff: 10ms
#backoff <= max_backoff <= scan_frequency
processors:
- drop_fields:
fields: ["beat", "beat.name", "beat.hostname","beat.version","input_type","offset","@timestamp","type","source"]
output.logstash:
hosts: ["logstash-host:5044"," logstash-host:5045"]
loadbalance: true
worker: 4
bulk_max_size: 4096
#output.console:
# pretty: true
xpack.monitoring:
enabled: true
elasticsearch:
hosts: ["https://es-host1:9200", "https:// es-host2:9200"]
username: beats_system
password: beat@123
2、Logstash进一步分解日志,格式化日志数据
这里需要我们先查看下日志的格式,然后选择方便的日志格式化方式来解析日志。
日志格式案例:
2019-08-25 13:11:58,630 INFO FSNamesystem.audit: allowed=trueugi=lf_zh_pro (auth:SIMPLE)ip=/dn-ipcmd=getfileinfosrc=/user/lf_zh_pro/test/CommonFilter/sync/biz_id=B43/day_id=20190825/prov_id=089/part-00019-1566675749932.gzdst=perm=proto=rpc
2019-08-25 13:11:58,630 INFO FSNamesystem.audit: allowed=trueugi=lf_xl_bp (auth:SIMPLE)ip=/dn-ipcmd=createsrc=/user/lf_xl_bp/lf_xl_src.db/src_d_trip_all/date_id=20190825/hour_id=13/minute_id=00/.hive-staging_hive_2019-08-25_13-10-18_301_9180087219965934496-1/_task_tmp.-ext-10002/prov_id=031/_tmp.000238_0dst=perm=lf_xl_bp:lf_xl_bp:rw-rw-r--proto=rpc
2019-08-25 13:11:58,630 INFO FSNamesystem.audit: allowed=trueugi=ubd_obx_test (auth:SIMPLE)ip=/ dn-ipcmd=rename
通过观察可以发现上面的每条日志格式都是一致的,都由时间戳、日志级别、是否开启审计、用户、来源IP、命令类型这几个字段组成。那么相较于grok来说dissect更加简明。
Dissect的使用规则:https://www.elastic.co/guide/en/logstash/current/plugins-filters-dissect.html
Logstash配置如下:
input {
beats {
port => "5045"
}
}
filter {
if "/user/if_ia_pro/output/test" in [message] {
dissect {
mApping => { "message" => "%{logd} %{drop} %{level} %{log-type}: %{?allowed}=%{&allowed}%{?ugi}=%{&ugi} (%{?authtype})%{?ip}=/%{&ip}%{?cmd}=%{&cmd}%{}=/user/if_ia_pro/output/test/%{src2}/%{src3}/%{}%{?dst}=%{&dst}%{?perm}=%{&perm}%{?proto}=%{&proto}" }
add_field => {
"srctable" => "/user/if_ia_pro/output/test/%{src2}/%{src3}"
"logdate" => "%{logd} %{drop}"
}
remove_field => ['message','src2','src3','logd','drop']
}
}
else if "/user/lf_zh_pro/lf_safedata_pro/output/" in [message] {
dissect {
mapping => { "message" => "%{logd} %{drop} %{level} %{log-type}: %{?allowed}=%{&allowed}%{?ugi}=%{&ugi} (%{?authtype})%{?ip}=/%{&ip}%{?cmd}=%{&cmd}%{}=/user/lf_zh_pro/lf_safedata_pro/output/%{src2}/%{}%{?dst}=%{&dst}%{?perm}=%{&perm}%{?proto}=%{&proto}" }
add_field => {
"srctable" => "/user/lf_zh_pro/lf_safedata_pro/output/%{src2}"
"logdate" => "%{logd} %{drop}"
}
remove_field => ['message','src2','drop']
}
}
else if "/files/" in [message] {
dissect {
mapping => { "message" => "%{logd} %{drop} %{level} %{log-type}: %{?allowed}=%{&allowed}%{?ugi}=%{&ugi} (%{?authtype})%{?ip}=/%{&ip}%{?cmd}=%{&cmd}%{}=/files/%{src2}/%{}%{?dst}=%{&dst}%{?perm}=%{&perm}%{?proto}=%{&proto}" }
add_field => {
"srctable" => "/files/%{src2}"
"logdate" => "%{logd} %{drop}"
}
remove_field => ['message','src2','drop']
}
}
else {
dissect {
mapping => { "message" => "%{logd} %{drop} %{level} %{log-type}: %{?allowed}=%{&allowed}%{?ugi}=%{&ugi} (%{?authtype})%{?ip}=/%{&ip}%{?cmd}=%{&cmd}%{}=/%{src}/%{src1}/%{src2}/%{src3}/%{}%{?dst}=%{&dst}%{?perm}=%{&perm}%{?proto}=%{&proto}" }
add_field => {
"srctable" => "/%{src}/%{src1}/%{src2}/%{src3}"
"logdate" => "%{logd} %{drop}"
}
remove_field => ['message','src','src1','src2','src3','logd','drop']
}
}
date {
match => [ "logdate","ISO8601" ]
target => "@times"
remove_field => ['logdate']
}
}
output {
elasticsearch {
hosts => ["es-host:9200"]
index => "logstash-hdfs-auit-%{+YYYY.MM.dd}"
user => "elastic"
password => "password"
}
stdout { }
}
3、ES上观察数据
Filebeat和Logstash配置好采集分析hdfs-audit.log之后启动进程,到ES上观察会发现创建有logstash-hdfs-auit- YYYY.MM.dd的index。

具体查看数据,可以看到已经具备多个需要使用到的字段。

Grafana配置NameNode RPC操作
最后一步就需要在Grafana上配置连接ES数据库。

然后创建Dashboard依次配置以下几种查询展示:
1)集群整体RPC每分钟连接次数


2)HDFS路径All下All类型每分钟操作计数


3)All类型操作计数最多的hdfs路径


4)路径All下操作计数排行前五的类型 和All操作类型下操作计数前五的路径

总结
那么现在对于企业来说,不管是在物理机上还是云上,玩自己的大数据平台跑生产任务,就不可避免会有不够合理不够优化的任务,比如最简单的集群对拷任务出现异常中断时,我们通常会挂定时任务并对hadoop distcp添加-update参数,进行对比更新覆盖,这时当定时吊起的过于频繁,就会发现当对拷目录下文件数越来越多,NameNode对该目录的listStatus类型的RPC连接会激增,这时我们就需要优化对拷任务。
RPC的监控只是监控大数据平台的一个指标,这里通过这篇文章,带大家了解下如何快速地采集分析平台日志,并进行展示监控。