gzip压缩简介
什么是gzip压缩,gzip压缩是基于deflate中的算法进行压缩的,gzip会产生自己的数据格式,gzip压缩对于所需要压缩的文件,首先使用LZ77算法进行压缩,再对得到的结果进行huffman编码,根据实际情况判断是要用动态huffman编码还是静态huffman编码,最后生成相应的gz压缩文件。
大家可能注意到了,在我们的HTTP请求头中,会存在accept-encoding字段,其实就是在告诉服务器,客户端所能接受的文件的压缩格式,其中包括gzip、deflate和br等。
那么常见的gzip和deflate有什么区别呢?
1、GZIP,好像是一个不透明的或原子的功能。事实上,HTTP定义了一种机制,一个Web客户机和Web服务器同意一压缩方案可以用来发送内容,这由使用Accept-Encoding和Content-Encoding标头完成。有两种常用的HTTP压缩:DEFLATE和GZIP。
2、DEFLATE是一个无专利的压缩算法,它可以实现无损数据压缩,有众多开源的实现算法。该标准的实施库大多数人用的是zlib的。zlib库提供用于压缩和解压缩使用DEFLATE/INFLATE的数据。zlib库还提供了一种数据格式,混淆的命名ZLIB,它包装DEFLATE压缩数据,具有报头和校验和。
总而言之,GZIP是使用DEFLATE进行压缩数据的另一个压缩库。事实上,GZIP的大多数实现实际使用zlib库的内部进行DEFLATE/ INFLATE压缩操作。GZIP产生其自己的数据格式,混淆的命名GZIP,它包装DEFLATE压缩数据,具有报头和校验和。而由于最初的规定不统一问题,大多数情况下已经启用deflate压缩。
接下来进入本文的正题之一,gzip压缩的流程是怎么样的?
其实gzip压缩一般都是针对文本文件进行压缩,至于原因后面会介绍到,首先LZ77算法基于文本文件对文本内容,即文件中的字符串进行首次压缩,接下来,利用哈夫曼编码,转换为010111..等2进制进行存储。那么具体的算法是怎样的呢?
LZ77算法的核心思想,是对字符串的重复利用,在扫描整个文本的过程中,判断之前的字符串中,有没有出现过类似的字符串或子字符串,通过这样的方式来压缩你的文本长度,举个简单的栗子:
文本内容如下:
http://www.qq.com
http://www.paipai.com
我们把相同的内容括起来
http://www.qq.com
( http://www.)paipai(.com)
用信息对替换之后的结果是
http://www.qq.com
(18,11)paipai(22,4)
其中
(18,11)中,18(起点到下一个起点,包含换行)为相同内容块与当前位置之间的距离,11为相同内容的长度。
(22,4)中,22为相同内容块与当前位置之间的距离,4为相同内容的长度。
由于信息对的大小,小于被替换内容的大小,所以文件得到了压缩。
算法具体实现,首先你要明确几个名词概念:
1.前向缓冲区
每次读取数据的时候,先把一部分数据预载入前向缓冲区。为移入滑动窗口做准备
2.滑动窗口
一旦数据通过缓冲区,那么它将移动到滑动窗口中,并变成字典的一部分。
3.短语字典
从字符序列S1...Sn,组成n个短语。比如字符(A,B,D) ,可以组合的短语为{(A),(A,B),(A,B,D),(B),(B,D),(D)},如果这些字符在滑动窗口里面,就可以记为当前的短语字典,因为滑动窗口不断的向前滑动,所以短语字典也是不断的变化。
在遍历整个文本的字符串的过程中,算法通过判断前向缓冲区中,是否存在滑动窗口中的最长子字符串,实现字符串的“复用”,具体可以看下图:
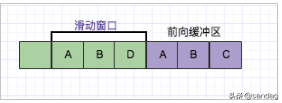
目前滑动窗口中存在的字符串,除去单字符的,则有AB、BD、ABD,而前向缓冲区中,存在AB、ABC、BC,最长的子字符串为AB,则可以将ABC压缩为(0,2,C),其中0表示在滑动窗口中的偏移量,2表示读取两个字符,C表示未匹配的字符。接下来我们看一个完整的压缩案例你就懂了:(图片引自: https://www.jb51.net/article/... )

那么解压过程呢?其实解压过程是非常快速的,如下:

可以看出,LZ77算法的耗时,主要在于压缩阶段中,判断前向缓冲区和滑动窗口中的最长字符串匹配,也就是说,选择滑动窗口大小,以及前向缓冲区大小,对你的LZ77算法的时间复杂度有着关键的影响,其次,合适的滑动窗口大小、缓冲区大小能帮助你对文件进行更好的压缩,提高压缩率。
而在整个解压的过程,只需要通过简单的字符读取,根据偏移量复用子字符串,就完成了解压过程,整个过程没有复杂的算法耗时,这也正符合了我们在网络请求中的适用场景,通过在服务端对文件的一次压缩,提供给所有的用户使用,在客户端对数据进行解压,而解压基本没有什么耗时,因此能大大提高我们的页面资源加载速度。
当你对文件中的文本进行压缩后,接下来其实就是文本的存储了,ASCII编码中,一个字符对应一个字节,通过8位来表示,但是我们真的不能在优化了吗?huffman编码告诉我们,我们还能再压缩!huffman的原理,本质是通过判断字符在文本中的出现频次,规定每个字符的编码,而非固定8位编码,举个简单的栗子:
字符串:AAABCB
按照以往的存储方式 需要6个字节,48bits。
但是我们可以看到,A出现了3次,B出现了2次,C仅仅出现了1次,于是我们换一种存储方式,
用0来表示A,10来表示B,11来表示C
最后的压缩结果是000101110 ,最后我们只用了9个bits来存储了这个字符串!
这就是huffman的根本原理。
可以看到我们的关键在于,为字符生成相应的编码,所以这个过程需要我们构造一个哈弗曼树,什么是哈夫曼树呢?哈弗曼树是通过一系列值,将这些值作为叶子节点,注意是叶子节点,构造成一个树,这个树要求,( 叶子节点的权重 叶子节点的深度 ) 所有叶子节点总数n 的值达到最小。具体的构造过程如下:(图片引自 http://www.360doc.com/content... )

其中,节点值表示字符出现的频次,叶子节点的层级变相意味着 字符编码的长度,其实这也很好理解,我们希望出现频次越多的字符,编码越短越好,频次较少的字符,编码长度较长也无所谓。这也和哈夫曼树的定义完美契合。
可以看到字符串:
abbbbccccddde
a b c d e
1 4 4 3 1
经过我们的huffman编码后,分别表示如下:
a 为 110
b 为 00
c 为 01
d 为 10
e 为 111
聪明的你可能还留意到了,通过huffman编码后的二进制字符,是没有二义性的。
可以看到我们上述的案例,动态生成了huffman编码,所以最后传输数据的时候,还需要把huffman树的信息一起传递过去,当然,这里还存在 静态huffman和动态huffman的区别 :
静态Huffman编码就是使用gzip自己预先定义好了一套编码进行压缩,解压缩的时候也使用这套编码,这样不需要传递用来生成树的信息。
动态Huffman编码就是使用统计好的各个符号的出现次数,建立Huffman树,产生各个符号的Huffman编码,用这产生的Huffman编码进行压缩,这样需要传递生成树的信息。
Gzip 在为一块进行Huffman编码之前,会同时建立静态Huffman树,和动态Huffman树,然后根据要输出的内容和生成的Huffman树,计算使用静态Huffman树编码,生成的块的大小,以及计算使用动态Huffman树编码,生成块的大小。然后进行比较,使用生成块较小的方法进行Huffman编码。
对于静态树来说,不需要传递用来生成树的那部分信息。动态树需要传递这个信息。而当文件比较小的时候,传递生成树的信息得不偿失,反而会使压缩文件变大。也就是说对于文件比较小的时候,就可能会出现使用静态Huffman编码比使用动态Huffman编码,
生成的块小。
竟然gzip这么棒,赶紧在我们的项目中用起来吧!
express和koa默认都没有开启gzip压缩,所以需要自行引入中间件的形式开启压缩,针对text文件进行文本压缩。
const Koa = require("koa");
const path = require("path")
var compress = require('koa-compress')
const App = new Koa();
const static = require('koa-static')
app.use(compress({
filter: function (content_type) {
return /text/g.test(content_type)
},
threshold: 1,
flush: require('zlib').Z_SYNC_FLUSH
}))
app.use(async(ctx, next) => {
//ctx 代表响应 ctx.compress = trus 代表允许压缩
// ctx.compress = true
// ctx.body = "hello"
await next()
})
app.use(static(
path.join( __dirname, 'public'),{
gzip:true
}
))
//可以配置一个或多个
// app.use(static(__dirname + '/static')))
app.listen(3000);
需要注意 koa 的中间件使用 和express是不一样的。
其次,通过filter 函数来判断是否要进行gzip压缩。
除了Nginx或server层做gzip压缩。
也可以在构建的时候压缩,生成相应的gz文件。
const CompressionWebpackPlugin = require('compression-webpack-plugin');
webpackConfig.plugins.push(
new CompressionWebpackPlugin({
asset: '[path].gz[query]',
algorithm: 'gzip',
test: new RegExp('\.(js|css)$'),
threshold: 10240,
minRatio: 0.8
})
)
Q:gzip是否仅限制于文本文件,对于二进制文件呢?音频?图片等资源呢?
A:gzip压缩不仅适用于文本文件,其实也可以对图片等二进制文件进行压缩,但是不推荐这么做,由于gzip的压缩过程首先基于字符串进行LZ77处理,接下里再通过huffman编码,然而,大多数的二进制文件,已经有自己的编码和压缩方式了,对二进制文件进行在压缩,可能导致文件更大,同时,会增大客户端解压缩的压力,带来不必要的CPU损耗。
一些开发者使用HTTP压缩那些已经本地已经压缩过的文件,而这些已经压缩过的文件再次被GZip压缩时,是不能提高性能的,表现在如下两个方面。
首先,HTTP压缩需要成本。Web服务器获得需要的内容,然后压缩它,最后将它发送到客户端。如果内容不能被进一步压缩,你只是在浪费CPU做无意义的任务。
其次,采用HTTP压缩已经被过压缩的东西并不能使它更小。事实上,添加标头,压缩字典,并校验响应体实际上使它变得更大,如下图所示:

Q:gzip压缩过得文件,可以再进行一次gzip压缩吗?多次呢?
A:可以进行再压缩,但是gzip首次压缩过后的文件,本身已经是二进制文件,对文件进行再压缩只会带来没必要的性能损耗,同时可能导致文件增大。
Q:需要对所有文本内容都进行GZIP压缩吗?
A:答案是否定的,可以看到我们的压缩过程中,需要执行算法,假如传输的字符串仅仅几十个字符,那么执行算法是完全没有必要的,并且,对过短的字符进行压缩,可能反而导致传输数据量增大,例如可能要传输动态构造的huffman树信息等。
Q:在哪个阶段对文件进行gzip压缩比较合适?
A:在本地构建部署的时候,通过webpack生成最终的gz压缩文件部署上服务器,是最高效的,假如通过引入中间件,在请求到来时再对文本文件进行压缩,只会让用户的等待时间更长,所以笔者认为,在webpack打包构建的时候做这件事是最合理的。