作者:人月神话,新浪博客同名
今天准备谈下微服务架构和API网关中的限流熔断,当前可以看到对于Spring Cloud框架本身也提供了Hystrix,主流的开源API网关产品类似Kong网关本身也包括了限流熔断能力。
当然也有完全较为独立的限流熔断开源实现,比如阿里的Sentinel即是我们经常会用到的限流熔断开源产品,而且可以和Dubbo,SpringCloud等各种微服务框架无缝集成。
由于网上大家能够搜索到的关于各开源产品实现的限流熔断功能和使用的文章都很多,因此这篇文章不打算再去介绍这些开源产品,而是从业务场景出发来思考下一个限流熔断功能实现中的一些思路。当然,对于我们常说的资源定义,线程池隔离,滑动时间窗口计算等内容仍然是相通的。
问题和背景说明
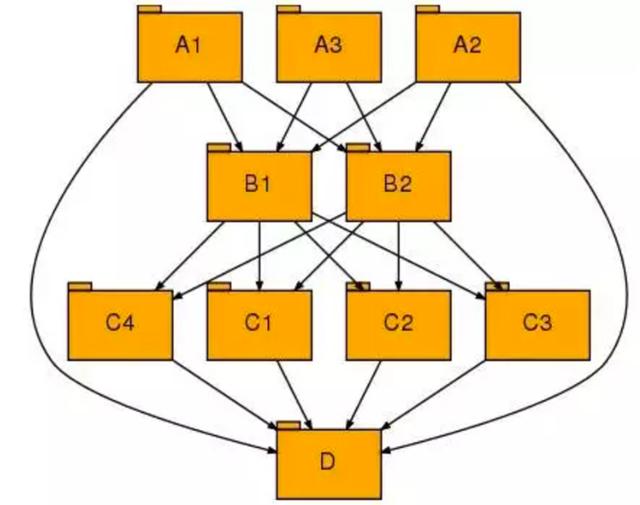
首先我们来看下限流熔断的出现背景。比如上图的一个微服务间调用关系,我们用这个图作为参考来进行一些常见的场景和问题。
某一个API接口服务调用导致整体资源被耗尽
这是一个比较典型的场景,即某一个API接口服务的大并发,大数据量调用导致服务器线程和内存资源的全部耗尽。
对于API接口服务调用,往往并不怕大并发调用,而是怕长耗时和大数据量的调用,这种接口调用导致连接一直被占用,而是大数据量情况下内存资源也一直被占用而服务是否。在这种场景下往往导致线程池满,或者场景的JVM内存溢出问题,将直接导致整个JVM内存溢出宕机。
即我们常说的单个API服务问题导致所有资源被抢占,而影响到所有API接口调用。
常说的服务调用引发雪崩
在微服务架构下,微服务API接口间相互依赖,形成服务链调用关系,如上图。在这种情况下依赖的API接口服务如果出现问题,那么就会导致上层的各个消费方都出现调用异常,而导致整体服务链调用雪崩。
比如上图里面如果C1出现性能问题,那么将直接导致B1和B2都出现性能问题,而由于B层出现的性能问题又会快速的传递到A层,导致A层相关的API接口服务全部出现问题。
通过上面初步分析也可以看到,服务限流熔断简单来说就是不要因为单个API接口服务出现的异常或性能问题而影响都整体API网关或微服务架构的运行,牺牲或拒绝一个服务的访问往往是确保了更多的服务能够正常被消费和调用。
在梳理清楚以上概念后,我们再回来看下服务限流熔断本身的概念。
限流熔断的基本概念
对于限流熔断,我原来给过一个概念,简单来说限流就是服务请求调用要排队,只给你一个线程池总数,超过就等待,即使你瞬间的请求并发再大也需要慢慢进入。而对于熔断则我们常说的整个服务都处于不可用状态。
今天我们对这个概念重新进行下说明。如下图:
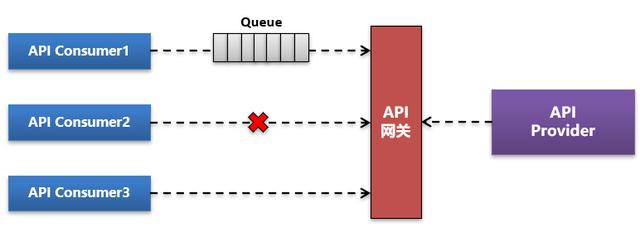
一个API接口有多个Consumer消费方,对于限流更多的是针对消费方+API这个粒度来说的,而对于熔断则是针对整个API Provider服务来说的。
一个限流策略既可以是让消费方的服务请求进行排队,也可以是对触发某个规则后直接对某个特定的消费方调用进行拒绝,比如上图仅拒绝Consumer2的调用,而对于其它消费方调用仍然放行。而对于熔断策略则一定是整个服务全部进行拒绝访问,注意这种熔断不一定必须是服务下线或状态变更,也可以是直接在限流熔断拦截器上对所有入口请求进行拒绝。
整体实现思路说明
在讲具体的实现方案的时候先讲下整体的实现思路。
从前面的分析我们也看到,实际上对于限流和熔断更多的是控制的资源单位和粒度不一样,因为我们希望的是构建一套算法来满足对所有的问题场景下的需求。由于服务限流熔断更多的是需要对服务进行拦截处理,我们也看到限流熔断器一般都会配合API网关,微服务网关等使用,而不是独立的存在。
01-对于资源粒度的考虑
在阿里的Sentinel的实现里面有几个重要的概念,一个是资源,一个是Slot,一个是实现机制中的滑动时间窗口,但是初步看好像无法配置到单个消费方+服务这个层面。
对资源粒度,初步分析应该包括了多个层次,从最粗的资源到最细化的资源,在传统的资源粒度考虑里面我们往往并不会考虑到某个微服务或业务系统这个粒度,但是如果从API网关的限流熔断,对API网关本身的性能保护来说,这个还是有必要。
比如用户中心这个微服务,实际上提供29个API服务接口。
当用户中心微服务模块本身出现问题的时候,这29个微服务可能都会出现性能访问缓慢,那么需要的是对整个用户中心接入的API服务全部限流和熔断。
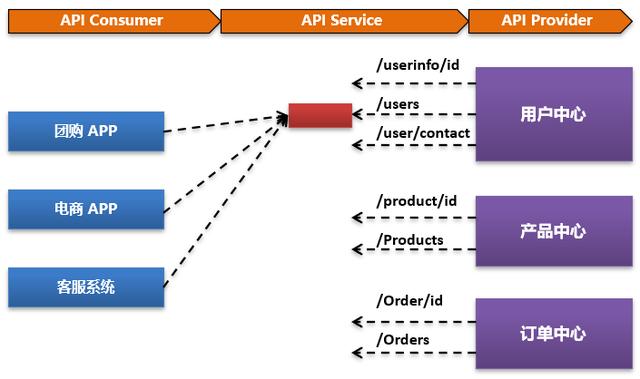
即我们对资源本身的颗粒度进一步细化,从最细粒度到最粗粒度可以分为:
- 最细粒度:API消费方+API服务+API提供方
- 熔断层:API服务+API提供方
- 熔断范围:API提供方(对API服务提供方所有服务进行熔断)
以上三种粒度才是我们实际进行资源控制的时候需要考虑的内容。
为啥考虑这个问题,搞清楚了资源管控的颗粒度,我们一个方面是要在规则配置的时候支持多种层次的配置,一个方面就是我们实际实时数据计算的时候需要进行颗粒度的考虑。
02-对规则的关键说明
要实现限流熔断,简单来就是三个方面的内容,一个就是资源,一个是就是规则,一个就是通过计算汇总处理过程。计算过程最终就是来判断在某一个时间点当前的实际数据是否已经满足了规则触发的要求,如果满足要求就触发规则进行限流熔断。
对于规则,首先要考虑维度定义,而维度本身就是API接口服务运行实例的汇总统计数据,那么这些场景的维度包括了:
- API服务运行时长
- API服务单位时间的运行次数
- API服务运行数据量
而这三个基础维度本身又会进一步产生其它扩展维度,比如我们常说的最大数据量,评价数据量,运行失败次数,运行成功率,运行最大耗时等。
而对于具体的规则,我们希望最简单处理,即:
- 某一个指标 大于 或小于 我们预定的某一个阈值,就算规则满足。
其次就是可以定义复合规则。复合规则也简单处理为规则的与或处理,即:
- 规则1和规则2同时满足,就算整体规则满足
而对于规则本身的作用范围,我在前面已经讲到,即资源本身的不同粒度。规则可以最细化的作用到某一个特定的消费方调用的某一个特定服务,也可以是作用到某个服务所有消费方。
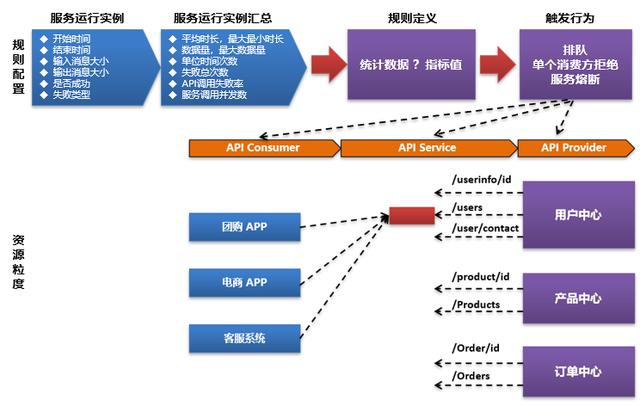
简单来说就是:规则+资源最终通过计算后触发限流熔断行为。
03-对计算逻辑的关键说明
在前面我们把规则和资源讲清楚后,再来看下具体的计算逻辑思路。
对于计算逻辑,我们可以将计算过程分解为多个独立的计算单元,然后多个计算单元的组合最终形成了完整的计算和处理逻辑。
大家可以看下,对于Sentinel限流熔断产品中的Slot概念正是可以理解为我们前面谈到的计算单元。Sentinel将各个Slot的能力最终组合在一起完成了一次完整的限流熔断逻辑处理。
对于计算逻辑,我们还是要回归到具体的规则配置。
比如,我们配置完成的规则呈现方式可能如下:
- 对于用户查询API接口,在5分钟内调用次数大于1万次即整体熔断
- 对于CRM系统消费产品查询接口,在10分钟内如果平均时长大于30秒则拒绝CRM访问
- 对于订单更新API接口,如果失败率超过1%则全部熔断
从上面的描述我们看了单位时间的概念,即当我们去触发限流熔断行为的时候,我们不希望是一次偶然的调用并发或异常就马上触发,而是希望是我们观察的一个单位时间段,如果持续发生某种异常行为才触发。
这个单位时间可以是5分钟,也是是10分钟,乃至1个小时。
也就是说我们最终统计的是单位时间的最终汇总统计数据。也就是说对于服务运行实例数据我们需要进行实时采集,采集完成后在基于资源粒度进行分类汇总,形成汇总数据。
那么如何汇总?
如果希望是统计1个小时,难道我们要在内存里面一直存储一个小时的实例数据,达到了1个小时的单位时间后再进行汇总处理?这个显然是不合适的。
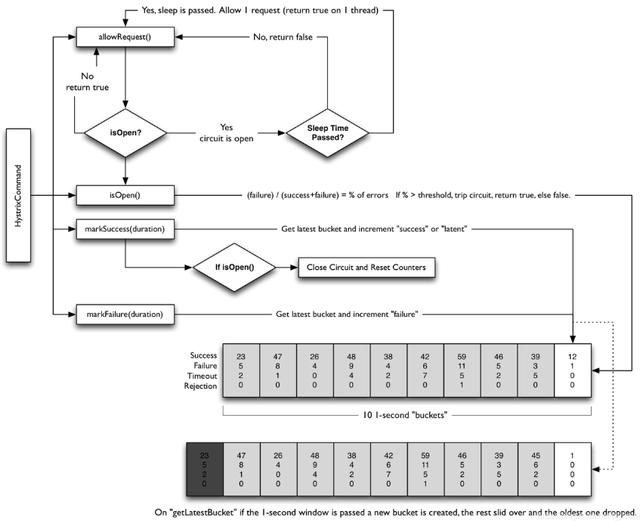
Hystrix滑动窗口计算逻辑
正是这个原因,我们再给出一个最小统计时间间隔概念,比如我们可以设置为10秒,我们先将10秒这个最小时间间隔的实例数据进行一次汇总,然后将第一次汇总后的数据放入到我们的滑动窗口数组里面。然后再基于规则配置,提取滑动窗口中的数据来进行二次汇总处理,最终判断配置的规则是否触发限流熔断操作。
限流熔断整体实现逻辑
在前面的内容讲解完成后,我们再来看下限流熔断的整体实现逻辑,你可以将这篇文章逻辑看做是当前主流的限流熔断产品的一个逻辑简化实现。
当然一方面是简化,一方面在资源控制颗粒度上反而是本文的方法会更加细化。对于整个限流熔断的处理逻辑流程,我们可以简化为下图:
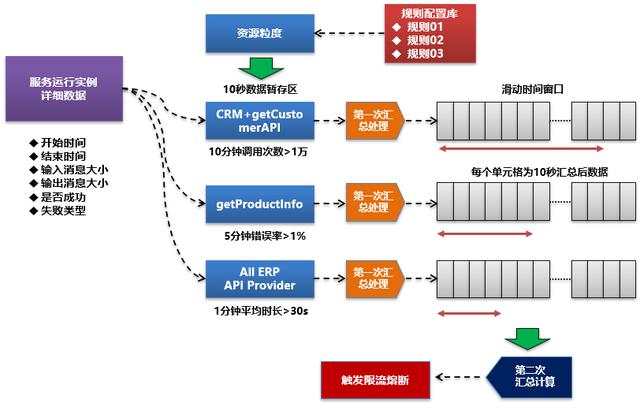
对于该图,实际可以看到,如果按 Slot计算逻辑单元划分的思路可以分为:
- 基于配置的规则将服务运行实例按资源颗粒度匹配要求存到实例数据暂存区
- 进行第一次汇总计算
- 将汇总数据推入到滑动时间窗口数组
- 基于规则配置进行二次汇总计算
- 对限流熔断是否触发进行判断和处理
我们再将上面的思路做一个简单的描述。
比如我们当前在限流熔断规则配置中配置了三条独立的规则,不同的资源颗粒度。
- 规则1:对于CRM消费getCustomer接口进行限流,10分钟调用>1万即拒绝
- 规则2:对于getProductinfo接口流控,5分钟错误>1%则整体熔断
- 规则3:对于ERP系统提供所有服务,1分钟平均时长>30秒则整体熔断
如果是以上三条独立的限流熔断规则,则我们需要配置三个不同的临时数据存储区和三个独立的滑动时间窗口区。
在朝10秒临时数据暂存区推送临时数据的时候可能会造成冗余,但是在限流规则本身不带来配置的情况下该方案反而是最优方案。毕竟在实际应用场景中,我们往往是在发现了明细的性能异常或问题的时候才会配置限流熔断规则。
比如,CRM系统调用getCustomer API接口。
当获取到这次实例数据的时候,我们将其推送到第一个缓存集合,如果该接口本身也是ERP系统提供的接口,那么我们会同时将该数据推送一份到ERP系统缓存集合。
对于缓存数据集,我们每10秒就做一次汇总处理。并将汇总完成的结果数据形成一条记录推送到对应的滑动时间窗口区。在推送完成后将该数据集数据全部清空或进行资源释放。
基于滑动窗口数据的二次数据处理
对于滑动窗口中的二次数据处理,我们可以在每次数据推送完成后就计算一次滑动窗口数据,比如5分钟规则,我们就获取窗口中最近5分钟的数据进行二次汇总,并判断二次汇总后的数据是否满足了相应的触发条件。
如果满足条件,就进行限流熔断处理。
限流熔断实现逻辑和API网关能力的解耦
最后谈下限流熔断实现和整个API网关能力的解耦。
简单来说,限流熔断本身也是一个独立的拦截器,对服务请求进行拦截,并判断当前限流熔断规则是否处于生效状态,如果处于生效状态就触发限流熔断操作,比如对访问请求进行拒绝。如果不生效状态,那么就放行服务请求。
那么整个限流熔断和API网关的集成关系,我们需要重新梳理如下:
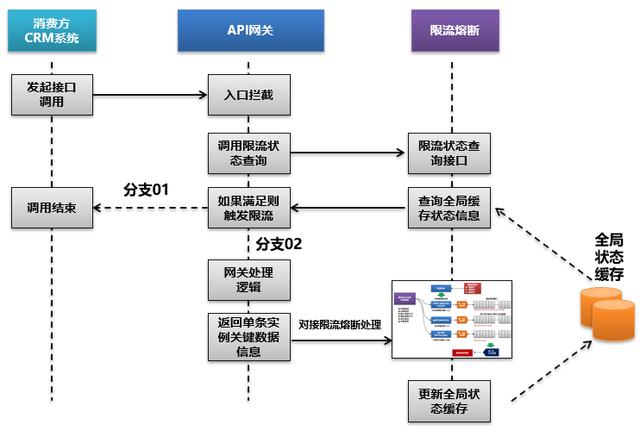
当然在服务本身被熔断后,我们还可以设置一个解除时间间隔,比如5分钟或10分钟,我们还需要设置一个定时任务来进行计算,当解除条件满足后,将全局状态缓存中的服务状态进行刷新,以对服务限流进行解除。
以上即是服务限流熔断逻辑实现的以下关键思考,供参考。