最近拜读了刘大1984很久以前的一篇文章。在认识交易系统的各个层面上,感觉又有新的提高。尤其是在讨论交易系统应对行情波动的方面,对交易周期和系统参数与以前的认识又有所不同。本文把我的体会记录一下。
为了能够在一个“频道”上去理解、分析问题,我在阐述内容之前,会对一些名词重新表达一下。也就是用我的语言,再对一些我们“耳熟能详”的名词进行重新“定义”。所以,可能有些内容我们在看的过程中,会觉得有些无聊。但把细节和最根本的定义理清,后面再讨论更深入的问题时就不会因为对名词的“歧义”而导致理解障碍了。
==========
这篇文章,我计划分成四个部分来阐述:
1,“周期”是什么;
2,“系统参数”是什么;
3,“周期”与“系统参数”的关系;
4,从波动的角度理解周期与系统参数。
==========
在讨论这个问题前,我要先聊一下“K线”。
什么是K线,这个大家恐怕都知道。
但是,为了更好的表达我后面的思路,我觉得我还是有必要先说一下K线(以下部分内容引用了讨论群里的一位朋友的讲解,我认为他对K线的定义很科学,完善了我对K线的理解)。
咱们提到的K线也叫bar(不是bra!╮(╯▽╰)╭)或kline。是由开盘价(open)、最高价(high)、最低价(low)、收盘价(close)和成交量(volume)组成的(我们暂时不讨论成交量)。
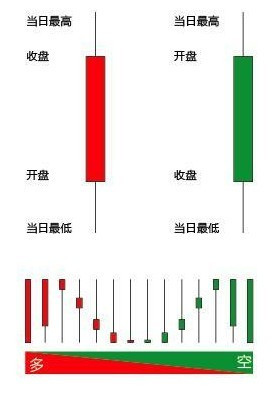
从开盘价与收盘价的相对位置来区分这根K线是“阳线”还是“阴线”。更基本的内容我就不赘述了。
我要谈的是,构成K线的4个价格本质上,是对一个时间段内所有成交价格的一个抽样。也就是说,这4个价格是从这一个时间段内所有成交的价格中按照规则抽取出来的。
抽取的规则是:
开盘价:对应着此段时间的起始成交价格(日K线通常是集合竞价价);
收盘价:对应着此段时间的最后一个成交价格(也有其他形式,如股票日K线就是最后3分钟的集合竞价价);
最高价:对应着此段时间内最大(max)的成交价格;
最低价:对应着此段时间内最小(min)的成交价格。
通过这4个价格,就将这一个时间段内价格的所有无序波动给“抽象”的描述了出来。可以说K线是个“抽象”的艺术!

我做了一个示意图。黑色的线代表价格在这段时间内的走势。我们可以看到,在K线上,开、高、低、收四个价格是一样的,但具体的细节走势确却是千差万别的。
不过,尽管具体的走势完全不同。但K线都描述出了一个统一的结果——价格涨了,且涨了多少可知;而且波动的大小亦可知。
用上图来说,就是把这段时间里,价格最高最低曾经到过哪;结束时,相对起始时价格最终是上涨了的,这些状态给描述了出来;并且可以计算出涨了多少,总体的波动是多大。
也就是说,K线刻画出了一段时间结束后,价格最终的痕迹和状态,但代价是牺牲掉了细节。
为什么要说K线呢?
因为,被K线忽略掉具体走势细节的这段时间长度,就是“周期”!
举例来说:
日线周期中的每一根K线代表的就是一个交易日。也就是,用一根K线忽略掉了一个交易日的交易细节。
小时线周期,则是每一根K线代表一个小时。即,用一根K线忽略掉了一个小时的交易细节。
所以,我要说的第一个问题,“什么是周期”,指的是K线所忽略的交易细节的时间长度。
----------
我们用的技术指标或交易系统一般都离不开参数。
比如,“20日简单移动平均线”这个说法,指的就是在日线周期中,用连续20根K线的收盘价来计算算数平均值。并且新的均值数据跟随最新的K线同步计算,形成“移动”的效果。
这里面的“20”就是参数。
它的意义其实就是在划定要进行统计的样本空间。
我们在使用技术指标的时候,都是有一个默认的前提的,即技术指标属于统计学范畴。通过对过去一段数据的统计和计算,得出一个描述性的数据。进而通过这个数据来判断过去一段时间内,价格的状态。
比如上面的“20日简单移动平均线”就是一个不断对新的20根日K线的收盘价计算平均值的过程。
我们来看张图:
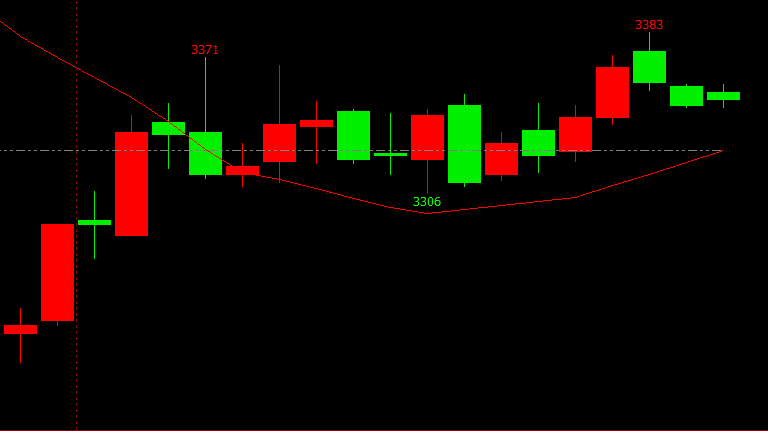
图中红色的曲线是“20日简单移动平均线”(后面都用20日均线作为简称了)。确切的说,我们看到的这条红色曲线是20日均线的历史轨迹。
真正当前应该看的均值其实是那条水平方向的双点虚线。
因为,这条虚线才是图中20根K线收盘价的平均值。我们从这张图上,也大体上能看出来,这条虚线将收盘价分成了上下两部分。数一下我们能看到有9根K线的收盘价是低于这条双点虚线的,同时有11根K线的收盘价是高于双点虚线的。
这就是对历史数据进行统计后,计算出的平均值。
所以,如果不确定一个参数,我们就无法选取历史数据的样本空间。只有确定了一个参数,我们才能够用统计学的方法去计量这个划定的样本空间内的数据情况。
从这里我们也能看出,很多量化人提到的“过拟合”,其实就是把过去的历史数据,用最合理的取样方法去划定样本空间。而这个怎么“合理地划定样本空间”的过程就是确定参数的过程,也就是过拟合的过程。
----------
我们在确定周期的过程,其实就是确定时间框架的过程。也就是说,我们在决定忽略哪些细节。
而系统参数的确定过程则是在划定样本空间的过程。
当这两者一结合,我们就知道了,我们是要忽略所选周期以下的交易细节,同时利用统计学的计量方法去研究上一级别周期的细节。
比如我们确定下来的时间周期是1小时周期,这表明我们忽略掉每个小时内的交易细节了。
如果我们选择的参数是120(假设一个交易日有6个小时交易时间)。也就是我们划定的样本空间是120根1小时K线。那么,120根K线除以6,就等于20天。
也就是说,我们研究的这120根K线其实是在对20个交易日里的细节情况进行研究。
来,看张图:

图中,上半部分是日线周期,参数为20的均线;下半部分是小时线周期,参数为120的均线。
我们发现,在日线收盘后,这两条均线的数据是很接近的(图中数据相同,是因为忽略了小数部分,通常会存在误差)。
也就是说,我们在选定的周期中,设置的参数,实际上是在研究更大周期所忽略的细节。
2014年金融帝国到清华做讲座。在讲座结束后,我有幸跟帝国攀谈了一会儿。帝国在讲座中谈到了,他在进行足够的品种分散后,放弃了参数分散。所以,我特意问了一下帝国如果不进行参数分散的话,是否考虑过周期分散。帝国的回答很直接:“周期分散本质上就是参数分散。”
我认为,这就是“周期”与“系统参数”之间的关系了。
----------
啰嗦了半天,终于到重点了!
这就要回到刘大1984的那篇《行情的四种类型》了。
文章中有一段对波动的定义,我认为是极好的。特引用如下:

我们在市场上交易,主要应对的就是行情的波动。无论是以应对震荡行情为主的回归类策略,还是以应对单边趋势行情为主的趋势跟踪类策略。我们都是为了锁定与我们策略相对应的行情而不断的分析、研究和判断的。
可以说,周期的选取,其目的是在忽略一定的细节后,在为统计更大周期的波动幅度做准备;而参数的选取,则是在为统计的时间跨度做准备。
当两者确定后,就可以对样本空间的波动性进行描述了。
这也是为什么有句话说“讨论行情,不明确周期,就是耍流氓”的原因。因为周期就是在划定波动幅度。
但如果只说周期而不谈参数的话,同样是无法将互相讨论的双方观点统一起来的。所以,如果要再有人讨论行情,最好先明确周期,然后再把参数带上。
当这两者准备好后,我们就可以用标准差、ATR等工具来计算波动性了。不过,这里我们也要明确,我们无论用的什么统计工具在计算,我们计算的结果都是样本空间的波动情况。这代表不了未来波动性就一定变或一定不变。
所以,我们还是离不开假设。
我曾经提过一个观点:行情在微观层面倾向于自我增强的趋势特性,在宏观层面倾向于阴阳循环的回归特性。
这里的“微观”和“宏观”的表述依然是很模糊的。
但其实要表达的意思就是,行情通常会维持某种状态运动一段时间,但这种状态一定会在某种情况下发生转变。
简单说,就是震荡行情通常都会震荡一段时间,然后突然转变为向上或向下的单边趋势行情。而这种单边趋势行情通常也会延续一段时间后,再在某种因素的刺激下,突然转变为震荡或者与之前方向相反的单边趋势行情。
这里面的“一段时间”就看我们选取的周期和参数了。两者结合能够更好的去描述这个“一段时间”的跨度问题。
那么我们的假设是什么呢?就是,假设行情会延续。并且为即将到来的转变做好防御工作。
比如说,我们发现波动性减小,那表明我们统计的样本空间中的价格呈收敛的态势,也就是说样本空间的价格是震荡状态。那么,我们就首先假设行情会继续震荡下去。并且,我们去定义一下这个震荡的边界。如果这个边界没有打破,我们就认为当前状态依旧是震荡。那么用震荡策略的话,只要关注这个边界是否被打破就可以了。同样的道理,在单边趋势行情发展过程中,波动性将会扩大,那么我们就假设单边趋势会继续延续。同时也为这个单边趋势的结束边界做好跟踪即可。
可以说,就是通过对样本空间的统计描述,来假设未来这种状态会延续,同时对这种状态的结束做好防御即可。
==========
说了很多,其实一句话就能概括:定义好周期,设置好参数,用一套标准化的交易规则去应对市场波动。
只不过,我们在认识交易、理解交易的过程中,总是会产生各种想法。而各种想法中,很多想法又会导致我们迷失方向。交易的过程就是一个提高认知的过程。思考的过程很复杂,但结论其实很简单。如果只抛结论,那么对不了解结论产生过程的人来说,就难免产生一种不坚定。而这种不坚定则是诱发“学习效应”的罪魁祸首。
关于学习效应,大家可以看看金融帝国的《走出幻觉走向成熟》。