
随着大数据时代的悄然来临,大数据的价值逐步得到广泛认可。有效管理大数据,沉淀成数据资产,对内可实现数据资产增值,对外可实现数据共享变现,是企业的通用诉求。
然而,企业在管理底层数据时,经常会面临各种挑战:各业务系统分散,形成信息孤岛;未制定统一的数据标准;数据处理能力薄弱;数据没有互通互联,难以建立数据共享机制。
本文就来聊聊大数据管理的两个重要概念:数据仓库、数据治理。
(上)数据仓库
| 数据仓库是什么
数据仓库是基于数据库的建设过程,是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。
未建设数仓前,需要对多个源表进行查询分析,查询慢,数据质量差,无法进行高价值的数据分析。通过建设数仓,可以在一个地方快速访问多个系统源数据,快速响应OLAP分析;提高数据质量和一致性;能够提供历史的数据存储;更有利于进行数据价值挖掘和数据分析。
| 数据仓库与数据库区别
数据库是面向事物的设计,更关注业务交易处理(OLTP);而数据仓库面向主题设计,更关注数据分析层面(OLAP)。
数据库一般存储在线交易数据,数据仓库反应的是历史信息,存储历史数据,不可修改。
数据库尽量避免冗余,而数据仓库有意冗余,通过空间换时间。
以银行业务为例,客户在银行的每笔交易需要写入数据库记录下来,起到“记账”的作用,是事物系统的数据平台;而数据仓库是分析系统的数据平台,它从事物系统获取数据并汇总加工,支持分析决策,如某分行每月发生多少交易、当前存款余额,以此来决定是否需要增加ATM机。
| 数据仓库整体框架
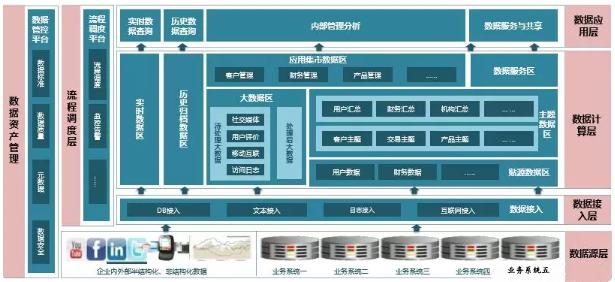
数据源层:
盘点数据仓库需要接入的数据源,数据库、结构化电子文件、非结构化数据文件、行为日志等。最终在接入数据仓库时,所有的数据类型都会转化成两种数据格式:数据库表和电子化结构化文件。
数据接入层:
按上层应用场景不同,接入可分为实时接入和批量接入。
实时接入:对于实时接入的数据,以流式的方式写入kafka,创建Topic供后续消费;
批量接入:对于批量接入的数据,主要有4种处理逻辑:
写入Kafka的数据被spark消费,处理后写入HDFS,然后load至hive表;FTP方式批量传输;利用sqoop将数据库数据批量迁移至HDFS或hive;数据共享交换平台提取数据库或文件数据进行入库。
数据计算层:
ETL任务开发,按需生成对应的事实-维度表或集市层表。业内通常将数据仓库构建为4层架构:
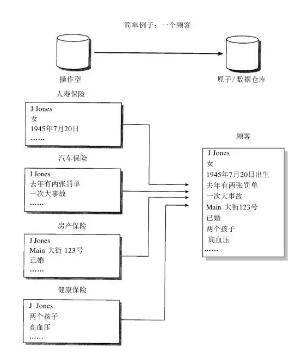
图:ODS到DW的集成示例
数据应用层:
基于数仓的顶层应用有很多,例如:
(下)数据治理
| 为什么要进行数据治理
将分散、多样化的核心数据通过数据治理技术手段和产品工具进行优化,形成企业内的数据管理体系,并结合企业组织结构,形成数据管控执行体系,在企业内部持续运行、提升挖掘数据的应用价值。
数据治理最终达成的目标可以归为以下六点:
| 如何进行数据治理?
数据治理的三要素:数据标准、数据质量稽核、元数据管理。下面逐一展开来讲。
数据标准
从业务角度定义,如设备类、会员类数据,不同渠道来源但同一含义的要统一口径规范、数据与数据之间的规范;
从技术角度定义,表、字段、字段格式等都要统一规范,如:ID信息、手机号、身份证号等。
数据标准来源可以是国家标准、行业标准,也可以是基于业务的企业标准。
定义完数据标准后,对于新新建设的数据平台,要采用统一的数据标准;对于已存在的业务系统,在不影响线上的原则上,逐步数据标准接轨。标准执行后,要长期稽核监测,并输出数据标准校核报告。

图:数据标准管理周期
数据质量稽核
以数据标准为数据管控的入口,依据数据标准定数据质量检核规则。对于数据的稽核,有以下八类稽核规则,前六类是单表级校验,后两类是多表级校验:
元数据管理
元数据就是定义数据的数据,比如一本书的书名、作者、出版社、出版时间都是元数据。
Garbage in,Garbage out。这个是永恒的真理。只有将底层的基础数据管理好,才能更有效的支撑上层的大数据应用。
作者:Herman Lee 沉淀个人的产品方法论












