编者按:直播已深入每家每户,以淘宝的直播为例,在粉丝与主播的连麦互动中如何实现无感合屏或切屏?LiveVideoStackCon 2022音视频技术大会上海站邀请到了阿里云GRTN核心网技术负责人肖凯,为我们分享GRTN核心网的运作机制、运用方面以及QOE的网络模型在业务板块的实践优化。
文/肖凯
整理/LiveVideoStack

大家好,欢迎大家来到 LiveVideoStackCon 2022音视频技术大会上海站,我是来自阿里云的肖凯,现在负责阿里云的GRTN的传输引擎的开发以及组网架构。今天讲解主要分两个版块,一方面简单介绍一下GRTN的理念和提供的能力。另一块就是阿里云的GRTN在接待客户的过程中,是怎样去优化QOE的指标。

今天的分享主要分为几块:GRTN简介、阿里云做QoE的优化经验、赛马系统、和阿里云的一些可编程的能力。
1、GRTN简介
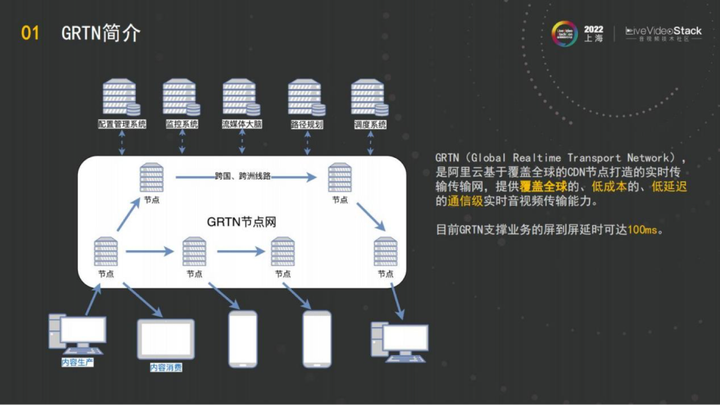
GRTN实际上现在是一张全SFU的网络,我是从 15年开始做直播这一块,伴随阿里云直播系统一路做到现在的通信级的传输分发网络。
现在的阿里云的GRTN基于覆盖全球的2800多个边缘节点,我们把这些节点和网络资源运用起来,做成了一张通信级的SFU的传输网络。
这些节点,包括解决跨洲的网络问题,都有专门的线路,整个系统都是从直播演进过来,过去很多的 CDN直播网络一般都是树状的结构。但阿里云的GRTN是一张树状和网状结合的动态网络,目前阿里云GRTN支撑的屏到屏延迟是100毫秒左右,满足云游戏或者云渲染这样的场景。
GRTN的能力很简单,它提供的是内容的传输和分发。任何一个用户使用RTP协议,把媒体推到阿里云GRTN的节点,它就可以在全球的任何地方就近地从GRTN把内容拉出去,GRTN会解决动态组网、就近接入等问题。
2、GRTN当前业务模式
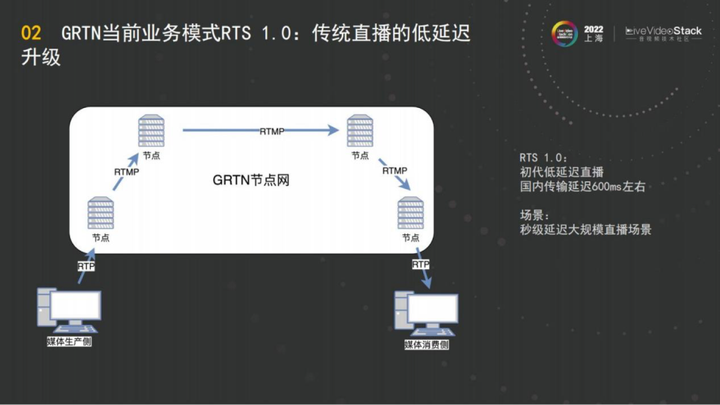
GRTN的当前的业务模式,目前很多客户接的都是阿里云的RTS 1.0,即在阿里云官网能够看到的RTS业务。
RTS 1.0是阿里云从18年左右开始研发的,它的核心理念是为了帮助客户在有限改造的前提下,接入GRTN,把延迟降下去。传统的直播FLV延迟大概在5秒, HLS更多,延迟达到20s 左右。RTS就是对推流侧或者播放侧进行改造,最重要的还是播放侧协议换成RTP,能够做到延迟在1秒左右,这个技术在19年左右淘宝直播已经全量落地。
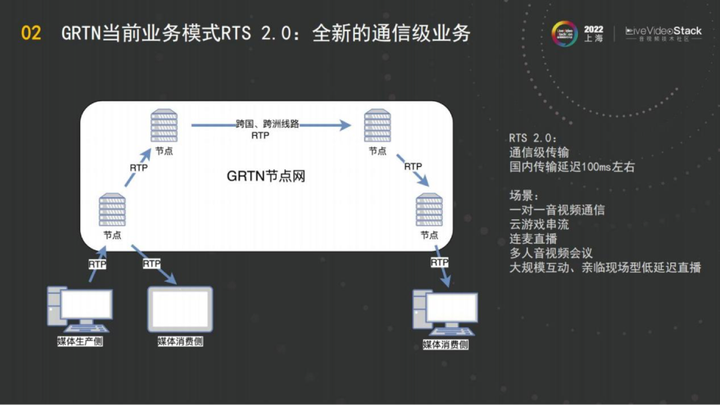
RTS 1.0结束之后,阿里云就进入到了RTS 2.0的时代。RTS 2.0里,我们对实时流媒体这个场景的预期是没有RTC和直播的区分,可以让所有的业务都建立在全链路RTP的协议上。全链路使用通信级的传输,是GRTN的技术理念。目前的RTS 2.0,它是具有通信级的服务能力的。
RTS 2.0的传输延迟在国内基本是在100毫秒左右,即为节点的传输耗时,剩下的延迟就可以放在编码侧或者放在播放侧,用来抗抖动。这样的场景一般用在一对一的通视频通信,或者多人会议,包括连麦直播一体化。
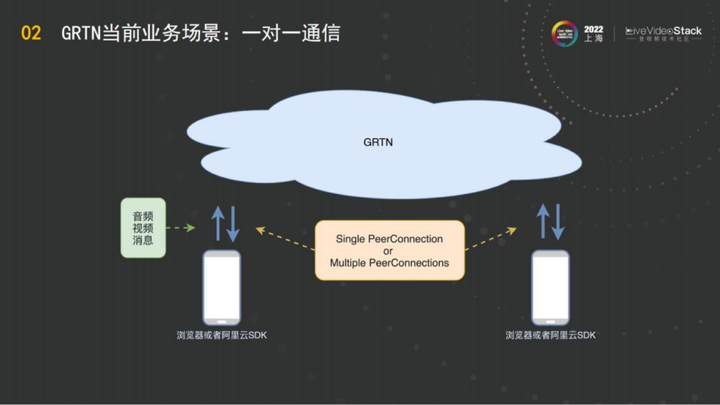
那在GRTN上怎么把一对一通信做出来呢?
阿里云GRTN的对外服务包括两种模式,一种是阿里云的SDK,通过使用GRTN的私有协议,另一方面,阿里云也支持浏览器,GRTN的生态是完全开放。用户可以使用浏览器,以标准的SDP信令交互的方式与GRTN的对接,把媒体推进来,再通过GRTN选择性地把媒体拉出去。两个客户端跟GRTN可以选择通过单PC或者多PC的模式交换音频、视频或自定义的消息,通过GRTN实现通信级的传输,这就是一对一通信。
这个模型并不仅限于通信,还包括云渲染,云游戏的模型。
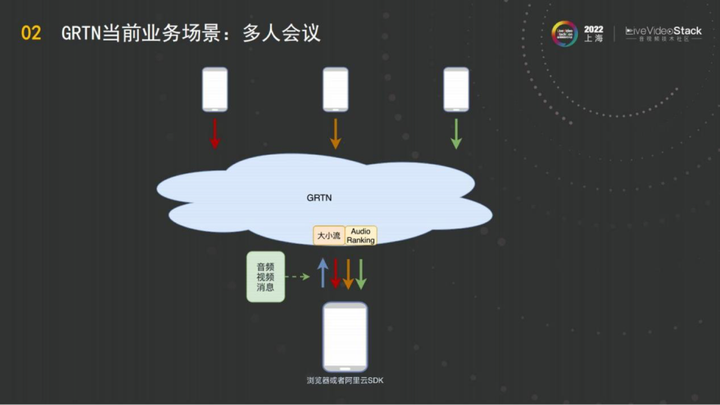
在一对一通信的基础上,GRTN支持多人会议,如图所示,这里有4个参会方,这里会讲解多人会议在GRTN上需要怎样的能力。
在参会人比较多的时候,通常而言选择性的订阅对端的视频、音频是一个很麻烦的问题,因为涉及到Audio Ranking。很多业务方为了做这种多人会议,不得不把音频放到一个专门的Ranking Server上去做。GRTN提供了大规模的Audio Ranking能力,也就是说任何一个端在GRTN上消费音频,都可以做到为它进行Audio Ranking。这个人订阅了什么,GRTN就在这个人订阅的音频中进行Audio Ranking,不涉及Ranking server, 不增加延迟。
GRTN的另一个重要能力是切流。GRTN可以为任何观众实现他的媒体的替换,在云合流的连麦场景,这是一个很核心的能力,在一个浏览器上,观众通过GRTN在看一个人的画面,然后通过切流的指令,就让这个观众在完全无感的情况下实现画面的切换。
这就是GRTN的切流能力,这个能力可以为GRTN上某一个主播的所有观众实现媒体画面的实时切换,可以从a画面切到b画面,从a主播切到b主播,观众是完全无感的。
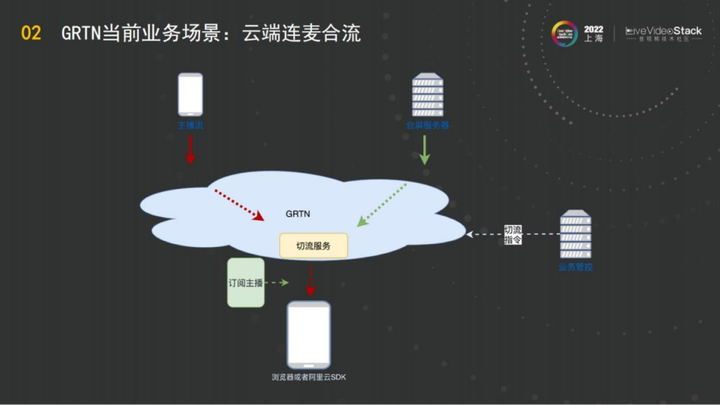
接下来我们看如何用切流能力实现云端连麦合流?在连麦这个场景上,如果是客户端的连麦,那就是ab两个主播进行连麦,观众在看a主播的过程中他们一连麦,观众看的画面就实时变成了a和b合屏的画面。这种场景能够简单的实现,通过端合流,即a主播在端上直接把自己的画面更改,观众看的内容相应进行变化。但是存在一些场景端合流是无法做到的,例如端的性能不够,这样场景下就需要通过云合流。
如图所示,一个主播流的画面推送到GRTN之后,有一个观众在看主播的画面,当这个主播和别的粉丝发生了连麦,连麦之后有一个业务方的合屏服务器,合屏服务器会把两个媒体合成一个。在这个时候就需要实现客户端的画面切换,而且全部都要切过去,这个时候我们提供的能力是切流指令,即前面所讲的切流的能力。切流指令传输到GRTN之后,GRTN将主播所有观众的画面无感地切换成合屏流的画面。
这个能力目前是实现淘宝直播在GRTN上直播连麦完全一体化的基础解决方案。
这是一个通用的方案,在后面随着GRTN和后续RTS 2.0服务的对外输出,这个能力会直接对外开放。
在这里和大家简单介绍一下淘宝直播的情况,淘宝直播实际上已经实现全量在通过GRTN进行,任何一场直播里观众和主播之间的延迟基本上都在1秒以内的。这个目前是GRTN在 RTS 2.0上的一个典型的场景。
3、QOE概述及优化难点
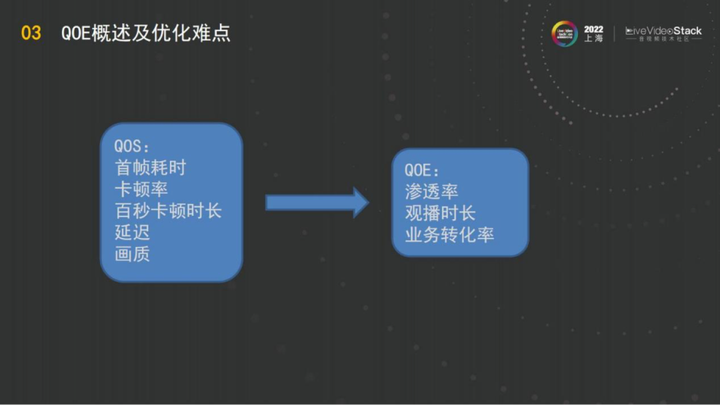
QOE的一些优化实际上就是基于阿里云的外部客户的数据,为什么讲QOE而不是QOS?因为我们在接待客户的过程中发现,QOE通常都是客户本身制定的一系列的指标,比如说渗透率、观播时长、业务转换率,这些指标不是把QOS某个指标做好了,QOE就能变好。
例如GRTN在接客户时,发现我们的首帧卡顿、百秒卡顿时长、延迟、画质全方位的领先,RTS的QOS一定是全方位的比FLV要好,也就不用说比HLS了。但在面对不同的客户的时候,有的客户他说他的QOE正了,有的客户说他的QOE有问题,因为在客户从传统的FLV过渡到RTS以及RTS 2.0之后,他们会因为客户端的适配没有做好,或者说业务场景的磨合没有做好,遇到了一些问题。例如 WebRTC来进行通信,播放器的buffer的机制可以做得非常的激进,但是当在直播场景时,观众的体验可能比你的激进的延迟控制更加重要,所以在直播场景下更多的是要去做一个平衡。
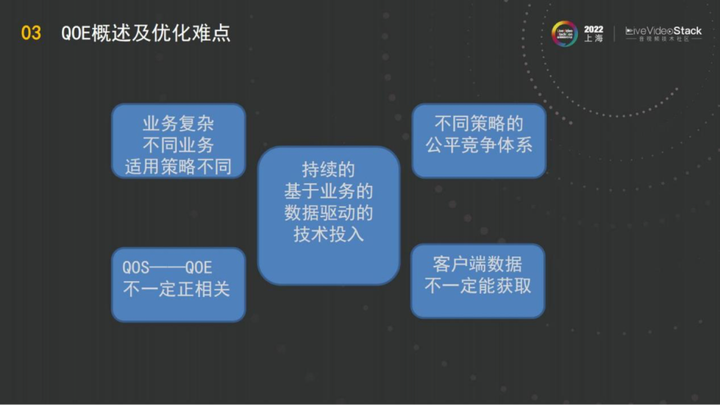
在这个过程中,我们发现有时候客户把QOS全做正了,但是QOE却还需要花很多的时间去处理,所以在把QOE做正的过程中,要用的什么方法?
这是在QOE里阿里云要持续投入的。想要做好QOE一定要有业务输入,没有业务的输入,没有业务的反馈,QOE肯定是做不正的,所以阿里云有一个持续的基于业务的数据驱动技术投入这个板块。
这里最重要的一点就是客户端的数据,在做QOE的过程中,我认为服务端是没有资格说QOE的,只有客户端和业务才有资格说自己的QOE这么正。所以在这个过程中,GRTN的方法是先得到业务方的脱敏数据,然后去做QOE(最后会有一个数据的展示)。
4、GRTN QOE 优化理念

GRTN优化QOE的一个理念是,GRTN做到了无感的链路切换。
GRTN内部是一个全SFU网络,上游的网络随时切换,对观众来说是完全无感的。同时还有强实时的主备链路。在很多直播、通信场景下,会有重保的概念,或是强实时的双路保障。如果节点之间出现问题,能够立马把它切到另外的节点链路上,这样观众完全无感。
还有GRTN节点和客户端之间的mobility的方案,例如某个节点可能网络有问题,或者客户端的网络发生了wifi到4G的切换,那么使用一个mobility的方案瞬间能够切换节点,同时GRTN的下游消费者完全不受影响。
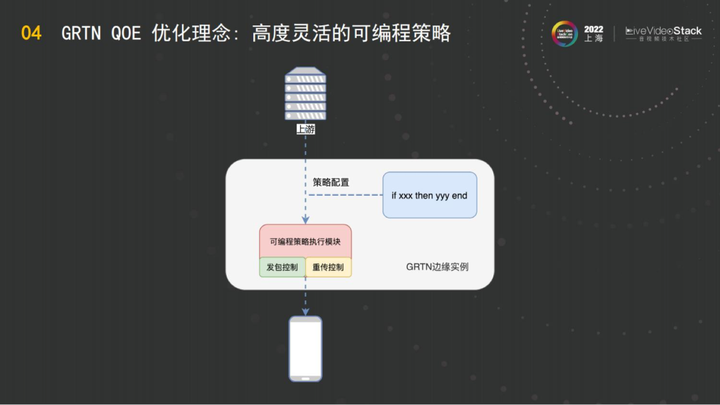
GRTN另一个优化QOE的方法,就是可编程策略。可编程实际上是我们近一年做出来的一个成果。传统的QOS优化能力,例如启用BBR还是启用GCC或者是别的拥塞控制算法,会发一堆的配置下去,配置里面全是开关。但是现在GRTN,可以在边缘直接用可编程的策略执行模块,类似CDN有可编程的能力,包括边缘脚本之类,GRTN也类似,但是做的比较彻底。现在的能力是可以在节点直接下发策略,运行语言,可以直接对发帧和发包逻辑做控制,可以介入到重传逻辑中,直接编程GRTN的对每一个客户端的行为,即通过策略配置系统直接把代码发下来。无需软件发版升级,因为像2800多个节点,是无法高频升级软件版本的,但是利用GRTN可编程能力可以实现一天几个策略迭代,结合客户端的数据,能够实现数据的打通。这样发策略下来,客户端拿到QOE的数据反馈给GRTN,GRTN的调优人员就知道如何去进一步的优化。
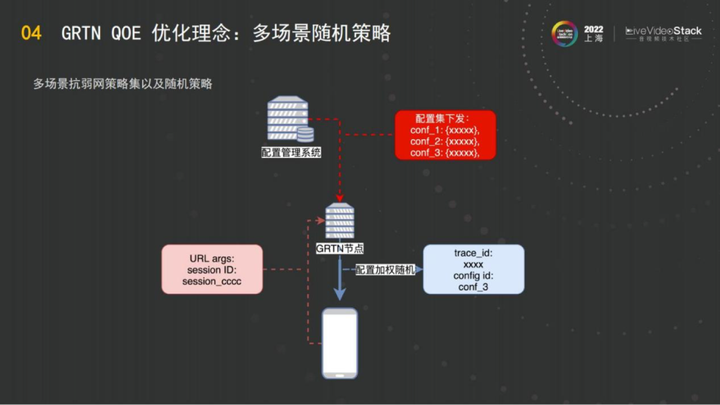
如图是GRTN的一个多场景的随机配置,也是基于阿里云线上海量的业务数据来进行的。例如阿里云线上的配置管理系统会把配置集下发,这是做AB的基础能力。后面配置管理系统会将n组配置实时发到全网所有的边缘节点,针对的是某一个域名。针对这个域名,同时给他发出三组配置下去进行随机,可能会配一定的权重。例如阿里云认为conf_1 是个高风险的配置,一个高风险的新型的功能,发出去之后,把conf_1指配全网1%的业务量去做 AB。发到节点之后,当任何一个消费者来到GRTN消费内容时,将对它进行一个随机加权的选择,它有一定的概率使用conf_1,也有一定的概率使用后面两种。
第一步的请求完成之后,我们让多组配置同时在线上运行,但是运行完后怎么拿到结果呢?
简单的方法就是客户记录我们的trace_id,GRTN有一个trace_id的理念,这个ID对应客户端的这一次播放,任何两次播放的ID都不一样。
另一种方法是客户端把一个session ID带在它的请求参数里面,这样一个客户端就在GRTN有一个session ID跟trace_id对应,这次播放用的什么conf ,我们也能够给它记录到。同时这次播放,根据session ID,我们就可以从客户端的埋点查到它的QOE结果。
5、GRTN 赛马系统

接下来对它做关联,播放器在GRTN上完成播放之后,播放器这边开始埋日志,他们埋的核心日志就包括首帧耗时、百秒渲染卡顿,也包括任何一个播放端的播放时长。在业务方记下来的日志中,它知道这个session id对应的这一次播放播了多久,它的各项指标怎样。在GRTN就知道发的trace_id是哪个,然后针对这一次播放,缓冲深度配了多少,以及丢包率目前统计下来是什么情况。
这两个数据(服务端日志和客户端日志)把客户的日志收上来,抛送给我们之后,这边就把session ID和trace_id在GRTN的数据分析体系里面做一个综合,就得到了一个结果:任何一次播放它对应的服务端的网络情况是什么,它对应的客户端的首帧耗时、百秒渲染卡顿、播放时长是什么。GRTN就通过这两种数据综合把客户端的数据和服务端的一个行为做到了关联。
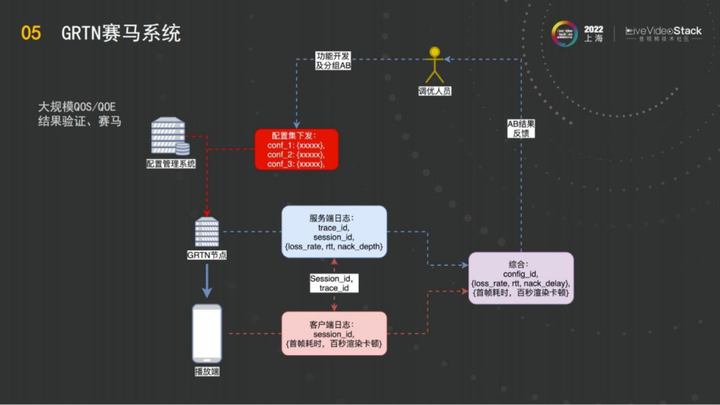
关联做到之后,下一步就做赛马系统。在任何一次配置的时候,就像现在阿里云给客户做调优的时候,我们会事先跟客户说一下要为你做调优。
例如说在这样一次配置中,以客户线上的业务为例,conf_1是一个高风险的功能,conf_2是对现有功能比如BBR的参数的调优,conf_3启用的可能是GCC。把配置发到节点,客户在进行播放之后,针对上两步把他的客户端和服务端的数据拿到之后,采集到GRTN这边,数据上传来之后,再对AB的结果做一个综合的分析。这个时候在研发人员的眼里就已经明确的知道下发的各组配置它的效果到底如何,区别是什么。研发调优人员就能够知道怎么去做进一步的调优,同时反馈哪一组配置可以被淘汰,再基于好的配置对它进行进一步的调优。所以这也就是赛马系统的价值——能够基于客户端的数据和服务端的数据进行综合的持续的迭代。
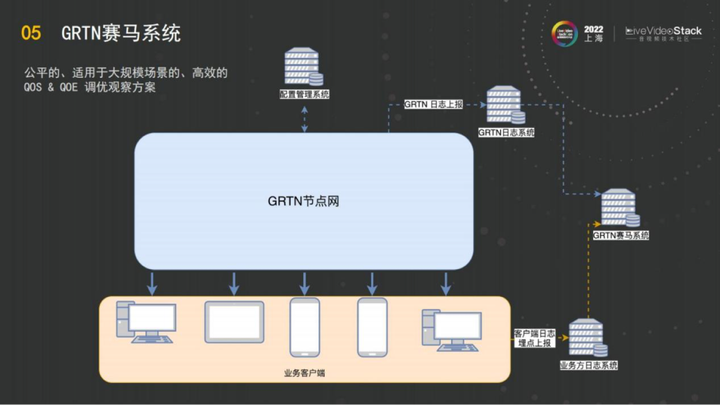
如图是赛马系统,它作为一个整体,有GRTN的节点网,服务客户端上报数据和GRTN的日志系统打通,做到相互配合。
6、GRTN QOE 优化案例
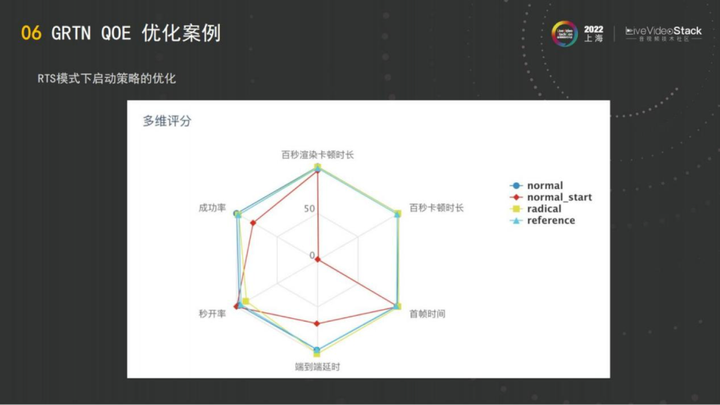
这是GRTN的一个优化样例,也就是赛马系统的评分。当时我们做实验有4组,normal就是平时日常运行常量的配置,radical就是一组非常激进的配置,reference就是用来跟radical进行对比的参照。如图做了一个六维的展示,也按照我们的想法对它进行了综合打分。

更详细的结果是这个表,刚才提到的conf_id配下去之后,运行完之后,接下来得到成功率、秒开这样的一些数据。这就是GRTN目前展示出来的赛马系统能够看到的数据。
成功率、秒开、都属于QOS的范畴,最后的平均播放时长,是属于QOE的范畴。我们测试下来得到的radical这一组的数据是最好的,它在播放时长上可能有1秒钟左右的优势,积累了24小时的数据,大概几十万的量级,我们认为这个量级的播放是可以用于支撑AB的数据。GRTN最开始在手淘场景做这个系统,手淘的业务量比较大的,所以我们从一开始拿手淘的线上的全部量级去运行。现在是直接可以拿外部客户的数据去运行,做成赛马系统,将阿里云可编程的能力,客户端的数据采集,包括赛马,做成一个闭环。
现在优化的方法,想要优化某种策略,就发一组配置下去。例如发一组配置,运行一个晚高峰,到了第二天就能拿到数据结果,这样的一个过程实际上对迭代的优势是非常大的。
例如今年3月份左右,我们给某个客户在调优播放时长的时候,通过分析客户端的一些行为,包括通过测试对数据进行分析,发现客户的音视频同步可能有点问题。怎么去解决这个问题呢?我们认为通过服务端的发帧策略的调整能够帮助客户端更好地实现音视频同步。我们用可编程把这个策略做好发出去,在第二天这个效果是非常好的。我们发现发下去之后,这组配置的观众播放时长升高了,这其实就是QOE的一个优化。
在这个基础上就完成了第一轮的迭代,我们认为这个路线是对的。接下来就是在这条路线上,怎么把参数进一步的调优。在最开始对发帧的策略进行调整之后,我们只是做了一个粗调,觉得大概可以弥补客户端的某些缺陷。实现了之后,接下来做进一步的不同的配置,不同的参数之间去做调优。