

机器视觉作为人工智能发展中重要的一部分,负责将我们人眼能够看到的世界转换为机器能够感知的世界,经过这一转换,机器就可以很好地对客观世界进行认识和改造了。这个过程看似简单,实际蕴含的底层知识却比较复杂。下面让我们一起来对这一神奇过程进行探究吧!
若想实现机器视觉,首先就要搞清楚大致流程是怎样的。比如,我们要实现机器对某一个物体的识别,我们可以通过下面的简图进行过程展示:
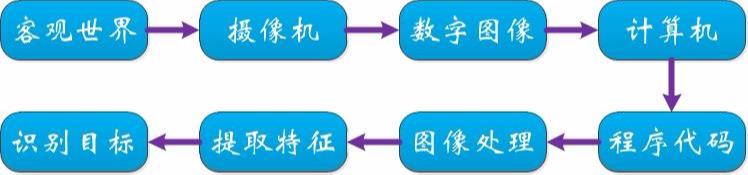
机器对物体识别过程示意图

机器对物体识别过程示意图
首先使用摄像机等设备对客观世界的物体进行采集,采集到的图像为数字图像,然后将数字图像传入计算机等运算设备上,配以程序以及一些处理函数库 ( 如开源的图像处理库 Opencv 等 ),对数字图像进行处理,并结合一些算法库函数对数字图像进行特征提取等操作,最后便可以将物体识别出来了。

工业相机镜头
在了解了大致过程之后,我们就从代码知识的层面来具体实现吧。
先放上核心代码:
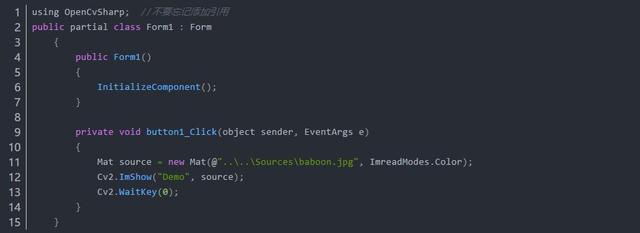
图像的载入与显示核心代码
再来看看运行结果如何吧!

图像的载入与显示运行结果
怎么样?是不是很简单,却又很神奇!
今天我们初步了解了机器视觉的部分基础知识,知道了机器识别物体的大概流程,也初步认识到了一张数字图像是怎样载入和显示的。下一篇文章,我们就来了解一下相关软件和编程环境是如何搭建起来的。
今天就到这里了,我们下篇再见!
















