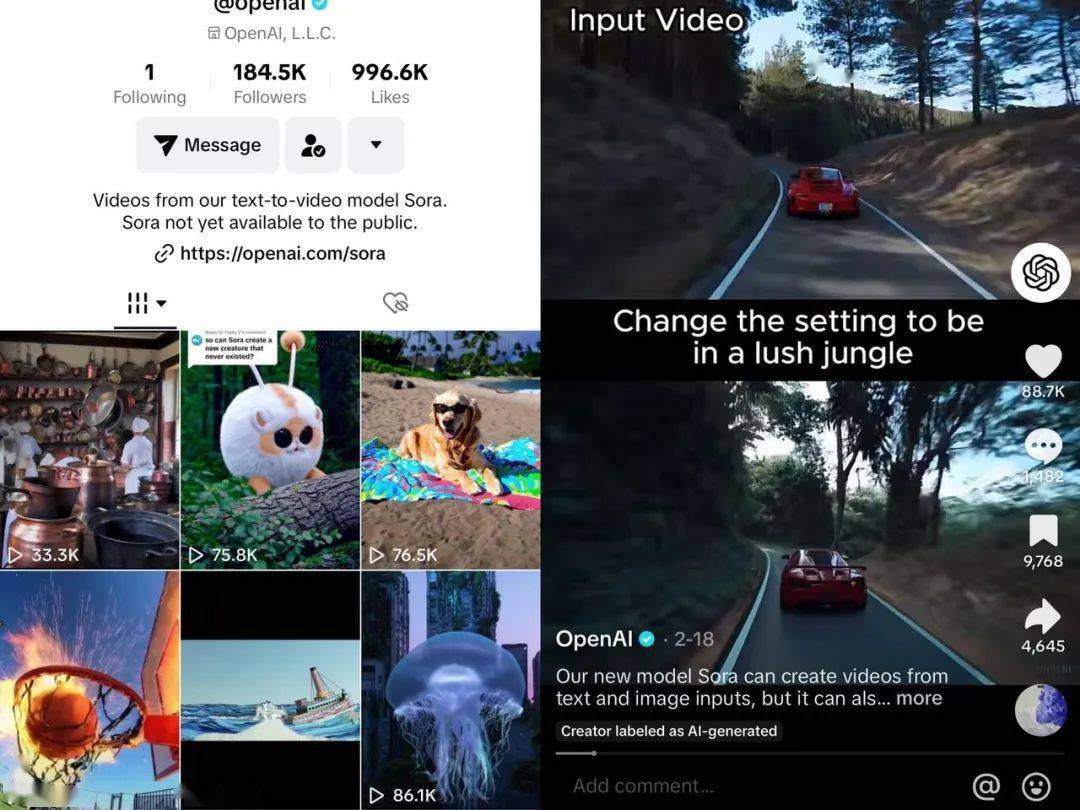
北京时间16日凌晨,全球人工智能模型领跑者AI target=_blank class=infotextkey>OpenAI推出了一款能根据文字指令即时生成短视频的模型,命名为Sora。此前在2023年轰轰烈烈的多模态AI模型竞赛中,谷歌、Meta和初创公司Runway、Pika Labs都发布过类似的模型。但本次OpenAI展示的视频仍然以高质量获得关注。
目前OpenAI官网上Sora相关的信息有限,OpenAI没有给出训练模型的素材来源,仅表示:“我们正在教AI理解和模拟运动中的物理世界,目的是训练模型,帮助人们解决需要真实世界交互的问题。”并称Sora能够从文本说明中生成长达60秒的视频,并能够提供具有多个角色,特定类型的动作和详细的背景细节的场景。 Sora还能在一个生成的视频中创建多个镜头, 体现人物和视觉风格。
此外,Sora可以一次性生成整个视频,也可以扩展生成的视频,使其更长。 OpenAI表示:通过让模型一次生成多帧画面,我们解决了一个具有挑战性的问题,即:即使生成的主体暂时离开视线内,也能确保主体不变。
OpenAI同时提示:当前的Sora模型也有弱点。它可能难以准确模拟复杂场景中的物理现象,也可能无法理解具体的因果关系。例如,一个人可能会咬一口饼干,但咬过之后,饼干上可能就没有咬痕了。该模型还可能混淆提示的空间细节,例如混淆左和右,并可能难以准确描述随时间发生的事件,例如跟随特定的摄像机轨迹。
关于OpenAI的CEO山姆·奥特曼一直呼吁的AI安全问题,OpenAI表示“目前,Sora已经开放向‘红队人员’(对AI大模型潜在的有害输出进行“红队测试”)以评估关键领域的危害或风险。我们还允许一些视觉艺术家、设计师和电影制作人访问,以获得关于如何改进模型的反馈意见,使其对创意专业人士最有帮助。”
Sora生成视频效果如何?
OpenAI表示,Sora建立在过去对DALL-E和GPT模型的研究基础之上。它采用了DALL·E 3的技术,能够在生成的视频中更忠实地遵循用户的文字说明。除了能够文生视频外,该模型还能根据现有的静态图像生成视频, 并能准确、细致地对图像内容进行动画处理。该模型还能提取现有视频,并对其进行扩展或填充缺失的帧。
目前OpenAI官网上已经更新了48个Sora生成的视频demo,色彩艳丽,效果逼真。

来自OpenAI Sora的AI生成视频图像:猛犸象在雪地中行走
以上截图的视频文字提示如下:几头巨大的长毛猛犸象踏着雪地走来,它们长长的毛发随风轻扬,远处是白雪覆盖的树木和壮观的雪山,午后的光线伴着飘渺的云朵和远处高悬的太阳,营造出温暖的光晕,低机位拍摄的景象令人惊叹,捕捉到了大型毛茸茸的哺乳动物,摄影和景深都非常漂亮。
动态的光影表现也有印象深刻的案例,如一位女性在东京路灯的霓虹灯下行走的视频,以及阿马尔菲海岸教堂的鸟瞰图,以及一个卡通怪物好奇地跪在融化的蜡烛前等。
来自OpenAI Sora的AI生成视频图像:一位女性在东京路灯的霓虹灯下行走
以上截图的视频文字提示如下:一位时尚女性走在东京的街道上,街道上到处都是温暖的霓虹灯和动画城市标志。她身穿黑色皮夹克、红色长裙和黑色靴子,手拿黑色钱包。她戴着太阳镜,涂着红色唇膏。她走起路来自信而随意。街道潮湿而反光,与五颜六色的灯光形成镜面效果。许多行人走来走去。
奥特曼在线接单
Sora公布后,OpenAICEO山姆-奥特曼请社交媒体用户在线发送文字提示的创意内容。
如一位来自新罕布什尔州的自由摄影师在X上给出的提示:“由一位祖母级社交媒体博主进行的自制意式团子烹饪指导课,场景设置在乡村风格的托斯卡纳乡下厨房,并配有电影级灯光。”Altman在约一小时后回复了一个逼真的视频。
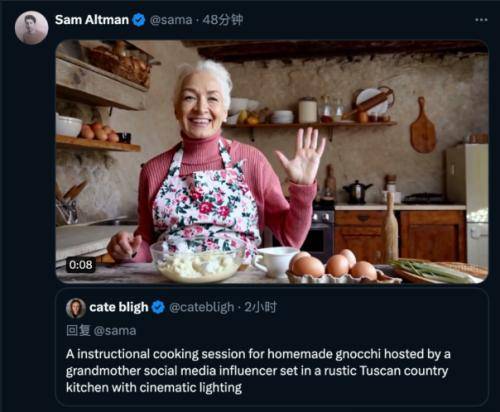
奥特曼此举,对外展示了Sora模型即时生成视频的能力。
东吴证券观点此前表示,近年视觉算法在泛化性、可提示性、生成质量和稳定性等方面突破将推动技术拐点到来以及爆款应用出现。3D资产生成、视频生成等领域受益于扩散算法成熟,但数据与算法难点多于图像生成,考虑到LLM对AI各领域的加速作用以及已出现较好的开源模型,2024年行业或取得更大的发展。
2023年末至2024年初,Pika、HeyGen等AI文生视频应用陆续出圈,验证了多模态技术的不断进步与成熟。刚刚公布的的Sora模型无疑加剧了这一赛道的激烈竞争。
来源:财联社