谷歌聊天机器人Bard能力提升 除语言处理外还可生成图片
谷歌近日宣布,其聊天机器人Bard的能力又向前迈进了一大步。除了先前的技能之外,Bard现在还具备了生成图片的能力。新增的图像生成功能将在全球受支持的地区免费提供,由谷歌Imagen 2模型提供支持,但需要英语指令。
用户可以根据向Bard提供的描述生成自定义图像。谷歌表示,Imagen 2和Bard都使用“负责任的人工智能”,Imagen 2不会生成暴力、攻击性或包含色情内容的图片,并接受了一些“培训”,以帮助其避免创建特定人群的图像。
为将Bard生成的AI图片与人类作品区分开来,谷歌将嵌入“像素级别”的数字可识别水印。除此之外,Bard在此次更新之后,谷歌Gemini Pro模型新增了40多种语言、230多个国家和地区的支持。同时,Gemini Pro增强了Bard的理解、总结、推理、创意、协作和规划方面的能力。
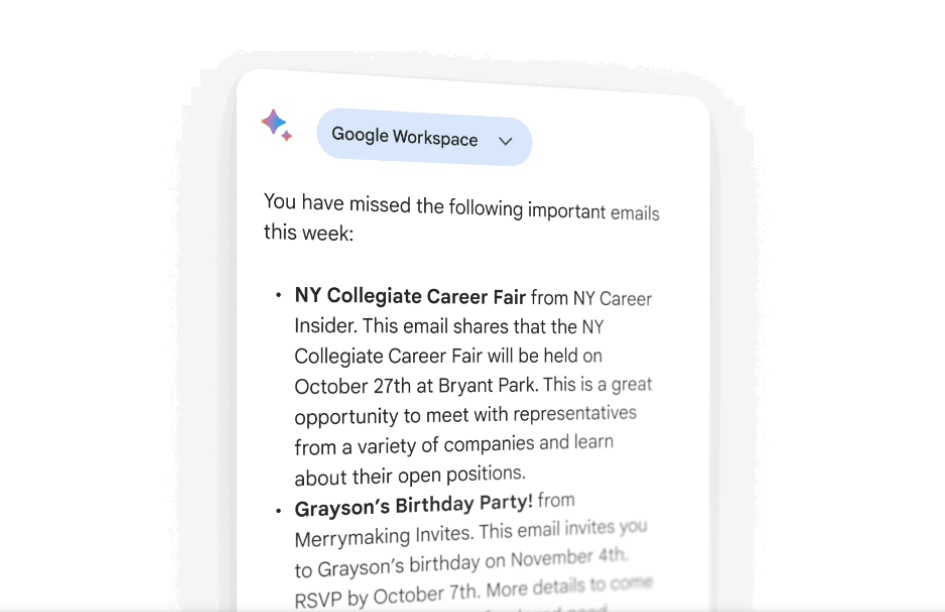
此外,谷歌还将Bard的“双重检查”功能扩展到40多种语言,用户可以通过检查整个互联网的内容来验证AI所作回答的准确性。在此之前,“双重检查”功能仅限于英语。这一系列的更新将提升用户对Bard的信任度和使用频率。