【新智元导读】Sora突破之后的突破又来了!语音初创公司ElevenLabs放大招,直接用AI给Sora经典视频完成了配音。网友惊呼离AI完全生成电影又近了一步。
虽然一些人不想承认,但AI视频模型Sora的开年王炸,确实给影视行业带来了颠覆性的影响!

OpenAI Sora各种逼真视频的生成足以让人惊掉下巴,有网友却表示,现在的Sora视频更像是‘无声电影’。

如果再给它们配上音效,现实可就真的就不存在了......
就在今天,AI语音克隆初创公司ElevenLabs给经典的Sora演示视频,完成了绝美的配音。
听过之后,让人简直颅内高潮。
从建筑物到鲨鱼无缝切换视频中,可以听到小鸟叽喳,狗在狂吠,不同动物叫声糅杂在一起,非常空灵。
汽车卯足劲向前行驶的声音,偶尔还能听到石子与轮胎的摩擦音。
还有这欢乐喜庆的中国舞龙表演,敲锣打鼓人声鼎沸,好不热闹。
地铁在轨道中咔哒咔哒行驶,还伴有空气被压缩发出隆~隆~的声音,让人有种耳塞的赶脚。
机器人(10.570, 0.03, 0.28%)的专属配音,直接将赛博风拉满,听过后就知道是那种‘熟悉的味道’。
东京街头上,靓丽的女人提着手提包在路边行走,高跟鞋哒哒哒与步伐完全吻合。还有那汽车鸣笛,路人说话的声音体现的淋漓尽致。
惊涛骇浪撞击着岩石,海鸥在高空中飞翔,叫声高亢嘹亮。
老奶奶开心地吹灭蜡烛,笑容洋溢在每个人的脸上,片刻美好,只希望时间能够按下暂停键。
三只可爱的金毛在雪地中嬉戏打闹,兴奋地汪汪大叫。
更令人震撼的是,下面这个视频直接配出了‘纪录片’的高级感。
在片尾,ElevenLabs表示,以上所有的配音全部由AI生成,没有一点编辑痕迹。

网友惊呼,‘这简直离完全由AI生成电影又近了一步’!

堪称突破后的突破!

需要补充的是,ElevenLabs的配音不是看视频直接生成的,还是需要prompt之后才能完成。
不过,这种梦幻联动确实让人眼前一亮,或许OpenAI的下一步就是进一步扩展多模态能力,将视频、音频同时呈现。
到时候,被革命的不仅仅是影视行业,甚至是配音、游戏领域,也要发生翻天覆地的变化!

向量空间中建模,让LLM理解隐式物理规则
那么,视频到音频的精准映射,该如何突破呢?
对此,英伟达高级科学家Jim Fan做了一个比较全面的分析:
为了精确配合视频内容,配音不仅需要文本信息,视频像素也至关重要。
若想精确地实现‘视频-音频’的无缝匹配,还需要LLM在其潜在空间内理解一些‘隐式的物理原理’。
那么,一个端到端的Transformer需要掌握以下能力,才能正确模拟声波:
- 确定每个物体的种类、材质和空间位置。
- 识别物体间的复杂互动,比如棍子是敲在木头、金属还是鼓面?敲击的速度如何?
- 辨识场景环境,是餐厅、空间站、黄石国家公园还是日本神社?
- 从模型的内存中提取物体及其环境的典型声音模式。
- 应用‘软性’的、已学习的物理规则,组合并调整声音模式的参数,或者即时创造全新的声音,类似于游戏引擎中的‘程序化音频’。
- 对于复杂场景,模型需要根据物体的空间位置,将多条声音轨道叠加起来。
所有这些能力都不是通过显式模块实现的!它们是通过大量时间对齐的视频和音频配对,通过梯度下降法学习得来的。
模型的注意力层将利用其权重来实现这些功能,以达到扩散的目标。

目前,我们还没有创造出如此高质量的‘AI音频引擎’。
Jim Fan挖出了5年前来自MIT团队的一项关于‘The Sound of Pixels’的研究,或许从这里可以找到一些灵感。

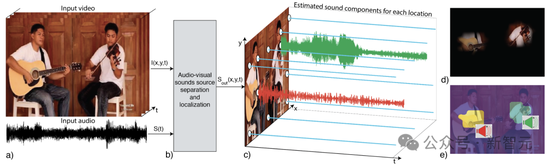
这个项目中,研究人员提出了像素级声源定位系统PixelPlayer。
通过结合声音和图像信息,AI能够以无监督的方式从图像或声音中识别目标、定位图像中的目标,甚至分离目标视频中的声源。
当你给定一个输入视频,PixelPlayer可以联合地将配音分离为目标组件,以及在图像帧上定位目标组件。
值得一提的是,它允许在视频的‘每个像素’上定位声源。

具体来说,研究人员利用了图像和声音的自然同时性,来学习图像声源定位模型。
PixelPlayer学习了近60个小时的音乐演奏,包括独奏和二重奏。它以声音信号作为输入,并预测和视频中空间定位对应的声源信号。
在具体训练过程中,作者还利用了自然声音的可加性来生成视频,其中构成声源是已知的。与此同时,还通过混合声源来训练模型生成声源。
这仅是视觉-音频联合学习(Audio-Visual Learning)研究中的一瞥,过去在这一方向领域的研究也是数不胜数。
比如,在ECCV 2018被接收的Oral论文‘Learning to Separate Object Sounds by Watching Unlabeled Video’,同样使用了视觉信息指导声源分离。

比起MIT的那项研究,这篇论文除了在音乐,还在自然声上进行了实验。
以往的研究,都将为未来视频-音频完成精准映射进一步铺路。
正如这几天被人们炒的火热的Sora模型,背后架构采用的是Diffusion Transformer一样,正是基于前辈们的成果。
话又说回来,网友发出疑问,‘那得需要多少年,LLM才能完全遵守物理达则中的所有可能参照系’?

别慌!
有没有可能OpenAI早已接近,甚至是实现AGI,只不过不想让我们知道?


估值11亿刀,前谷歌大佬创AI语音初创公司
前文提到的ElevenLabs,是由前谷歌机器学习工程师Piotr Dąbkowski和前Palantir部署策略师Mateusz Staniszewski,在2022年共同创立的一家利用AI实现语音合成与文本转语音的公司。
这两位创始人都来自波兰,他们在看到美国电影不尽人意的配音后,萌生了创建ElevenLabs的想法。
尽管ElevenLabs没有固定办公地点并且仅有15名员工,但它却在2023年6月以约1亿美元估值成功筹集到了1900万美元的 A 轮融资。
到了2024年1月22日,ElevenLabs又在B轮融资中筹集了额外的8000万美元,使估值达到了11亿美元。同时,公司还宣布推出了一系列新产品,包括声音市场、AI 配音工作室和移动应用等。
自去年1月发布beta版平台以来,ElevenLabs便受到了创作者们的热捧。
2023年3月,喜剧演员Drew Carey通过ElevenLabs的声音克隆工具,在他的广播节目《Friday Night Freakout》中复刻了自己的声音。
2023年3月,流媒体自动化服务Super-Hi-Fi携手ElevenLabs,利用后者的软件和ChatGPT生成的提示词,为其虚拟DJ配音,推出了全自动的‘AI Radio’广播服务。
6月13日,Storytel宣布与ElevenLabs达成独家合作,后者将专门为Storytel的核心市场量身定制声音,制作AI叙述的有声读物。
在游戏领域,ElevenLabs正与瑞典的Paradox Interactive和英国的Magicave等开发商进行合作。
ElevenLabs的技术还被用于多语言视频配音,帮助内容创作者准确复制几乎任何语言的任何口音。此外,明星粉丝也通过ElevenLabs使用他们偶像的声音创作鼓舞人心的信息。
OpenAI下一次颠覆,又是万亿美元产业?
还记得ChatGPT诞生之后,OpenAI随后为其‘联网’,并发布了全新的插件功能。
那些初创公司们紧跟着,上线了一大波插件应用。
没想到,从3月发布截止到11月,仅仅半年多的时间,一些初创公司却遭到‘屠杀’。
在首届开发者大会上,Sam Altman首次公布定制GPTs,以及即将上线的GPT Store。
可以说,基于OpenAI接口构建创业公司,产品忽然就失去了意义。许多初创公司的产品,已经没有了护城河。
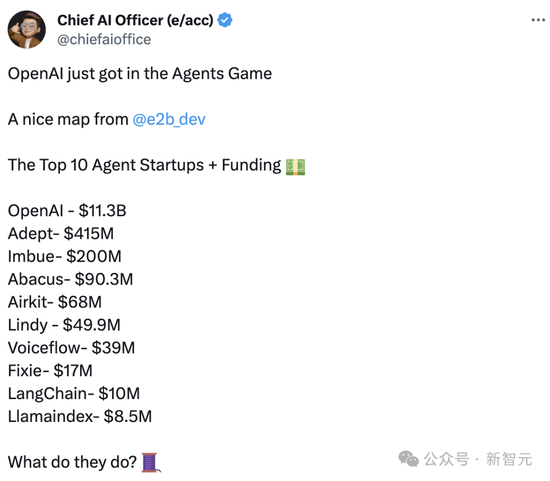
当时有网友便发问,OpenAI入局智能体后,全球十家头部Agent初创公司接下来该做什么?
而现在,首个AI视频模型Sora的横空出世,已经让许多影视行业的人,倍感恐慌。
有网友表示,‘Sora虽然有一些不完美之处(可以检测出来),例如从物理效果可以看出它是人工合成的。但是,它将会革命性地改变许多行业。
想象一下可以生成动态的、个性化的广告视频进行精准定位,这将是一个万亿美元的产业’!

对于Sora的应用前景,有望在未来成为视频制作领域的重要工具。
等OpenAI发布能够视频-音频大模型之后,对于如上专门配音的初创公司ElevenLabs来说,都将是一场‘灾难’。
‘我认为大多数人都不能理解,这对不久的将来的生活意味着什么’。

未来,无论是电影、电视剧、广告,甚至游戏等领域,高质量视频创作,都将被AI入侵。
在那一天还没到来之前,想想我们还能做些什么?