昨天跟大家分享了如何进行端口扫描,今天我要介绍的是目录扫描。
要问这俩有啥区别?等看完笔记就知道了。
好啦,闲话不多说,写笔记啦!
首先我们来看一下今天的知识点:
其实URL,就是我们常说的网页地址。
互联网上的每个文件都有一个唯一的URL,它包含的信息表明了文件的位置,以及告诉浏览器应该怎么样去处理它。
基本的URL结构:协议名://服务器名称,也叫域名(或IP地址)/路径/文件名
例如:
http://baidu.com/index.html
这里就是使用了http协议,域名为baidu.com,路径这里就直接是根目录,文件名就是index.html
当我们访问一个网页时,浏览器会向网站所在的服务器发出请求。
当目标网站返回数据信息的时候,会返回一个包含的HTTP状态码的信息头(server header)
浏览器通过这个状态码就可以知道目标所处的状态,
下面是一些常见的状态码:
200 - 请求成功
301 - 资源(网页等)被永久转移到其它URL
404 - 请求的资源(网页等)不存在
500 - 内部服务器错误
学习这两个知识点之后,我们就可以进入正题了!
目录扫描的意义就是在于发现网站的框架信息,比如后台、编辑器等目录信息。
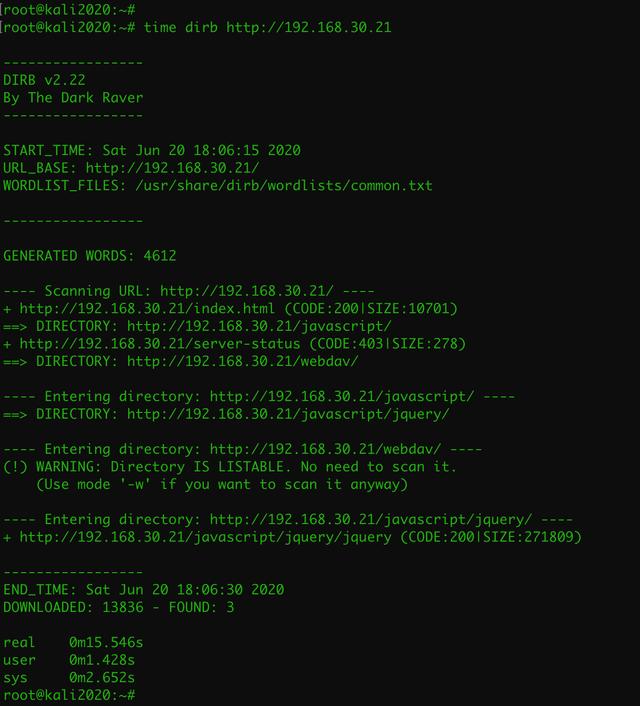
它的原理就是利用不断地发送http请求,然后对返回的状态码进行判断,来寻找存在的网页、目录、文件,为后面的渗透测试作进一步的准备。
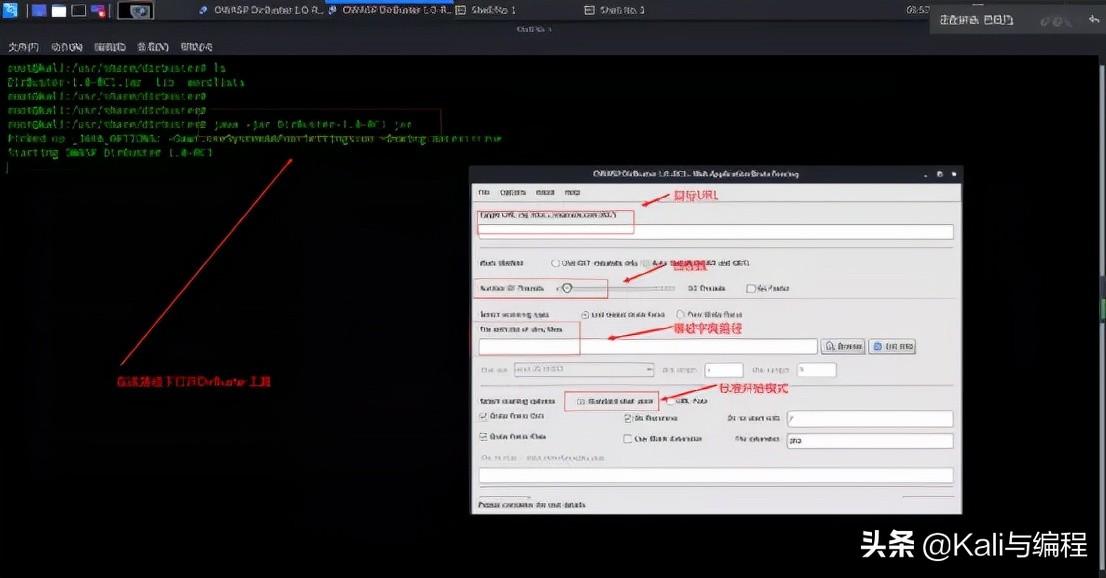
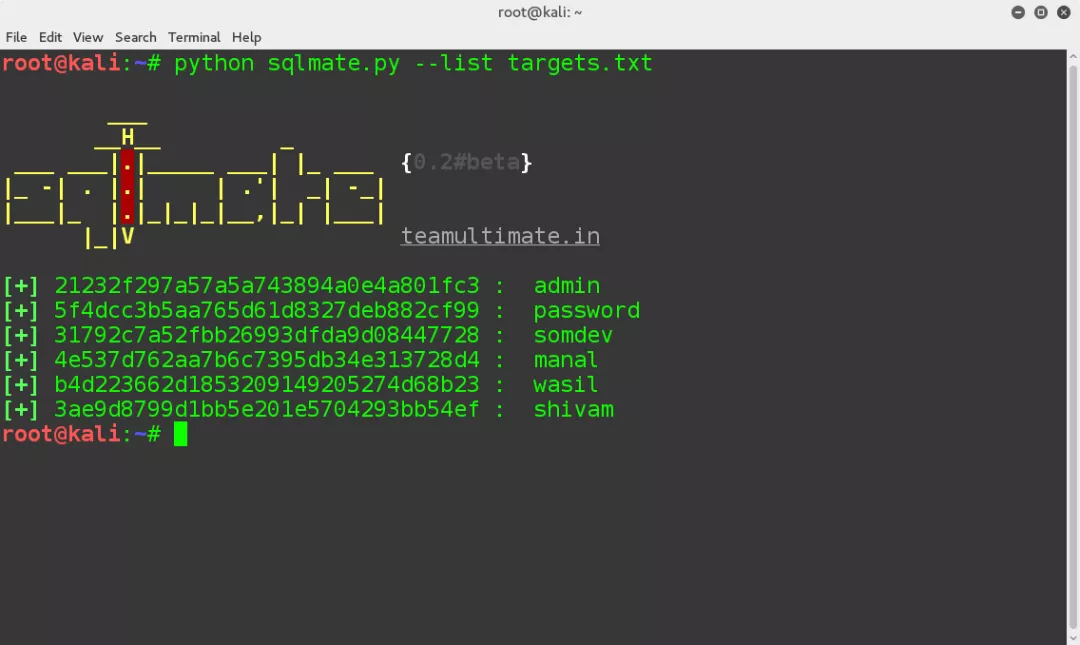
这里呢,我们可以使用一款上古时代的目录扫描器——"御剑"

使用起来也非常的简单,在域名框填写要扫描的域名,记住带上协议名,比如http、https等,然后可以根据网站的编写语言进行选取字典,字典就是要求扫描地址的集合,最后点击开始扫描就可以啦!
在安界网的课程上,老师带着我们对靶场进行了扫描,让我们迅速掌握了目录扫描技能。
目标:http://xxxx.com/

我们放在御剑里面跑一下

访问发现第二个就是网站的后台地址了

老师还说有的网站可能会开waf(防火墙),通过对频率,请求地址进行判断,如果判断出你在恶意扫描,防火墙就会将你电脑的IP给拦截下来,或者全部返回200.这样就会导致一个都扫不出来或者出来一大堆显示存在的地址。
不多说啦,大家可以自己动手扫描一下!
如果你在扫描过程中出现疑问,或遇到其他一些网络信息安全的问题,可以私信我,我会尽快回复的,最后祝大家天天都有新进步!