一、背景介绍
DirBuster是用来探测web服务器上的目录和隐藏文件的。因为DirBuster是采用JAVA编写的,所以运行前要安装上java的环境。
来看一下基本的使用:
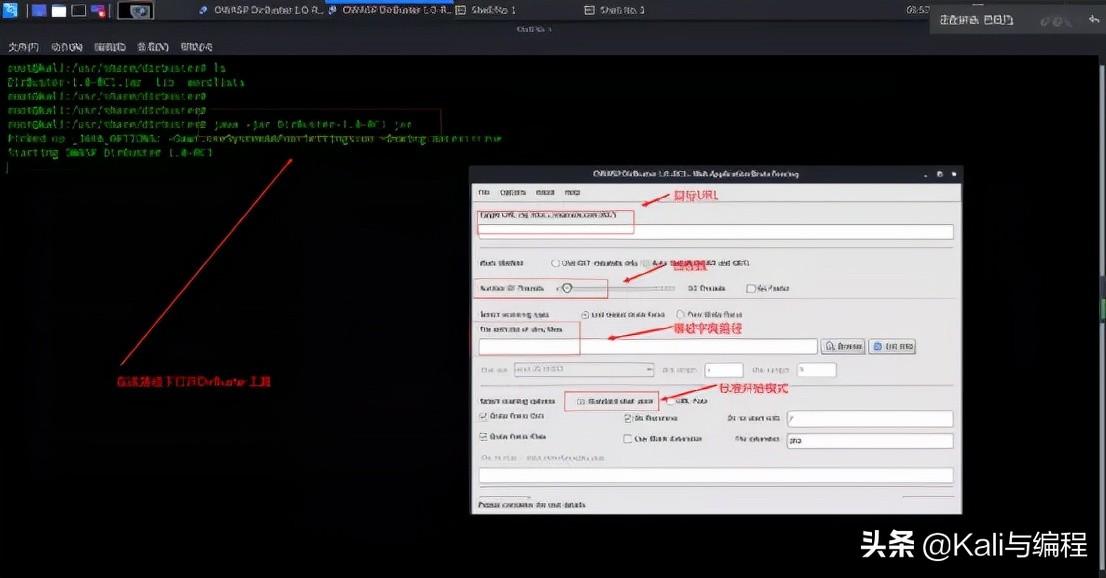
①:TargetURL下输入要探测网站的地址,需要注意的是这个地址要加上协议,看网站是http还是https。
②:WorkMethod是选择工作方式,一个是get请求,一个是自动选择。一般选autoswitch的自动选择,它会自行判断是使用head方式或get方式。
③:NumberofThread是选择扫描线程数,一般为30。电脑配置好的可根据情况选择。
④:selectscanningtype是选择扫描类型。listbasedbruteforce是使用字典扫描的意思,勾选上。随后browse选择字典文件,可用自己的,也可用dirbuster自己的。
⑤:selectstartingoptions选项一个是standardstartpoint(固定标准的名字去搜),一个是urlfuzz(相当于按关键字模糊搜索),选择urlfuzz,随后在urltofuzz框中输入{dir}即可。
配置好后点击start开始即可。有时候你可能看不到开始按钮,把鼠标放到软件边拖动一下大小,放下下界面就会显示出来。DirBuster不仅可以暴力猜解目录,还可以进行蜘蛛爬行。
二、资源装备
1.安装好Kali linux的虚拟机一台;
2.整装待发的小白一个。
专栏
1个月掌握Kali渗透与黑客编程
作者:Kali与编程
99币
274人已购
查看
三、战略安排
3.1 Dirbuster的路径,如下图所示。
路径:/usr/share/dirbuster
3.2 在Dirbuster目录下使用java命令打开Dirbuster工具,如下图所示。
命令:java -jar DirBuster-1.0-RC1.jar
3.3 在任意路径打开Dirbuster工具的方式,如下图所示。
命令:dirbuster
3.4 Dirbuster工具的爆破字典位置,如下图所示。
爆破字典位置:
/usr/share/dirbuster/wordlists
3.5 点击URl Fuzz设置对应变量,如下图所示。
变量:/{dir}
3.6 设置完/{dir}变量后,选择Standard start point按钮,如下图所示。
3.7 开始扫描,如下图所示。
3.8 如下图所示,扫描进行中。。。。。
3.9 根据Response判断扫描的哪些网页可以访问,如下图所示。
响应码:1xx 服务器接收客户端消息,但没有接收完成,等待一段时间后,发送1xx状态码(很少出现)
2xx 成功。代表:200(成功)
3xx 重定向。代表:302(重定向),304(访问缓存)
4xx 客户端错误。代表:404(请求路径没有对应的资源) 405(请求方式没有对应的doXX方法)
5xx 服务端错误。代表:500(服务器内部出现异常)
3.10 扫描结果如下图所示。