目录扫描技术介绍
目录扫描是采用字典对目标网站路径进行猜测并发现隐藏URL的技术,这是黑客对网站常用的攻击手段之一。根据扫描结果,黑客首先可以从大体上了解网站的结构,为实施下一步攻击收集信息,还可以发现网站的隐藏路径或文件等敏感信息,比如:
1)网站的管理后台:网站后台是管理员管理网站的接口之一,通常不会在网站公开页面上留下链接,所以很难被搜索引擎的爬虫扫描发现。当通过目录扫描方式,只要字典足够好,还是有相当大的机会发现隐藏的管理后台入口。
2)未受保护的敏感页面:指不被网站鉴权机制保护的页面,而这类页面可能会拥有一些执行敏感操作的功能。
3)网站的备份文件:如果数据库、源代码备份等,备份是管理员日常管理工作之一,有时候可能会因为疏忽而把备份遗留在网站目录下。通过这些文件,黑客可以获取网站的源代码以及保存在数据库中的敏感信息。
4)其他黑客留下的后门:通过扫描黑客还可能发现其他人留下的webshell后门,通过这些后门黑客可以不费吹灰之力获得网站服务器的权限。
5)网站配置文件:如果数据库初始化sql脚本,网站后台配置等。
如何防范目录扫描
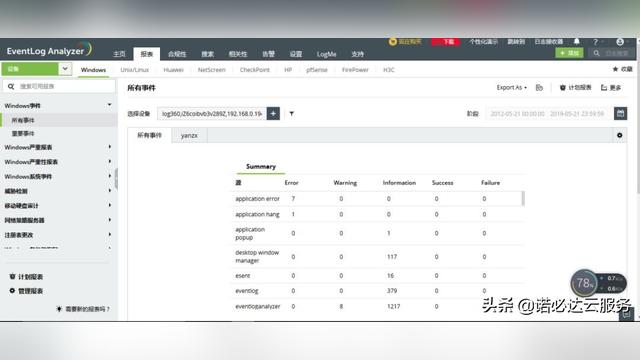
当网站被扫描时访问量会突然增大,同时产生大量的404访问日志,这是网站被扫描攻击的主要症状。接下来我给大家介绍如何通过使用iptables防火墙策略识别流量中的404关键字,并对异常的扫描流量进行限制,这里我们使用到了iptables的recent及string模块:
iptables -F
iptables -Z
iptables -X log404
iptables -N log404
iptables -A log404 -m limit --limit 1/min -j LOG --log-prefix "Dir_buster_attack " --log-level 3
iptables -A log404 -j DROP
iptables -A OUTPUT -p tcp -m tcp --sport 80 -m string --string "404 Not Found" --algo bm --to 65535 -m recent --update --seconds 10 --reap --hitcount 10 --rttl --name Block404 --mask 255.255.255.255 --rdest -j log404
iptables -A OUTPUT -p tcp -m tcp --sport 80 -m string --string "404 Not Found" --algo bm --to 65535 -m recent --set --name Block404 --mask 255.255.255.255 --rdest
在上面的例子中,我们使用string模块识别HTTP响应中的“404 Not Found”关键字,并使用recent命令把服务器对每个IP的404响应速率限制在每10秒10次,当超过这个限制时,后续的应将被丢弃并触发TCP重传,直到过去10秒的响应次数少于10次。
通过这种方式,iptables可识别短时间内发生的大量404响应,并通过丢包方式延长扫描工具的等待时间。
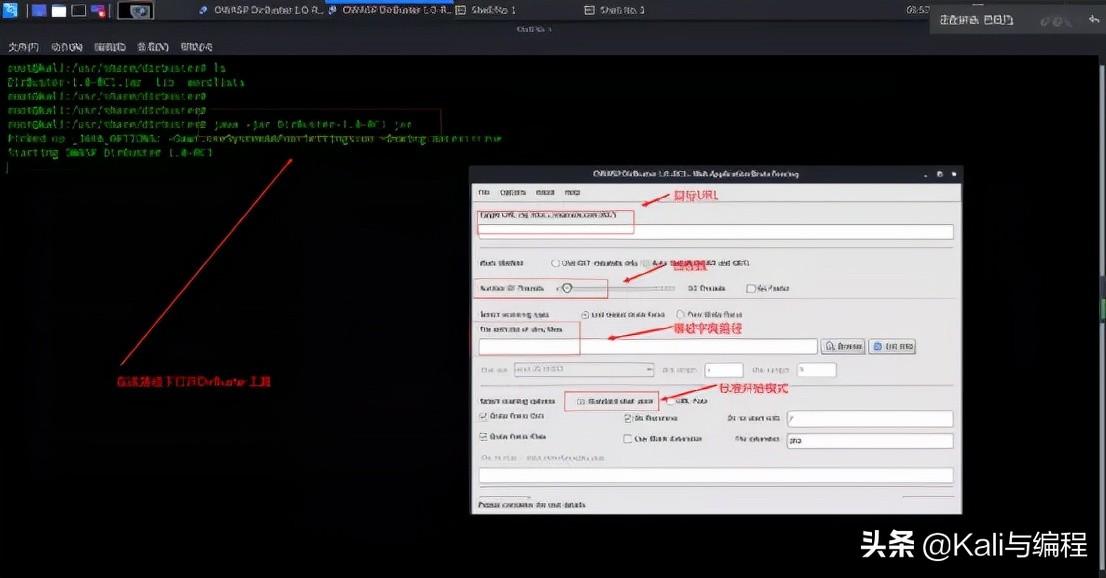
通过使用扫描工具dirb(
https://tools.kali.org/web-Applications/dirb)进行测试发现,当没有iptables限制时,dirb在不到16秒的时间内总共扫描了13836个URL,平均800多次每秒:
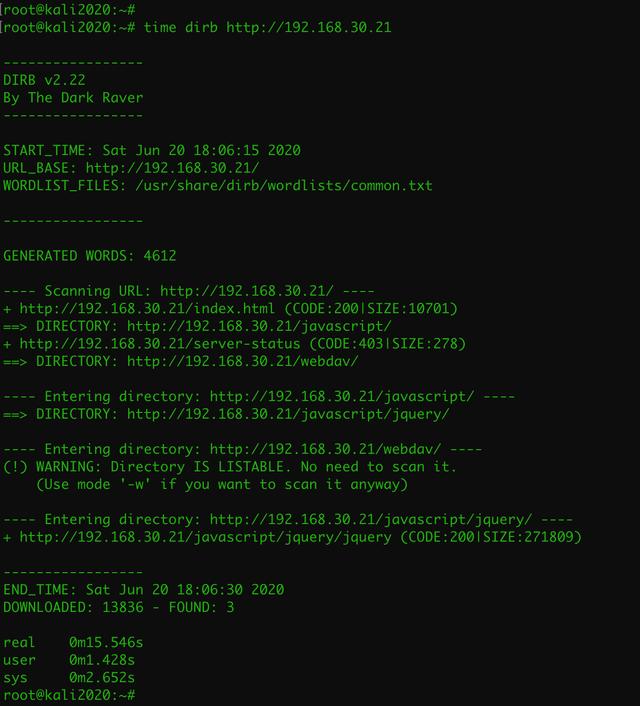
当使用iptables时,100次请求则花了50秒,平均每秒2次,而黑客通常每实施一次扫描要发送上万甚至上百万次请求,这个速度大大超出了他们可接受的范围。可见iptables在防范目录扫描攻击上能起到很好的防护作用:

需要注意的是:
1)首先对流量比较大的网站,recent模块的ip_list_tot参数应设置得足够长,建议设置为网站在高峰时平均在线IP的两倍左右,可通过修改/etc/modprod.d目录下相应的配置文件:

2)使用CDN部署的网站不建议使用这种方式,否则很可能导致CDN IP被误杀。
3)--seconds及--hitcount参数应根据实际环境进行调整,尽量在不影响正常访问的同时提高网站的防护水平。