

转载本文需注明出处:微信公众号EAWorld,违者必究。
前言:
随着微服务架构技术的普及和广泛在企业应用中落地,由于微服务架构本身的特性,架构由一系列相对独立的细粒度的服务组成,一个完整的业务逻辑调用请求的背后可能牵涉后端几个、几十个甚至上百个服务接口,每个服务可能是由不同的团队开发,使用了不同的编程语言,还有可能部署在不同的机器上,分布在不同的数据中心,对于这样的一个逻辑调用关系,如果在调用过程中发生问题,比如说调用失败,或者调用过程响应很慢,如何在这样一个分布式环境下快速定位问题所在、快速分析业务处理中的响应慢的瓶颈在哪?多个微服务之间存在调用关系,如何在系统运行时总览一个系统中微服务间的拓扑关系?如何完整还原一次请求的链路情况?
以上这些问题可以借助链路追踪技术进行解决。链路追踪组件通过在微服务应用中以代码侵入或者非侵入的方式进行数据表示、埋点、传递、收集、存储、展示等技术手段,达到将一次分布式请求还原成调用链路,将一次分布式请求的调用情况集中展示,比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
目录:
1.链路追踪的应用场景
2.链路追踪基本原理
3.链路追踪的Demo实现
4.普元微服务平台的链路追踪应用
移动平台8.0打开了以往eclipse平台的枷锁,全面拥抱了主流的VSCode编辑器,包括支持实用的cli命令行支持、及优秀的跨平台开发框架ReactNative。

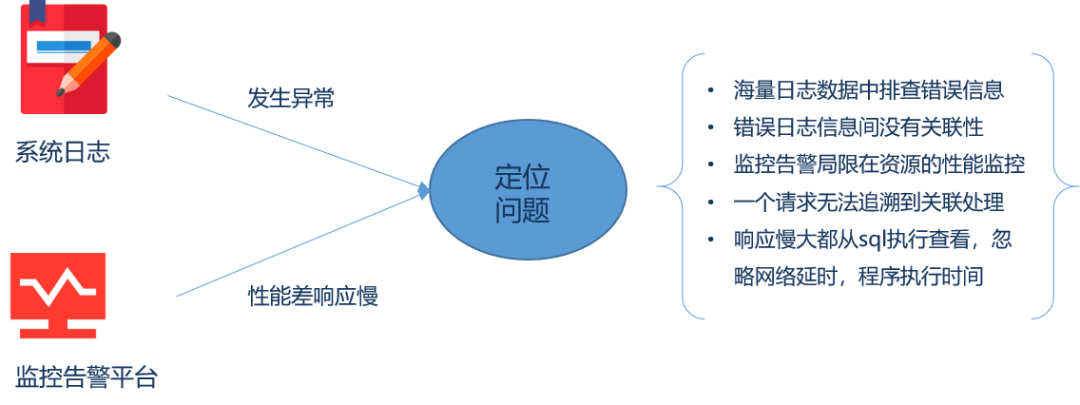
在微服务架构下,分布式系统变得日趋复杂,越来越多的组件开始走向分布式化,如微服务、分布式数据库、分布式缓存等,使得后台服务构成了一种复杂的分布式网络,这样一个场景下,对于用户的每一次请求调用,后端执行了多少组件间的调用无法知晓,由于分布式的调用,增加了程序调用异常的错误率,在这样的应用场景下,新的架构技术带来了新的问题。
场景下的关键问题
1. 如何在请求发生异常时快速定义问题所在
2. 如何在请求响应慢的时候快速找出慢的原因
3. 如何通过日志文件快速定位问题的根本原因
传统的问题排查手段
一般在系统发生问题时,比如系统异常或者系统性能出现问题时,通常都是从系统记录的日志文件中找出蛛丝马脚,而对于微服务架构下的分布式部署,日志文件的分散,想从日志中查找问题工作量很大。对于用户某一次请求调用后端哪些服务,每个服务执行情况,想从日志中获得更是不可能的事。
对于传统的监控告警平台也紧针对平台资源的监控包括cpu、内存、网络带宽情况等,对业务微服务应用的指标(平均响应时间、慢端点情况等)的监控显得无从下手。
在这样的背景下,新的监控体系下的细分领域-链路追踪问世了。
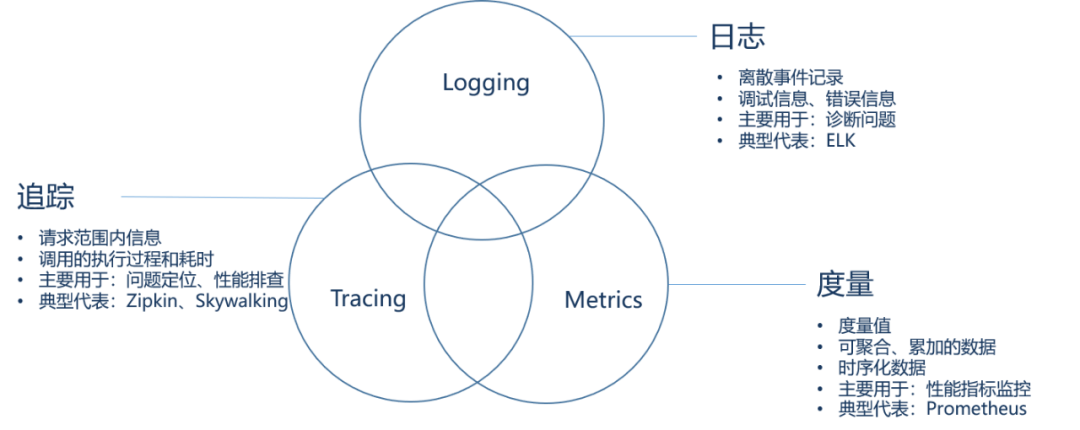
首先,我们来看看在系统监控的体系下具体的细分领域的专注点:
Logging - 用于记录离散的事件。例如,应用程序的调试信息或错误信息。它是我们诊断问题的依据。
Metrics - 用于记录可聚合的数据。例如,队列的当前深度可被定义为一个度量值,在元素入队或出队时被更新;HTTP 请求个数可被定义为一个计数器,新请求到来时进行累加。
Tracing - 用于记录请求范围内的信息。例如,一次远程方法调用的执行过程和耗时。它是我们排查系统性能问题的利器。
在每个请求调用的入口和出口进行代码埋点记录调用之间的关系、每个调用处理时间点信息。
通过调用关系梳理出一次请求的完整链路还原、请求具体到达哪台机器。
通过每次处理记录的时间点,计算出相关的调用执行时间、响应时间、网络延时。
对调用请求量进行统计。
显示链路拓扑结构、应用依赖关系。

Trace:指一个请求经过后端所有服务的路径,每一条链路都用一个全局唯一的traceid来标识。
Span:链路中的调用由span来表示,每个span由spanid和parentid来标识,可以记录调用的父子关系。
Timestamp:调用点的时间戳,记录每个执行点的时间信息。
如果想知道一个接口在哪个环节出现了问题,就必须清楚该接口调用了哪些服务,以及调用的顺序,如果把这些服务串起来,看起来就像链条一样,我们称其为调用链。

到现在,已经知道调用顺序和层级关系了,但是接口出现问题后,还是不能找到出问题的环节,如果某个服务有问题,那个被调用执行的服务一定耗时很长,要想计算出耗时,上述的三个标识还不够,还需要加上时间戳,时间戳可以更精细一点,精确到微秒级。
只记录发起调用时的时间戳还算不出耗时,要记录下服务返回时的时间戳,有始有终才能算出时间差,既然返回的也记了,就把上述的三个标识都记一下吧,不然区分不出是谁的时间戳。
前面我们介绍了链路追踪的技术原理,以及相关的实现链路追踪的开源组件,那么我们实际在项目中要怎么做,是否需要根据技术原理去实现底层的相关开发。通过这个章节,我简单的通过一个demo去演示如何在微服务架构系统中完成链路追踪的功能。
我们简单描述一下demo的相关情况,首先demo是要基于微服务架构的,那么我们提供2个微服务应用(订单服务、产品服务),并且提供一个服务注册发现中心,订单服务会调用产品服务,并且是通过注册中心去发现服务调用服务,这样从前端请求调用订单服务,再由订单服务调用产品服务,完成了一个简单的链路调用,需求链路很短,只有两次调用,足够演示demo的链路追踪功能。
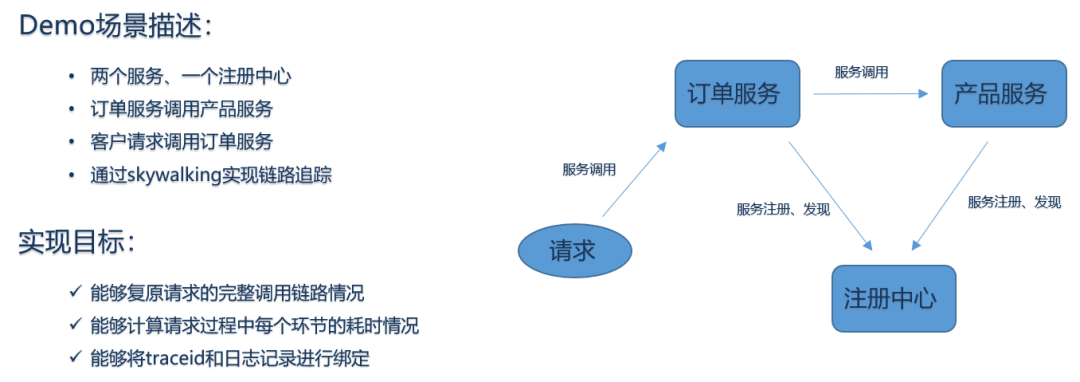
通过demo将教打家一步一步的去实现链路的相关功能,包括还原请求的完整调用链路情况,能够查看请求过程中订单服务,产品服务执行的耗时情况,总的请求响应时间,并且可以根据请求链路的traceid查看到对应的请求处理的日志信息。

首先创建springboot项目,通过依赖eureka组件,提供服务的注册中心,实现服务的注册与发现。
添加依赖

Properties配置信息

再添加两个springboot项目,一个订单服务,一个产品服务

由于服务需要注册到注册中心,因此两个项目需要添加依赖

并添加配置信息

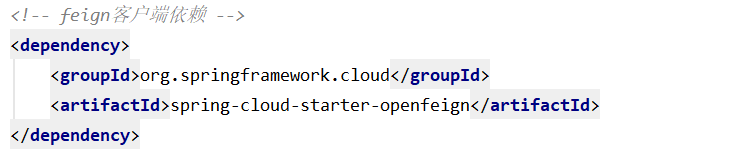
并且订单服务需要调用产品服务的方法,在demo中我们使用feign的方式进行服务调用,因此在订单服务项目中需要添加依赖
由于是demo,因此我们服务中的方法就简单通过返回字符串的方式实现。
至此我们启动两个微服务应用,可以在注册中心中看到两个服务都已经注册上来,再通过浏览器请求订单服务的接口,可以看到后端通过调用产品服务的接口,并返回信息。

到目前为止,我们只是构建好了微服务应用,对应链路追踪功能还没有实现,其实在微服务架构下实现链路追踪很简单,毕竟有很多开源的组件封装了底层实现原理,我们只需要引用这些组件就可以实现链路追踪功能,在demo中我通过skywalking来进行链路追踪,由于skywalking本身的特性无需代码侵入,只需要以探针的方式启动微服务应用即可。并自动采集服务调用的相关信息,写入数据库,然后通过自带的dashboard查看相关信息。
首先我们先下载skywalking

其中,agent目录是应用启动时用的代理,bin目录是skywalking后端服务和dashboard,在bin目录执行startup.bat文件,启动服务。
在订单服务和产品服务的项目启动配置中,加上jvm参数,以探针方式启动2个服务应用

启动后,我们可以通过skywalking自带的dashboard查看信息。

可以看到请求的链路情况,以及每个路径上的处理时间,总的响应时间等信息。
还有一个目标就是,如何将链路跟我们实际的日志记录进行绑定,这样方便在某个链路出现问题时,我们可以针对这个具体的链路去查看具体问题原因。
在demo中,我们通过logback记录日志,添加依赖

目前很多的链路追踪组件都已经实现了与日志组件的集成,只需要引入依赖,即可完成将链路traceid对应写入到日志中。

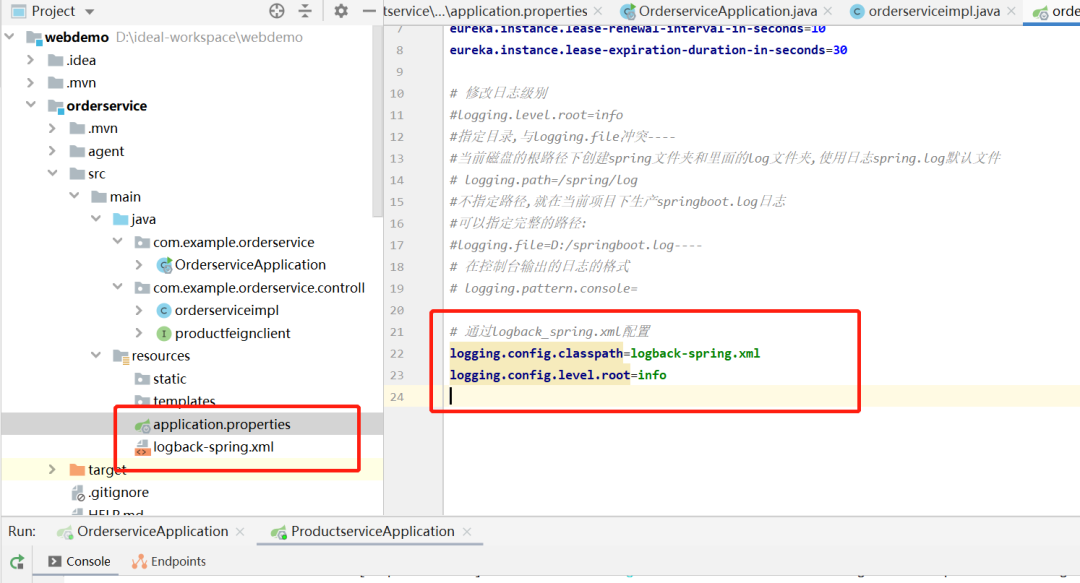
在代码中加入写日志的代码

增加配置信息,以及logback-spring.xml文件


可以看到控制台日志中,记录的日志前面都加上了TID信息,也就是traceid。
上面的demo只是简单的验证了如何快速通过第三方组件实现微服务架构下的链路追踪功能,对于在实际项目应用中我们需要进行优化和整合,这章节中介绍我们普元微服务平台在链路追踪中的相关应用场景:
1. 系统拓扑结构
2. 应用运行时
3. 业务链路
4. 跟踪日志
5. 服务统计
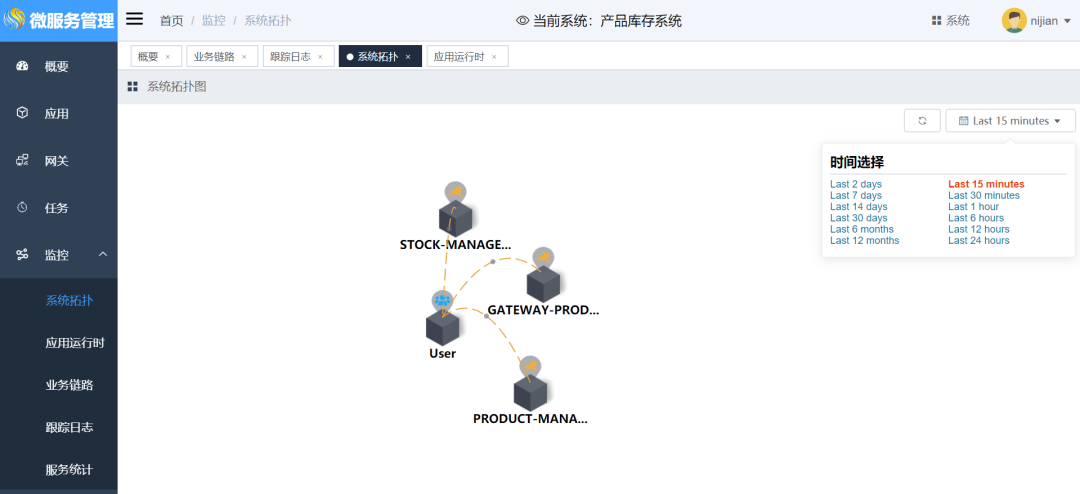
在链路追踪下,系统可以根据请求调用关系绘制去系统拓扑结构,通过系统拓扑结构你可以清楚知道当前系统下有多少微服务应用,微服务应用间是否有调用关系,每个服务的具体概况。
由于微服务架构下,一个系统的微服务相对比较多,如果没有这个系统拓扑结构,后期对系统的情况,尤其是系统间的调用依赖关系跟踪也很困难。

应用运行时,通过收集统计相关调用请求信息,计算相关性能指标,帮助系统管理员运维人员快速了解系统的相关情况,主要是微服务应用实例的能力指标,比如平均响应时间、平均响应成功率等指标。
由于普元微服务平台的架构特性,每一个服务对应多个应用实例组,因此在查看时可以选择具体实例组下的实例节点。帮助我们了解应用节点的性能,以及慢节点情况。

业务链路,快速查看某个应用、甚至应用下某个具体的操作的完整链路调用情况,链路中每个过程处理的时间信息,每个链路上显示traceid信息,并提供快速复制功能,方便用户在跟踪日志中快速查看此次链路对应的日志信息。
根据请求中的时间信息,在请求响应慢的时候追溯具体慢的操作。

链路调用的时序情况,通过不同颜色区分应用系统,可以查看具体调用的详细信息(组件、url、请求方式、异常信息等)。

链路日志,前面我们已经完成了请求完整链路的还原,不过这些信息还不能查出根本原因,对应异常发生的根本原因,我们有时还需要通过系统记录的日志文件进行查看,通过日志文件记录的错误信息进行排查根本原因。
我们在查看日志文件时,也不是直接显示日志文件所有内容,而是通过以与链路对应的方式,显示每个链路环节中记录的日志信息,查看异常详细原因。
另外,在跟踪日志模块,我们针对性的过滤筛选错误日志、事务日志等信息。
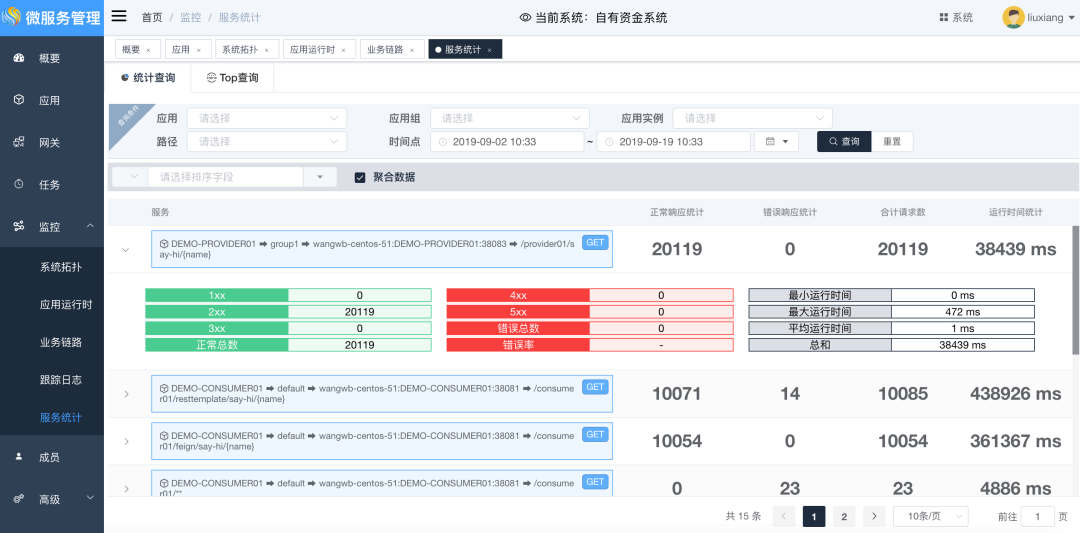
平台通过链路组件采集的请求处理信息,对这些信息进行统计,从多个维度提供统计数据供运维人员进行参考分析
统计某个应用、某个请求路径的总请求数、正常响应数、错误响应数、最长处理时间、最少处理时间、平均处理时间以及各类异常处理的统计
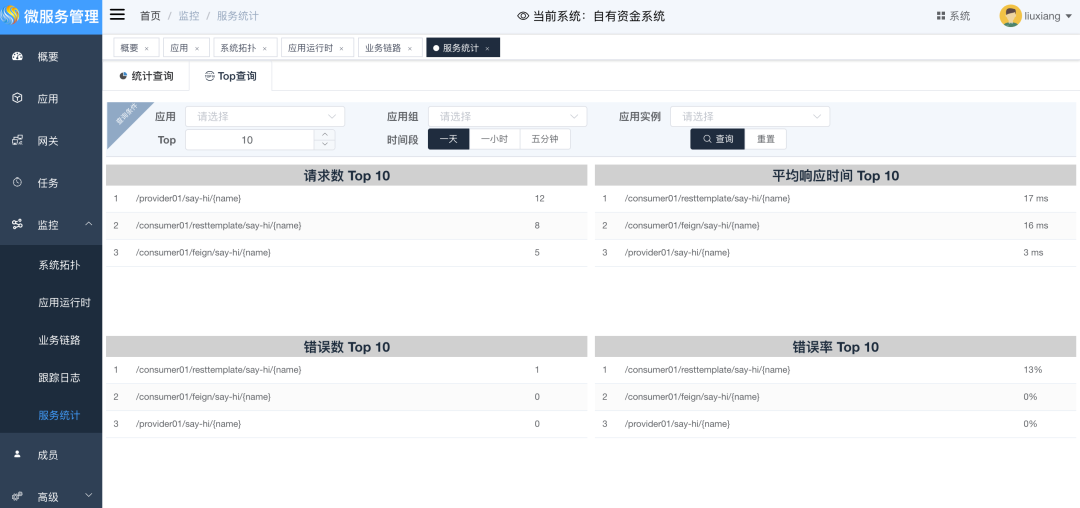
在平台正常运行一段时间后,运维人员普遍关注平台的运行情况,尤其是哪些请求比较频繁、哪些请求比较耗时、哪些请求错误率比较高、哪些错误数多,而这些信息对于运维人员比较敏感,因此平台中提供直接显示统计数据的方式供参考。
本文主要介绍微服务架构下的链路追踪的应用场景,主要解决哪些问题,对于一个刚接触链路追踪的新人来说,如何快速上手将链路追踪引入到项目中,也将我们普元微服务平台下的链路追踪的应用简单介绍了一下,便于大家在项目中进行实际的应用参考。文中没有对目前市场上开源的链路追踪的组件做过多介绍以及之间的比较,也没有对skywalking这个组件的使用配置做详细介绍,相关的这些知识我们有专栏介绍,大家可以查看历史文章进行了解。
关于作者:轩雨,普元产品经理,主要负责公司微服务、容器云相关产品的研发和实施,在分布式架构、微服务、DevOps、容器云、软件工程等领域方向具有较深的积累,拥有十多年的产品研发与多个大型平台项目管理经验。
关于EAWorld:微服务,DevOps,数据治理,移动架构原创技术分享。

















