背景
考拉安全部技术这块目前主要负责两块业务:一个是内审,主要是通过敏感日志管理平台搜集考拉所有后台系统的操作日志,数据导入到es后,结合storm进行实时计算,主要有行为查询、数据监控、事件追溯、风险大盘等功能;一个是业务风控,主要是下单、支付、优惠券、红包、签到等行为的风险控制,对抗的风险行为包括黄牛刷单、恶意占用库存、机器领券、撸羊毛等。这两块业务其实有一个共通点,就是有大量需要进行规则决策的场景,比如内审中需要进行实时监控,当同一个人在一天时间内的导出操作超过多少次后进行告警,当登录时不是常用地登录并且设备指纹不是该账号使用过的设备指纹时告警。而在业务风控中需要使用到规则决策的场景更多,由于涉及规则的保密性,这里就不展开了。总之,基于这个出发点,安全部决定开发出一个通用的规则引擎平台,来满足以上场景。
写在前面
在给出整体架构前,想跟大家聊聊关于架构的一些想法。目前架构上的分层设计思想已经深入人心,大家都知道要分成controller,server,dao等,是因为我们刚接触到编码的时候,mvc的模型已经大行其道,早期的jsp里面包含大量业务代码逻辑的方式已经基本绝迹。但是这并不是一种面向对象的思考方式,而往往我们是以一种面向过程的思维去编程。举个简单例子,我们要实现一个网银账户之间转账的需求,往往会是下面这种实现方式:
- 设计一个账户交易服务接口AccountingService,设计一个服务方法transfer(),并提供一个具体实现类AccountingServiceImpl,所有账户交易业务的业务逻辑都置于该服务类中。
- 提供一个AccountInfo和一个Account,前者是一个用于与展示层交换账户数据的账户数据传输对象,后者是一个账户实体(相当于一个EntityBean),这两个对象都是普通的JAVABean,具有相关属性和简单的get/set方法。
- 然后在transfer方法中,首先获取A账户的余额,判断是否大于转账的金额,如果大于则扣减A账户的余额,并增加对应的金额到B账户。
这种设计在需求简单的情况下看上去没啥问题,但是当需求变得复杂后,会导致代码变得越来越难以维护,整个架构也会变的腐烂。比如现在需要增加账户的信用等级,不同等级的账户每笔转账的最大金额不同,那么我们就需要在service里面加上这个逻辑。后来又需要记录转账明细,我们又需要在service里面增加相应的代码逻辑。最后service代码会由于需求的不断变化变得越来越长,最终变成别人眼中的“祖传代码”。导致这个问题的根源,我认为就是我们使用的是一种面向过程的编程思想。那么如何去解决这种问题呢?主要还是思维方式上需要改变,我们需要一种真正的面向对象的思维方式。比如一个“人”,除了有id、姓名、性别这些属性外,还应该有“走路”、“吃饭”等这些行为,这些行为是天然属于“人”这个实体的,而我们定义的bean都是一种“失血模型”,只有get/set等简单方法,所有的行为逻辑全部上升到了service层,这就导致了service层过于臃肿,并且很难复用已有的逻辑,最后形成了各个service之间错综复杂的关联关系,在做服务拆分的时候,很难划清业务边界,导致服务化进程陷入泥潭。
对应上面的问题,我们可以在Account这个实体中加入本应该就属于这个实体的行为,比如借记、贷记、转账等。每一笔转账都对应着一笔交易明细,我们根据交易明细可以计算出账户的余额,这个是一个潜在的业务规则,这种业务规则都需要交由实体本身来维护。另外新增账户信用实体,提供账户单笔转账的最大金额计算逻辑。这样我们就把原本全部在service里面的逻辑划入到不同的负责相关职责的“领域对象”当中了,service的逻辑变得非常清楚明了,想实现A给B转账,直接获取A实体,然后调用A实体中的转账方法即可。service将不再关注转账的细节,只负责将相关的实体组织起来,完成复杂的业务逻辑处理。
上面的这种架构设计方式,其实就是一种典型的“领域驱动设计(DDD)”思想,在这里就不展开说明了(主要是自己理解的还不够深入,怕误导大家了)。DDD也是目前非常热门的一种架构设计思想了,它不能减少你的代码量,但是能使你的代码具有很高的内聚性,当你的项目变得越来越复杂时,能保持架构的稳定而不至于过快的腐烂掉,不了解的同学可以查看相关资料。要说明的是,没有一种架构设计是万能的、是能解决所有问题的,我们需要做的是吸收好的架构设计思维方式,真正架构落地时还是需要根据实际情况选择合适的架构。
整体架构设计
上面说了些架构设计方面的想法,现在我们回到规则引擎平台本身。我们抽象出了四个分层,从上到下分别为:服务层、引擎层、计算层和存储层,整个逻辑层架构见下图:

- 服务层:服务层主要是对外提供服务的入口层,提供的服务包括数据分析、风险检测、业务决策等,所有的服务全部都是通过数据接入模块接入数据,具体后面讲
- 引擎层:引擎层是整个平台的核心,主要包括了执行规则的规则引擎、还原事件现场和聚合查询分析的查询引擎以及模型预测的模型引擎
- 计算层:计算层主要包括了指标计算模块和模型训练模块。指标会在规则引擎中配置规则时使用到,而模型训练则是为模型预测做准备
- 存储层:存储层包括了指标计算结果的存储、事件信息详情的存储以及模型样本、模型文件的存储
在各个分层的逻辑架构划定后,我们就可以开始分析整个平台的业务功能模块。主要包括了事件接入模块、指标计算模块、规则引擎模块、运营中心模块,整个业务架构如下图:

1.事件接入中心
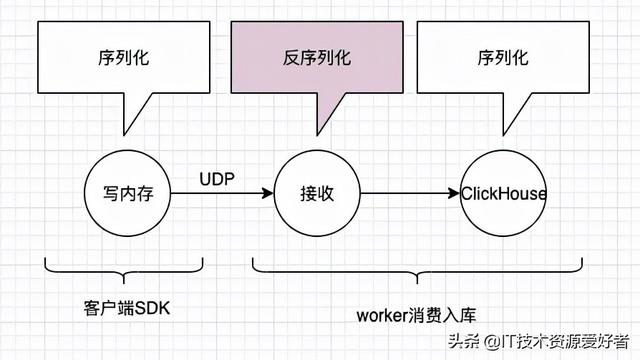
事件接入中心主要包括事件接入模块和数据管理模块。数据接入模块是整个规则引擎的数据流入口,所有的业务方都是通过这个模块接入到平台中来。提供了实时(dubbo)、准实时(kafka)和离线(hive)三种数据接入方式。数据管理模块主要是进行事件的元数据管理、标准化接入数据、补全必要的字段,如下图:

2.指标计算模块
指标计算模块主要是进行指标计算。一个指标由主维度、从维度、时间窗口等组成,其中主维度至少有一个,从维度最多有一个。如下图:

举个例子,若有这样一个指标:“最近10分钟,同一个账号在同一个商家的下单金额”,那么主维度就是下单账号+商家id,从维度就是订单金额。可以看到,这里的主维度相当于sql里面的group by,从维度相当于count,数值累加相当于sum。从关于指标计算,有几点说明下:
- key的构成。我们的指标存储是用的redis,那么这里会涉及到一个key该如何构建的问题。我们目前的做法是:key=指标id+版本号+主维度值+时间间隔序号。
-
- 指标id就是指标的唯一标示;
- 版本号是指标对象的版本,每次更新完指标都会更新对应的版本号,这样可以让就的指标一次全部失效;
- 主维度值是指当前事件对象中,主维度字段对应的值,比如一个下单事件,主维度是用户账号,那么这里就是对应的类似XXX@163.com,如果有多个主维度则需要全部组装上去;
- 如果主维度的值出现中文,这样直接拼接在key里面会有问题,可以采用转义或者md5的方式进行。
- 时间间隔序号是指当前时间减去指标最后更新时间,得到的差值再除以采样周期,得到一个序号。这么做主要是为了实现指标的滑动窗口计算,下面会讲
- 滑动窗口计算。比如我们的指标是最近10分钟的同一用户的下单量,那么我们就需要实现一种类似的滑动窗口算法,以便任何时候都能拿到“最近10分钟”的数据。这里我们采用的是一种简单的算法:创建指标时,指定好采样次数。比如要获取“最近10分钟”的数据,采样次数设置成30次,这样我们会把每隔20秒的数据会放入一个key里面。每次一个下单事件过来时,计算出时间间隔序号(见第1点),然后组装好key之后看该key是否存在,存在则进行累计,否则往redis中添加该key。
- 如何批量获取key。每次获取指标值时,我们都是先计算出需要的key集合(比如我要获取“单个账号最近10分钟的下单量”,我可能需要获取30个key,因为每个key的跨度是20s),然后获取到对应的value集合,再进行累加。而实际上我们只是需要累加后的值,这里可以通过redis+lua脚本进行优化,脚本里面直接根据key集合获取value后进行累加然后返回给客户端,这样就较少了每次响应的数据量。
- 如何保证指标的计算结果不丢失?目前的指标是存储在redis里面的,后来会切到solo-ldb,ldb提供了持久化的存储引擎,可以保证数据不丢失。
3.规则引擎模块
计划开始做规则引擎时进行过调研,发现很多类似的平台都会使用drools。而我们从一开始就放弃了drools而全部使用groovy脚本实现,主要是有以下几点考虑:
- drools相对来说有点重,而且它的规则语言不管对于开发还是运营来说都有学习成本
- drools使用起来没有groovy脚本灵活。groovy可以和spring完美结合,并且可以自定义各种组件实现插件化开发。
- 当规则集变得复杂起来时,使用drools管理起来有点力不从心。
当然还有另外一种方式是将drools和groovy结合起来,综合双方的优点,也是一种不错的选择,大家可以尝试一下。
规则引擎模块是整个平台的核心,我们将整个模块分成了以下几个部分:

规则引擎在设计中也碰到了一些问题,这里给大家分享下一些心得:
- 使用插件的方式加载各种组件到上下文中,极大的方便了功能开发的灵活性。
- 使用预加载的方式加载已有的规则,并将加载后的对象缓存起来,每次规则变更时重新load整条规则,极大的提升了引擎的执行效率
- 计数器引入AtomicLongFieldUpdater工具类,来减少计数器的内存消耗
- 灵活的上下文使用方式,方便定制规则执行的流程(规则执行顺序、同步异步执行、跳过某些规则、规则集短路等),灵活定义返回结果(可以返回整个上下文,可以返回每条规则的结果,也可以返回最后一条规则的结果),这些都可以通过设置上下文来实现。
- groovy的方法查找策略,默认是从metaClass里面查找,再从上下文里找,为了提升性能,我们重写了metaClass,修改了这个查询逻辑:先从上下文里找,再从metaClass里面找。
规则配置如下图所示:

未来规划
后面规则引擎平台主要会围绕下面几点来做:
- 指标存储计划从redis切换到hbase。目前的指标计算方式会导致缓存key的暴涨,获取一个指标值可能需要N个key来做累加,而换成hbase之后,一个指标就只需要一条记录来维护,使用hbase的列族来实现滑动窗口的计算。
- 规则的灰度上线。当一条新规则创建后,如果不进行灰度的测试,直接上线是可能会带来灾难的。后面再规则上线流程中新增灰度上线环节,整个引擎会根据配置的灰度比例,复制一定的流量到灰度规则中,并对灰度规则的效果进行展示,达到预期效果并稳定后才能审批上线。
- 事件接入的自动化。dubbo这块可以采用泛化调用,http接口需要统一调用标准,消息需要统一格式。有了统一的标准就可以实现事件自动接入而不需要修改代码上线,这样也可以保证整个引擎的稳定性。
- 模型生命周期管理。目前模型这块都是通过在猛犸平台上提交jar包的方式,离线跑一个model出来,没有一个统一的平台去管控整个模型的生命周期。现在杭研已经有类似的平台了,后续需要考虑如何介入。
- 数据展示优化。现在整个平台的数字化做的比较弱,没法形成数据驱动业务。而风控的运营往往是需要大量的数据去驱动规则的优化的,比如规则阈值的调试、规则命中率、风险大盘等都需要大量数据的支撑。
声明:本站部分内容及图片来自互联网,转载是出于传递更多信息之目的,内容观点仅代表作者本人,如有任何标注错误或版权侵犯请与我们联系(Email:2595517585@qq.com),我们将及时更正、删除,谢谢。