一、什么是工作流引擎
工作流引擎是驱动工作流执行的一套代码。
至于什么是工作流、为什么要有工作流、工作流的应用景,同学们可以看一看网上的资料,在此处不在展开。
二、为什么要重复造轮子
开源的工作流引擎很多,比如 activiti、flowable、Camunda 等,那么,为什么没有选它们呢?基于以下几点考虑:
因此,重复造了轮子,其实,还有一个更深层次的战略上的考虑,即:作为科技公司,我们一定要有我们自己的核心底层技术!这样,才能不受制于人(参考最近的芯片问题)。
三、怎么造的轮子
对于一次学习型分享来讲,过程比结果更重要,那些只说结果,不细说过程甚至不说的分享,我认为是秀肌肉,而不是真正意义上的分享。因此,接下来,本文将重点描述造轮子的主要过程。
一个成熟的工作流引擎的构建是很复杂的,如何应对这种复杂性呢?一般来讲,有以下三种方法:
如果按照上述方法,一步一步的详细展开,那么可能需要一本书。为了缩减篇幅而又不失干货,本文会描述重点几个迭代,进而阐述轻量级工作流引擎的设计与主要实现。
那么,轻量级又是指什么呢?这里,主要是指以下几点
好,废话说完了,开始第一个迭代......
四、Hello ProcessEngine
按照国际惯例,第一个迭代用来实现 hello world 。
1、需求
作为一个流程管理员,我希望流程引擎可以运行如下图所示的流程,以便我能够配置流程来打印不同的字符串。

2、分析
3、设计
(1)流程的表示
相较于JSON,XML的语义更丰富,可以表达更多的信息,因此这里使用XML来对流程进行表示,如下所示
flow_1flow_1flow_2flow_2flow_3flow_3
(2)节点的表示
(3)流程引擎的逻辑
基于上述XML,流程引擎的运行逻辑如下
4、实现
首先要进行数据结构的设计,即:要把问题域中的信息映射到计算机中的数据。
可以看到,一个流程(PeProcess)由多个节点(PeNode)与边(PeEdge)组成,节点有出边(out)、入边(in),边有流入节点(from)、流出节点(to)。
具体的定义如下:
public class PeProcess {public String id;public PeNode start;public PeProcess(String id, PeNode start) {this.id = id;this.start = start;public class PeEdge {private String id;public PeNode from;public PeNode to;public PeEdge(String id) {this.id = id;public class PeNode {private String id;public String type;public PeEdge in;public PeEdge out;public PeNode(String id) {this.id=id;
PS : 为了表述主要思想,在代码上比较“奔放自由”,生产中不可直接复制粘贴!
接下来,构建流程图,代码如下:
public class XmlPeProcessBuilder {private String xmlStr;private final Map id2PeNode = new HashMap<>();private final Map id2PeEdge = new HashMap<>();public XmlPeProcessBuilder(String xmlStr) {this.xmlStr = xmlStr;public PeProcess build() throws Exception {//strToNode : 把一段xml转换为org.w3c.dom.NodeNode definations = XmlUtil.strToNode(xmlStr);//childByName : 找到definations子节点中nodeName为process的那个NodeNode process = XmlUtil.childByName(definations, "process");NodeList childNodes = process.getChildNodes();for (int j = 0; j < childNodes.getLength(); j++) {Node node = childnodes.item(j);//#text node should be skipif (node.getNodeType() == Node.TEXT_NODE) continue;if ("sequenceFlow".equals(node.getNodeName()))buildPeEdge(node);elsebuildPeNode(node);Map.Entry startEventEntry = id2PeNode.entrySet().stream().filter(entry -> "startEvent".equals(entry.getValue().type)).findFirst().get();return new PeProcess(startEventEntry.getKey(), startEventEntry.getValue());private void buildPeEdge(Node node) {//attributeValue : 找到node节点上属性为id的值PeEdge peEdge = id2PeEdge.computeIfAbsent(XmlUtil.attributeValue(node, "id"), id -> new PeEdge(id));peEdge.from = id2PeNode.computeIfAbsent(XmlUtil.attributeValue(node, "sourceRef"), id -> new PeNode(id));peEdge.to = id2PeNode.computeIfAbsent(XmlUtil.attributeValue(node, "targetRef"), id -> new PeNode(id));private void buildPeNode(Node node) {PeNode peNode = id2PeNode.computeIfAbsent(XmlUtil.attributeValue(node, "id"), id -> new PeNode(id));peNode.type = node.getNodeName();Node inPeEdgeNode = XmlUtil.childByName(node, "incoming");if (inPeEdgeNode != null)//text : 得到inPeEdgeNode的nodeValuepeNode.in = id2PeEdge.computeIfAbsent(XmlUtil.text(inPeEdgeNode), id -> new PeEdge(id));Node outPeEdgeNode = XmlUtil.childByName(node, "outgoing");if (outPeEdgeNode != null)peNode.out = id2PeEdge.computeIfAbsent(XmlUtil.text(outPeEdgeNode), id -> new PeEdge(id));
接下来,实现流程引擎主逻辑,代码如下:
public class ProcessEngine {private String xmlStr;public ProcessEngine(String xmlStr) {this.xmlStr = xmlStr;public void run() throws Exception {PeProcess peProcess = new XmlPeProcessBuilder(xmlStr).build();PeNode node = peProcess.start;while (!node.type.equals("endEvent")) {if ("printHello".equals(node.type))System.out.print("Hello ");if ("printProcessEngine".equals(node.type))System.out.print("ProcessEngine ");node = node.out.to;
就这?工作流引擎就这?同学们可千万不要这样简单理解啊,毕竟这还只是hello world而已,各种代码量就已经不少了。
另外,这里面还有很多可以改进的空间,比如异常控制、泛化、设计模式等,但毕竟只是一个hello world而已,其目的是方便同学理解,让同学入门。
那么,接下来呢,就要稍微贴近一些具体的实际应用场景了,我们继续第二个迭代。
五、简单审批
一般来讲工作流引擎属于底层技术,在它之上可以构建审批流、业务流、数据流等类型的应用,那么接下啦就以实际中的简单审批场景为例,继续深入工作流引擎的设计,好,我们开始。
1、需求
作为一个流程管理员,我希望流程引擎可以运行如下图所示的流程,以便我能够配置流程来实现简单的审批流。

例如:小张提交了一个申请单,然后经过经理审批,审批结束后,不管通过还是不通过,都会经过第三步把结果发送给小张。
2、分析
3、设计
4、实现
新的XML定义如下:
flow_1flow_1flow_2flow_2flow_3flow_3flow_4flow_4
首先要有一个上下文对象类,用于传递变量的,定义如下:
public class PeContext {private Map info = new ConcurrentHashMap<>();public Object getValue(String key) {return info.get(key);public void putValue(String key, Object value) {info.put(key, value);
每个节点的处理逻辑是不一样的,此处应该进行一定的抽象,为了强调流程中节点的作用是逻辑处理,引入了一种新的类型--算子(Operator),定义如下:
public interface IOperator {//引擎可以据此来找到本算子String getType();//引擎调度本算子void doTask(ProcessEngine processEngine, PeNode node, PeContext peContext);
对于引擎来讲,当遇到一个节点时,需要调度之,但怎么调度呢?首先需要各个节点算子注册(registNodeProcessor())进来,这样才能找到要调度的那个算子。
其次,引擎怎么知道节点算子自有逻辑处理完了呢?一般来讲,引擎是不知道的,只能是由算子告诉引擎,所以引擎要提供一个功能(nodeFinished()),这个功能由算子调用。
最后,把算子任务的调度和引擎的驱动解耦开来,放入不同的线程中。
修改后的ProcessEngine代码如下:
public class ProcessEngine {private String xmlStr;//存储算子private Map type2Operator = new ConcurrentHashMap<>();private PeProcess peProcess = null;private PeContext peContext = null;//任务数据暂存public final BlockingQueue arrayBlockingQueue = new LinkedBlockingQueue();//任务调度线程public final Thread dispatchThread = new Thread(() -> {while (true) {try {PeNode node = arrayBlockingQueue.take();type2Operator.get(node.type).doTask(this, node, peContext);} catch (Exception e) {public ProcessEngine(String xmlStr) {this.xmlStr = xmlStr;//算子注册到引擎中,便于引擎调用之public void registNodeProcessor(IOperator operator) {type2Operator.put(operator.getType(), operator);public void start() throws Exception {peProcess = new XmlPeProcessBuilder(xmlStr).build();peContext = new PeContext();dispatchThread.setDaemon(true);dispatchThread.start();executeNode(peProcess.start.out.to);private void executeNode(PeNode node) {if (!node.type.equals("endEvent"))arrayBlockingQueue.add(node);elseSystem.out.println("process finished!");public void nodeFinished(String peNodeID) {PeNode node = peProcess.peNodeWithID(peNodeID);executeNode(node.out.to);
接下来,简单(简陋)实现本示例所需的三个算子,代码如下:
* 提交申请单public class OperatorOfApprovalApply implements IOperator {@Overridepublic String getType() {return "approvalApply";@Overridepublic void doTask(ProcessEngine processEngine, PeNode node, PeContext peContext) {peContext.putValue("form", "formInfo");peContext.putValue("applicant", "小张");processEngine.nodeFinished(node.id);* 审批public class OperatorOfApproval implements IOperator {@Overridepublic String getType() {return "approval";@Overridepublic void doTask(ProcessEngine processEngine, PeNode node, PeContext peContext) {peContext.putValue("approver", "经理");peContext.putValue("message", "审批通过");processEngine.nodeFinished(node.id);* 结果邮件通知public class OperatorOfNotify implements IOperator {@Overridepublic String getType() {return "notify";@Overridepublic void doTask(ProcessEngine processEngine, PeNode node, PeContext peContext) {System.out.println(String.format("%s 提交的申请单 %s 被 %s 审批,结果为 %s",peContext.getValue("applicant"),peContext.getValue("form"),peContext.getValue("approver"),peContext.getValue("message")));processEngine.nodeFinished(node.id);
运行一下,看看结果如何,代码如下:
public class ProcessEng.NETest {@Testpublic void testRun() throws Exception {//读取文件内容到字符串String modelStr = Tools.readResoucesFile("model/two/hello.xml");ProcessEngine processEngine = new ProcessEngine(modelStr);processEngine.registNodeProcessor(new OperatorOfApproval());processEngine.registNodeProcessor(new OperatorOfApprovalApply());processEngine.registNodeProcessor(new OperatorOfNotify());processEngine.start();Thread.sleep(1000 * 1);
小张 提交的申请单 formInfo 被 经理 审批,结果为 审批通过process finished!
到此,轻量级工作流引擎的核心逻辑介绍的差不多了,然而,只支持顺序结构是太单薄的,我们知道,程序流程的三种基本结构为顺序、分支、循环,有了这三种结构,基本上就可以表示绝大多数流程逻辑。循环可以看做一种组合结构,即:循环可以由顺序与分支推导出来,我们已经实现了顺序,那么接下来只要实现分支即可,而分支有很多类型,如:二选一、N选一、N选M(1<=M<=N),其中N选一可以由二选一的组合推导出来,N选M也可以由二选一的组合推导出来,只是比较啰嗦,不那么直观,所以,我们只要实现二选一分支,即可满足绝大多数流程逻辑场景,好,第三个迭代开始。
六、一般审批
作为一个流程管理员,我希望流程引擎可以运行如下图所示的流程,以便我能够配置流程来实现一般的审批流。

例如:小张提交了一个申请单,然后经过经理审批,审批结束后,如果通过,发邮件通知,不通过,则打回重写填写申请单,直到通过为止。
1、分析
2、设计
3、实现
新的XML定义如下:
flow_1flow_1flow_5flow_2flow_2flow_3flow_4approvalResultflow_3flow_4flow_5flow_4flow_6flow_6
其中,加入了simpleGateway这个简单分支节点,用于表示简单的二选一分支,当expr中的表达式为真时,走trueOutGoing中的出边,否则走另一个出边。
节点支持多入边、多出边,修改后的PeNode如下:
public class PeNode {public String id;public String type;public List in = new ArrayList<>();public List out = new ArrayList<>();public Node xmlNode;public PeNode(String id) {this.id = id;public PeEdge onlyOneOut() {return out.get(0);public PeEdge outWithID(String nextPeEdgeID) {return out.stream().filter(e -> e.id.equals(nextPeEdgeID)).findFirst().get();public PeEdge outWithOutID(String nextPeEdgeID) {return out.stream().filter(e -> !e.id.equals(nextPeEdgeID)).findFirst().get();
以前只有一个出边时,是由当前节点来决定下一节点的,现在多出边了,该由边来决定下一个节点是什么,修改后的流程引擎代码如下:
public class ProcessEngine {private String xmlStr;//存储算子private Map type2Operator = new ConcurrentHashMap<>();private PeProcess peProcess = null;private PeContext peContext = null;//任务数据暂存public final BlockingQueue arrayBlockingQueue = new LinkedBlockingQueue();//任务调度线程public final Thread dispatchThread = new Thread(() -> {while (true) {try {PeNode node = arrayBlockingQueue.take();type2Operator.get(node.type).doTask(this, node, peContext);} catch (Exception e) {e.printStackTrace();public ProcessEngine(String xmlStr) {this.xmlStr = xmlStr;//算子注册到引擎中,便于引擎调用之public void registNodeProcessor(IOperator operator) {type2Operator.put(operator.getType(), operator);public void start() throws Exception {peProcess = new XmlPeProcessBuilder(xmlStr).build();peContext = new PeContext();dispatchThread.setDaemon(true);dispatchThread.start();executeNode(peProcess.start.onlyOneOut().to);private void executeNode(PeNode node) {if (!node.type.equals("endEvent"))arrayBlockingQueue.add(node);elseSystem.out.println("process finished!");public void nodeFinished(PeEdge nextPeEdgeID) {executeNode(nextPeEdgeID.to);
新加入的simpleGateway节点算子如下:
* 简单是非判断public class OperatorOfSimpleGateway implements IOperator {@Overridepublic String getType() {return "simpleGateway";@Overridepublic void doTask(ProcessEngine processEngine, PeNode node, PeContext peContext) {ScriptEngineManager manager = new ScriptEngineManager();ScriptEngine engine = manager.getEngineByName("js");engine.put("approvalResult", peContext.getValue("approvalResult"));String expression = XmlUtil.childTextByName(node.xmlNode, "expr");String trueOutGoingEdgeID = XmlUtil.childTextByName(node.xmlNode, "trueOutGoing");PeEdge outPeEdge = null;try {outPeEdge = (Boolean) engine.eval(expression) ?node.outWithID(trueOutGoingEdgeID) : node.outWithOutID(trueOutGoingEdgeID);} catch (ScriptException e) {e.printStackTrace();processEngine.nodeFinished(outPeEdge);
其中简单使用了js脚本作为表达式,当然其中的弊端这里就不展开了。
为了方便同学们CC+CV,其他发生相应变化的代码如下:
* 审批public class OperatorOfApproval implements IOperator {@Overridepublic String getType() {return "approval";@Overridepublic void doTask(ProcessEngine processEngine, PeNode node, PeContext peContext) {peContext.putValue("approver", "经理");Integer price = (Integer) peContext.getValue("price");//价格<=200审批才通过,即:approvalResult=trueboolean approvalResult = price <= 200;peContext.putValue("approvalResult", approvalResult);System.out.println("approvalResult :" + approvalResult + ",price : " + price);processEngine.nodeFinished(node.onlyOneOut());* 提交申请单public class OperatorOfApprovalApply implements IOperator {public static int price = 500;@Overridepublic String getType() {return "approvalApply";@Overridepublic void doTask(ProcessEngine processEngine, PeNode node, PeContext peContext) {//price每次减100peContext.putValue("price", price -= 100);peContext.putValue("applicant", "小张");processEngine.nodeFinished(node.onlyOneOut());* 结果邮件通知public class OperatorOfNotify implements IOperator {@Overridepublic String getType() {return "notify";@Overridepublic void doTask(ProcessEngine processEngine, PeNode node, PeContext peContext) {System.out.println(String.format("%s 提交的申请单 %s 被 %s 审批,结果为 %s",peContext.getValue("applicant"),peContext.getValue("price"),peContext.getValue("approver"),peContext.getValue("approvalResult")));processEngine.nodeFinished(node.onlyOneOut());public class XmlPeProcessBuilder {private String xmlStr;private final Map id2PeNode = new HashMap<>();private final Map id2PeEdge = new HashMap<>();public XmlPeProcessBuilder(String xmlStr) {this.xmlStr = xmlStr;public PeProcess build() throws Exception {//strToNode : 把一段xml转换为org.w3c.dom.NodeNode definations = XmlUtil.strToNode(xmlStr);//childByName : 找到definations子节点中nodeName为process的那个NodeNode process = XmlUtil.childByName(definations, "process");NodeList childNodes = process.getChildNodes();for (int j = 0; j < childNodes.getLength(); j++) {Node node = childNodes.item(j);//#text node should be skipif (node.getNodeType() == Node.TEXT_NODE) continue;if ("sequenceFlow".equals(node.getNodeName()))buildPeEdge(node);elsebuildPeNode(node);Map.Entry startEventEntry = id2PeNode.entrySet().stream().filter(entry -> "startEvent".equals(entry.getValue().type)).findFirst().get();return new PeProcess(startEventEntry.getKey(), startEventEntry.getValue());private void buildPeEdge(Node node) {//attributeValue : 找到node节点上属性为id的值PeEdge peEdge = id2PeEdge.computeIfAbsent(XmlUtil.attributeValue(node, "id"), id -> new PeEdge(id));peEdge.from = id2PeNode.computeIfAbsent(XmlUtil.attributeValue(node, "sourceRef"), id -> new PeNode(id));peEdge.to = id2PeNode.computeIfAbsent(XmlUtil.attributeValue(node, "targetRef"), id -> new PeNode(id));private void buildPeNode(Node node) {PeNode peNode = id2PeNode.computeIfAbsent(XmlUtil.attributeValue(node, "id"), id -> new PeNode(id));peNode.type = node.getNodeName();peNode.xmlNode = node;List inPeEdgeNodes = XmlUtil.childsByName(node, "incoming");inPeEdgeNodes.stream().forEach(n -> peNode.in.add(id2PeEdge.computeIfAbsent(XmlUtil.text(n), id -> new PeEdge(id))));List outPeEdgeNodes = XmlUtil.childsByName(node, "outgoing");outPeEdgeNodes.stream().forEach(n -> peNode.out.add(id2PeEdge.computeIfAbsent(XmlUtil.text(n), id -> new PeEdge(id))));
运行一下,看看结果如何,代码如下:
public class ProcessEngineTest {@Testpublic void testRun() throws Exception {//读取文件内容到字符串String modelStr = Tools.readResoucesFile("model/third/hello.xml");ProcessEngine processEngine = new ProcessEngine(modelStr);processEngine.registNodeProcessor(new OperatorOfApproval());processEngine.registNodeProcessor(new OperatorOfApprovalApply());processEngine.registNodeProcessor(new OperatorOfNotify());processEngine.registNodeProcessor(new OperatorOfSimpleGateway());processEngine.start();Thread.sleep(1000 * 1);
approvalResult :false,price : 400approvalResult :false,price : 300approvalResult :true,price : 200小张 提交的申请单 200 被 经理 审批,结果为 trueprocess finished!
至此,本需求实现完毕,除了直接实现了分支语义外,我们看到,这里还间接实现了循环语义。
作为一个轻量级的工作流引擎,到此就基本讲完了,接下来,我们做一下总结与展望。
七、总结与展望
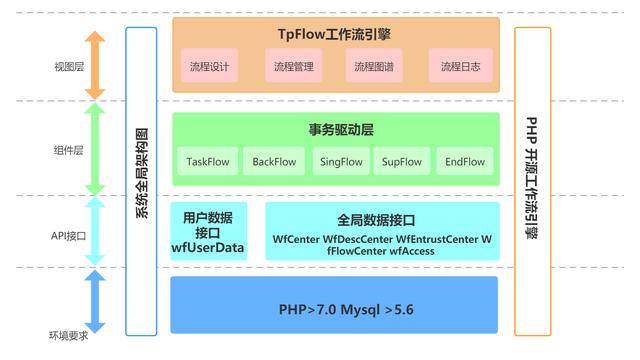
经过以上三个迭代,我们可以得到一个相对稳定的工作流引擎的结构,如下图所示:

通过此图我们可知,这里有一个相对稳定的引擎层,同时为了提供扩展性,提供了一个节点算子层,所有的节点算子的新增都在此处中。
此外,进行了一定程度的控制反转,即:由算子决定下一步走哪里,而不是引擎。这样,极大地提高了引擎的灵活性,更好的进行了封装。
最后,使用了上下文,提供了一种全局变量的机制,便于节点之间的数据流动。
当然,以上的三个迭代距离实际的线上应用场景相距甚远,还需实现与展望以下几点才可,如下:
作者:刘洋