在过去的五个月里,我一直在我当前的项目中使用 Spring Webflux,我还编写了很多 Nodejs 应用程序,并且使用 Promise 样式编码(async/awAIt)的方式也几乎相同,而 Webflux 使用 Mono/Flux。
Nodejs 和 Spring Webflux 之间的区别是什么,因为它们都在解决同一个问题,专注于事件循环。
Node.js 是一个构建基于 Chrome V8 JAVAScript 引擎的事件驱动服务器应用程序的平台。
.NETty 是一个事件驱动的框架,用于在 Java 平台上构建服务器应用程序。
让我们看看基于以下几点的比较,了解设计方法和内部发生了什么不同之处?
线程模型
在决定任何框架之前,需要了解线程建模。
Nodejs:
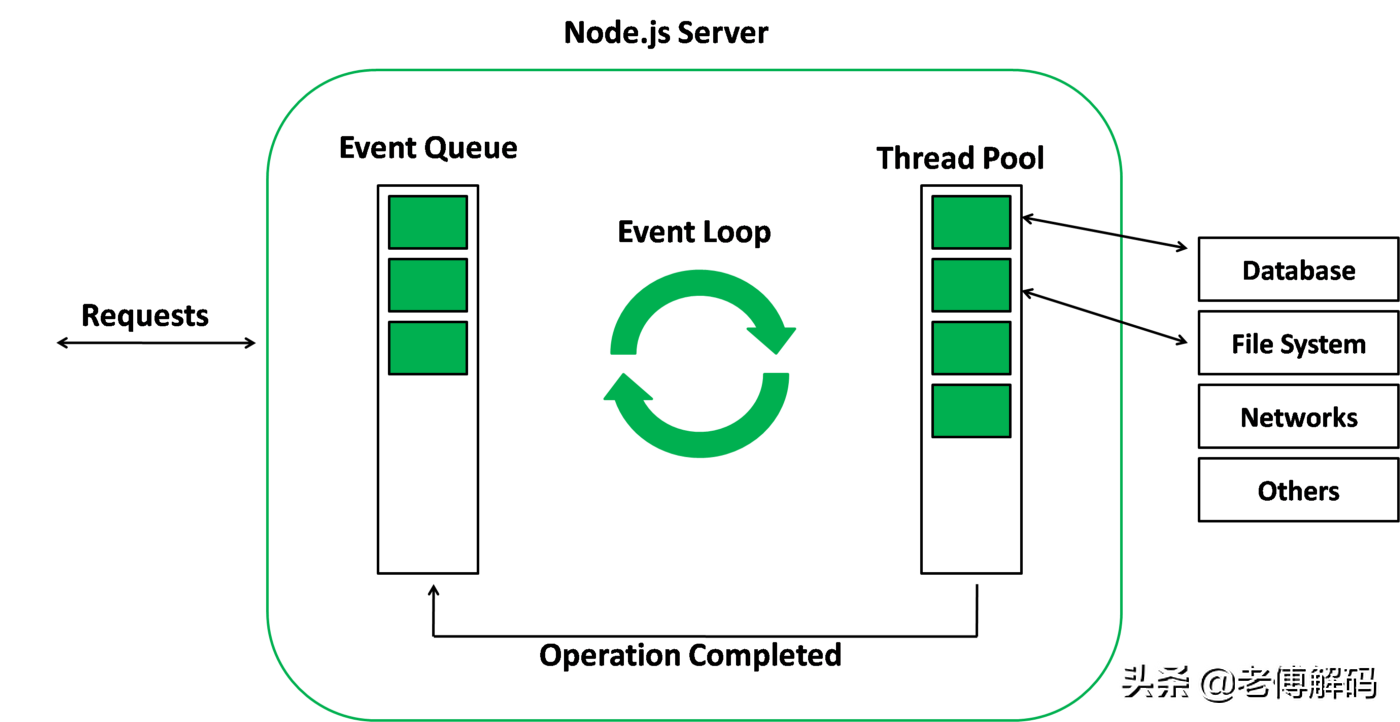
- Node.js并不是单纯的单线程,它用主线程处理所有请求,然后对I/O操作进行异步处理,交给其他线程去执行,避免了频繁创建、销毁和上下文切换带来的系统开销。下面来看Node.js的工作原理。

从左到右,从上到下,Node.js 被分为了四层,分别是 应用层、V8引擎层、Node API层 和 LIBUV层。
应用层: 即 JavaScript 交互层,常见的就是 Node.js 的模块,比如 http,fs
V8引擎层: 即利用 V8 引擎来解析JavaScript 语法,进而和下层 API 交互
NodeAPI层: 为上层模块提供系统调用,一般是由 C 语言来实现,和操作系统进行交互
LIBUV层: 是跨平台的底层封装,实现了 事件循环、文件操作等,是 Node.js 实现异步的核心
Node.js在主线程维护了一个事件队列,接收到请求后,就将该请求作为一个事件放入Event Queue中,然后继续接受其他请求,当主线程空闲(没有请求接收) 的时候,就开始轮询事件队列
Webflux:
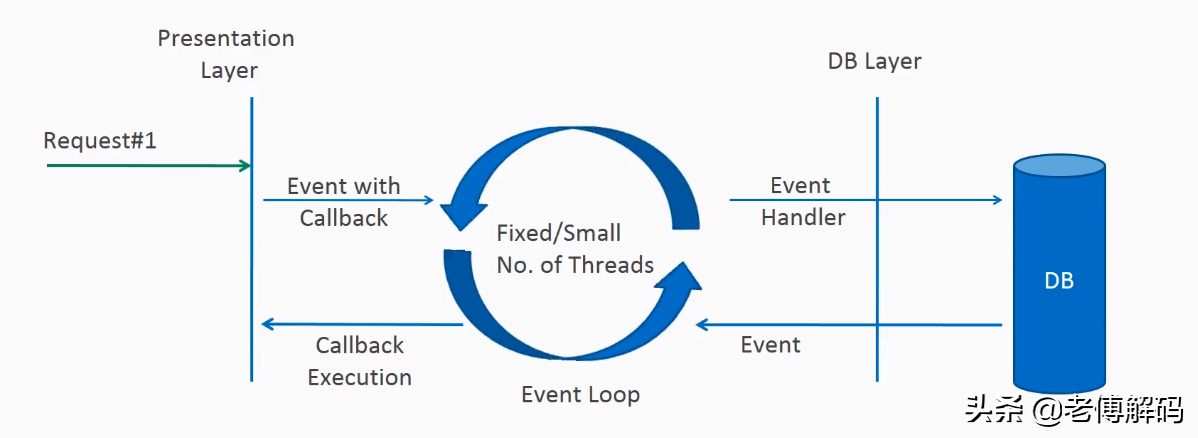
- 接收客户端连接是一个独立的线程池。Acceptor接收到客户端TCP连接请求处理完成后(可能包含接入认证等),将新创建的SocketChannel注册到I/O线程池(sub reactor线程池)的某个I/O线程上,由它负责SocketChannel的读写和编解码工作。
- Acceptor线程池只用于客户端的登录、握手和安全认证,一旦链路建立成功,就将链路注册到后端subReactor线程池的I/O线程上,有I/O线程负责后续的I/O操作。
异步操作
Nodejs:
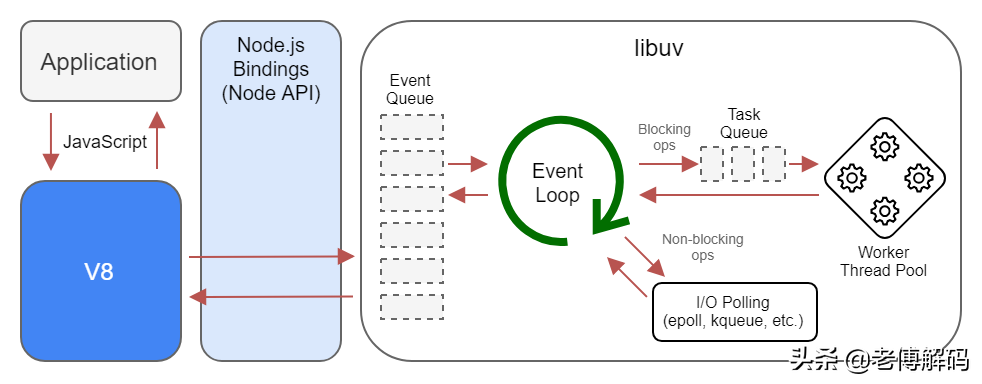
- Nodejs 内部使用 Libuv 来处理异步任务。它将现代内核所能做的尽可能多的调度到操作系统内核。
- 如果 Libuv 无法将任务委托给内核,则它使用其创建的线程池(默认 4 个线程)来处理工作。
Webflux:
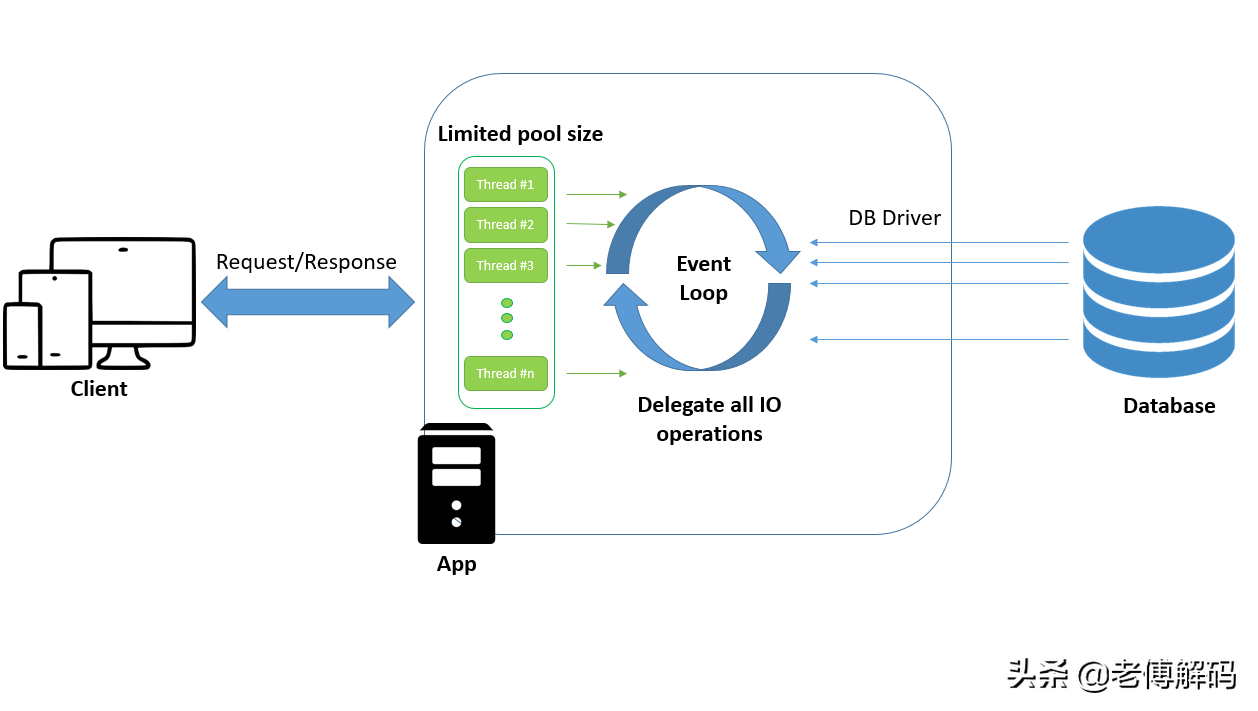
- 在 Netty 4 中,所有 I/O 操作和事件都由分配给事件循环的同一线程处理。
- 而在 Netty 3 中,入站事件有一个单独的事件循环,在 I/O 线程池中处理,出站事件可能在 I/O 线程池或另一个池中。
事件循环结构
Nodejs:
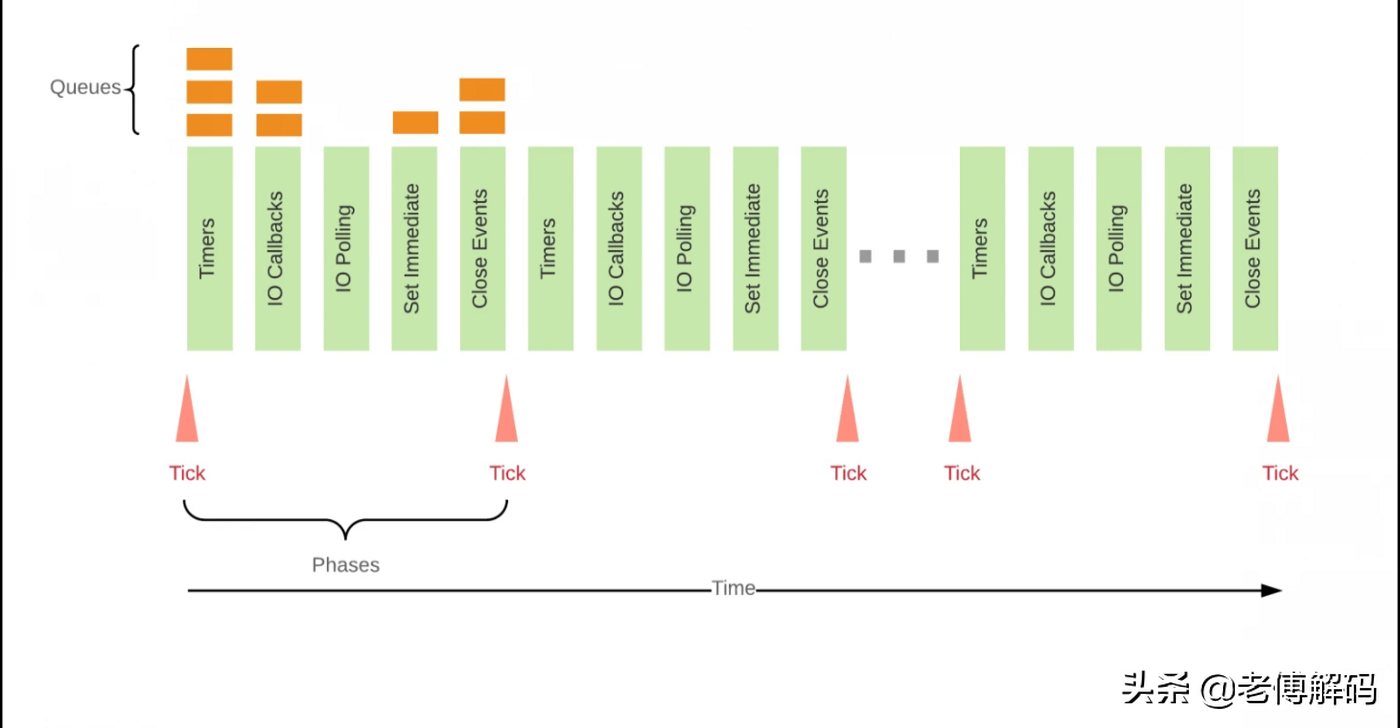
- Event Loop 有多个阶段来处理事件,它们是计时器、挂起回调、空闲和准备、轮询、检查和关闭回调。
Webflux:
- 事件循环有它的任务队列。
- 每当应用程序收到新请求时,它都会存储在 Java 堆中,其中一个事件循环将从 Java 堆中选择它并进行处理。
事件循环中的任务调度
Nodejs:
- 所有通过 setTimeout() 或 setInterval() 调度的内容都将在事件循环的计时器阶段进行处理。
Webflux:
- 我们可以使用事件循环来调度任务。这里的事件循环继承ScheduledExecutorService执行线程池管理。
- 如果我们直接使用 ScheduledExecutorService,那么在高负载下,这会带来性能成本,并且如果任务被频繁调度,可能会成为瓶颈。
CPU 利用率
Nodejs:
- Node.js 应用程序在单个线程上运行。在多核机器上,这意味着负载不会分布在所有内核上。
- 使用 Node 附带的集群模块,可以很容易地为每个 CPU 生成一个子进程。
- 每个子进程都维护自己的事件循环,主进程透明地在所有子进程之间分配负载。
Webflux:
- 如果我们需要运行一个长时间运行的任务,那么最好创建一个单独的线程执行器池并在那里处理它。事件循环稍后可以选择返回的结果,避免事件循环解除对长任务的阻塞。
- 我们还可以增加事件循环实例来提高 CPU 利用率。
调整线程池
Nodejs:
- 可以通过设置环境变量 UV_THREADPOOL_SIZE 来覆盖池的默认大小。
Webflux:
处理背压问题
软件系统中的背压是使流量通信过载的能力。换句话说,信息流的生产速度超过消费速度。
Nodejs:
- 被调用的 HTTP 服务器在 1s 后返回数据以模拟慢速后端。当等待后端返回的请求在 Node 内部堆积时,可能会导致背压。
- 为了在流中实现背压,我们可以使用具有高水位标记的可读可写流来有效地处理数据生产者和消费者之间的背压。
webflux:
- 背压的责任由 Project Reactor 管理。它在内部使用 Flux 功能控制发射器产生的事件。
- Webflux 使用 TCP 流量控制来调节背压。
- Flux 中提供了三种方法,我们可以使用它们来控制背压。
- 选项 1:使用request(),消费者可以控制让发布者等到它收到新事件的请求。简而言之,消费者订阅事件并根据需求进行处理。
- 选项 2:使用limitRange(),我们正在设置一次预取的项目数。即使消费者请求处理更多事件,该限制也适用。发布者将事件分成块,避免消耗超过每个请求的限制。
- 选项 3:使用cancel(),消费者可以随时取消要接收的事件。我们可以取消订阅并稍后再次订阅以继续接收下一个事件。
- 为了处理客户端和服务器之间的背压,我们可以Channel.isWritable() 通过调用 Channel.write()来检查是等待还是发送下一个事件,或者我们也可以列出fireChannelWritabilityChanged事件来决定何时向通道发送更多数据.
基于以上几点,我认为没有一个比另一个更好,因为两者都有一些优点和缺点。但在大多数方面,它们在性能方面是相同的。因此,可以根据技能可用性、团队技术方向、项目生态系统等来做出决定。
声明:本站部分内容及图片来自互联网,转载是出于传递更多信息之目的,内容观点仅代表作者本人,不构成投资建议。投资者据此操作,风险自担。如有任何标注错误或版权侵犯请与我们联系,我们将及时更正、删除。