作者 | 云昭
可观测对于微服务盛行的年代来讲,十分必要。成千上万的微服务给开发和运维团队带来了指数级的维护成本。要解决这个难题,就势必引入高效的监控工具来辅助技术管理和决策。而K8s作为当下微服务领域的一个热门选手,如何有效选择和部署监控K8s集群工具就成为了一个大家共同关注的话题。
PART 01
问题
在K8s环境中,应用程序运行在跨集群内的多个节点,同时服务也将分布在多个集群和多个云中,这就使得追踪、监控这些应用程序及其所依赖的基础设施的健康状况,非常具有挑战性。
K8s监控涉及从K8s集群收集指标、识别关键事件,目的是确保所有硬件、软件和应用程序按预期运行。因此,将指标集中汇总在一个中心位置,将有效帮助开发者了解和维护整个 K8s队列以及在其上运行的应用或服务的健康状况。
而要做到全方位监控非常困难,其中的两个难点在于:
1、容器化和K8s创建的抽象层之间的监控;
2、K8s环境中运行的应用程序的动态特性之间的监控。
这篇文章探讨了一些不错的K8s监控和日志工具,包括用于监控的Prometheus和用于可视化和仪表板的Grafana等。
PART 02
K8s可观测工具
目前业界流行的用于K8s容器监控的开源工具并不少,比较常见的有:Prometheus、Grafana、Elasticsearch、Thanos等。
1. Prometheus
Prometheus是一个开源系统监控和警报工具包,最初在 SoundCloud 构建,灵感来自 google 使用的 Borgmon 工具。自 2012 年成立以来,许多公司和组织都采用了 Prometheus,该项目拥有非常活跃的开发者和用户社区。
Prometheus 于 2016 年加入云原生计算基金会,成为继K8s之后的第二个托管项目。虽然本文在K8s监控的背景下讨论 Prometheus,但它可以满足各种各样的监控需求,比如帮助简化指标收集、关联事件和警报、提供安全性以及进行大规模故障排除和跟踪。
Prometheus的主要功能之一就是指标收集,这里的指标是什么?这要根据用户想要测量的内容或应用程序而异。对于 Web 服务器,它可能是请求时间,对于数据库,它可能是活动连接数或活动查询数等。Prometheus收集并存储用户指定的指标作为时间序列数据。可以分析指标以了解集群及其组件的运行状态。
Prometheus的可靠性非常出色。这有助于确保在用户的环境中出现其他问题时,Prometheus仍然可以访问。每个Prometheus服务器都是独立的。本地时间序列数据库使其独立于远程存储或其他远程服务。这有助于快速识别问题并接收有关受监控集群和应用程序系统性能的实时反馈。
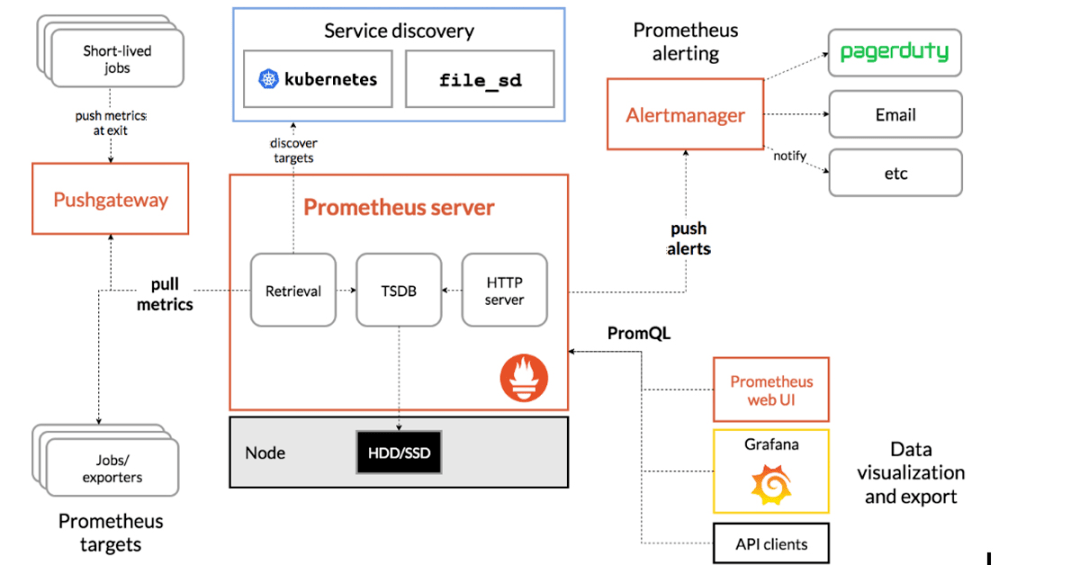
Prometheus的主要组件,包括Prometheus服务器和Alertmanager,整体架构如下图所示。虽然Prometheus提供了 Web UI,但它通常与Grafana结合使用以实现更灵活的可视化。
2. Grafana
Grafana是一个完全托管的应用程序和基础设施可视化平台,可与Prometheus等监控软件配合使用。Prometheus和Grafana的组合正在成为 devops 团队用于存储和可视化时间序列数据的越来越常见的监控堆栈。Prometheus作为存储后端,Prafana作为分析和可视化的接口。

3. Thanos
Thanos作为度量(Metric)系统,它提供了一种简单且经济高效的方式来集中和扩展基于Prometheus的监控系统。
4. Elasticsearch(ES)
Elasticsearch是一个分布式、RESTful风格的搜索和数据分析引擎。它几乎适用于所有数据类型:数字、文本、地理位置、结构化数据、非结构化数据等。

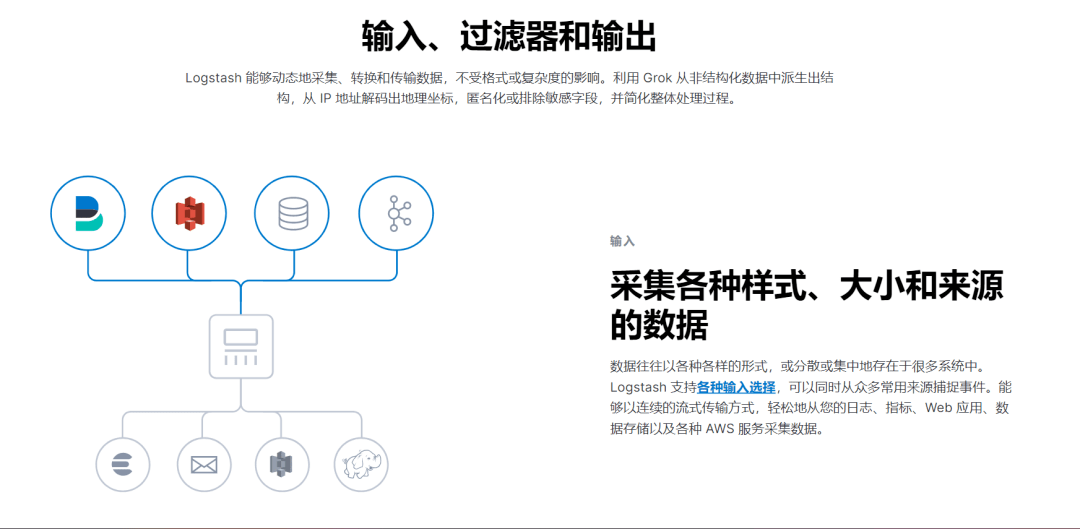
5. Logstash
Logstash是一个开源的服务器端数据处理管道,可同时从多个来源获取数据,并对其进行转换,然后将其发送到合适的存储区。
6. Kibana
Kibana提供了 Elasticsearch 数据进行可视化的免费开放的用户界面,并允许用户在Elastic Stack中进行导航。它提供了一种数据可视化和探索工具,用于日志和时间序列分析、应用程序监控和运营智能用例。从跟踪查询负载,到理解请求在整个应用的运转,都能有效完成。
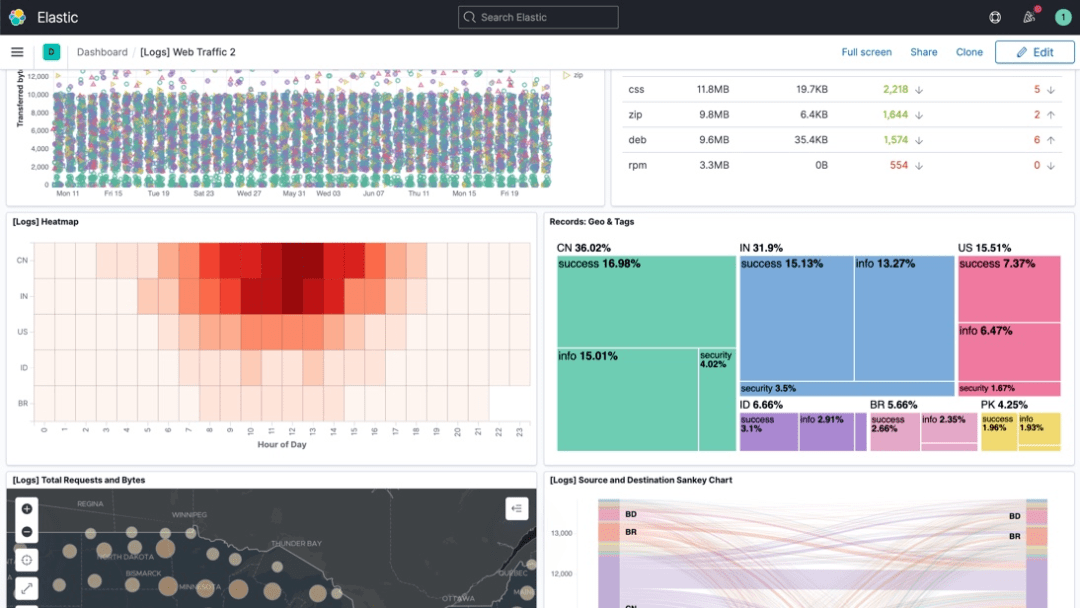
许多团队单独或组合使用这些监控和日志记录工具来创建自己的解决方案并解决特定的容器监控和K8s应用程序监控需求。目前市面上比较流行的K8s监控工具组合大体上可以分为两种:
Prometheus+Grafana,Elasticsearch+Logstash+Kibana。后者通常被称为ELK堆栈或Elastic Stack,目前这套组合是免费和开源的。
PART 03
注意事项
无论是单独部署还是组合部署,监控工具的使用都必然会带来一定的复杂性,尤其当遇到情况复杂的K8s集群时——可能在不同的云环境中运行不同的K8s发行版,难度将陡然增加。
一般来说,需要注意以下几点:
1. Prometheus单独配置不适用于大规模场景
由于应用程序载入问题、手动配置门槛较高、配置不同步,大规模的Prometheus配置管理会给开发运维团队带来十分艰巨的挑战。
举个例子,截至 2019 年底,Uber 的工作负载已增长到 4,000 多个微服务。要管理和操作此类复杂的应用程序,技术团队需要更加高级的可观测性,这需要为每个应用程序进行抓取、仪表板和警报的专用配置。而创建这些配置,并将它们应用到每个环境——通常是手动完成,并且每次发生变化时都以临时方式完成,这对于一家起来说是难以承担的。
2. Prometheus和Grafana在多集群环境中适用性有限制
虽然Prometheus和Grafana可以很好地协同用于单个集群,但在多集群环境中,用户可能必须将Thanos添加到用户的工具集中以聚合数据并提供长期存储和全局视图。用户仍然可能面临数据保留和HA(高可用性)的限制,导致一些人更喜欢 ELK 堆栈。
基于这种多集群的复杂性,许多公司团队更喜欢使用 Datadog、Cloudwatch 和 New Relic 等商业解决方案将监控作为服务。
PART 04
写在最后
K8s对于当下的大规模应用的技术架构的重要性不言而喻。而K8s的可观测性(监控)工具目前也成为了开发运维团队绕不过去的一道门槛。不管是Prometheus、Grafana 还是ELK,这些工具在业务中已经得到了不错的性能验证,希望本文可以给大家到来一些有益的思考。
参考资料:
https://dzone.com/articles/kube.NETes-monitoring-with-prometheus
https://prometheus.io/docs/