Kube.NETes(K8s)非常火,但被人诟病最多的还是其复杂性,并且不管是在云中还是本地,都没有很好的集群故障排除的方法。因此,尽管K8s的采用率持续增长,但许多开发人员和运维团队对这项较新的技术感到吃力,为此必须学习新的术语、工作流程、工具等。
K8s的分立部件需要广泛的专业知识,即使只是在设置过程中。考虑到旋转K8集群需要了解和配置从pods到服务的多个组件,更不用说etcd、API服务器、kubelet和kube-proxy等资源了。
然后是规划、扩展和网络建设。一个失误可能很快转化为无数的可扩展性、可靠性甚至安全性问题。
此外,生态系统本身也在不断快速增长和演变。对于初学者来说,工具和附加组件可能很多,而且很难跟上。并不是每个开发者都专门接受过K8s技能的培训。
我们不能忘记,这项技术有许多移动部件和复杂的相互作用,当发生故障时,进行故障排除可能既困难又耗时。诊断故障原因需要深入的技术知识和专业知识,而这些知识和专业技能往往存在于少数经验丰富的工程师的头脑中。
让我们深入研究,探索有助于克服明显技能差距问题的新的创新方法。
Kubernetes很难有效地学习和使用,因为没有一刀切的方法。K8s是高度可定制的,可以根据应用程序或基础设施的具体需求以多种不同的方式进行配置。通常很难将您从文档(而且有很多)和培训中学到的东西应用到现有的环境中,因为团队缺乏对其架构的上下文理解和可见性。
当前的体系结构是什么样子的?哪些pod绑定到特定的命名空间?节点的运行状况如何?询问我们环境的基本问题需要在AWS控制台、kubectl命令行、Terraform配置文件和监控工具之间进行上下文切换。
如果我们可以问ChatGPT这些问题呢?
让我们看一个使用由ChatGPT提供支持的PromptOps来理解集群中所有部署的示例。PromptOps提供了一个免费的Kubernetes咨询工具,用户可以通过BASH脚本、文档参考和其他有用资源的形式提出问题并获得即时帮助。
通过提供来自不同来源的PromptOps基础设施的碎片数据,如Confluence、Notion、Terraform配置文件等,我们希望PromptOps能够快速聚合所有信息,并帮助可视化架构。我们没有手动运行kubectl命令来检查部署,而是在聊天中提示PromptOps来描述集群中存在的部署。
以下是PromptOps的回应:
PromptOps > I suggest running this script to answer your question.
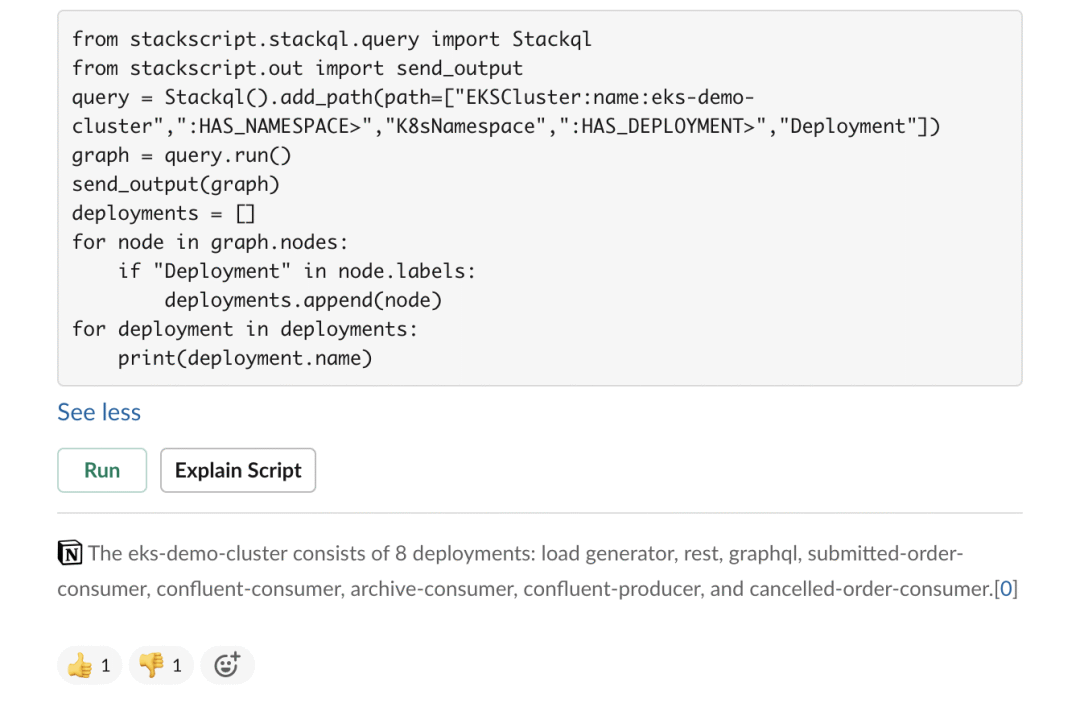
PromptOps提供了一个要运行的脚本,并引用了一个包含集群信息的Notion页面。在执行脚本时,PromptOps提供集群内部署的输出。

PromptOps还提供了集群中所有部署的可视化图,使学习更加容易。
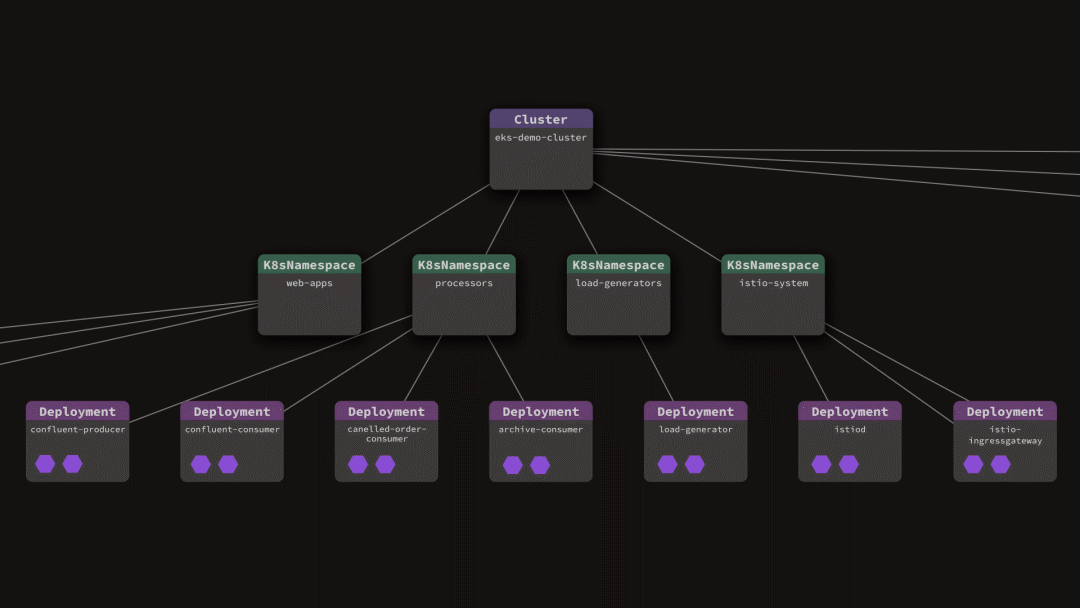
PromptOps的响应简化了Kubernetes基础设施管理,使DevOps团队中的每个人都能跟上当前架构的步伐并跟上变化。
让我们看看生产问题的疑难解答,看看PromptOps如何帮助确定Kubernetes中故障的根本原因。Kubernetes度量和日志提供了从集群到容器的所有级别的关键见解。它们提供有关资源利用率、pod和节点状态、集群自动缩放指标、网络错误、容器运行时间等信息。
但所有这些指标的问题在于,它们并没有立即发挥作用。日志流或度量图表无法提供必要的上下文或方向。有一些工具可以提供帮助,但它们往往会使事情变得更加复杂,需要在整个技术堆栈中提取上下文,以查看真正发生了什么,或者在出现问题时谁做了什么。在CtrlStack,我们一直在结合PromptOps来分析因果图、Kubernetes事件、指标和日志,以减少手动故障排除的挑战。目标是通过使用PromptOps生成解释原因的根本原因分析摘要,帮助DevOps团队快速理解Kubernetes问题。在本例中,CtrlStack中的根本原因分析仪表板的因果图被输入到PromptOps中,以进行故障排除和解决,如下所述。
下面是一个根本原因分析面板的随意图形示例。
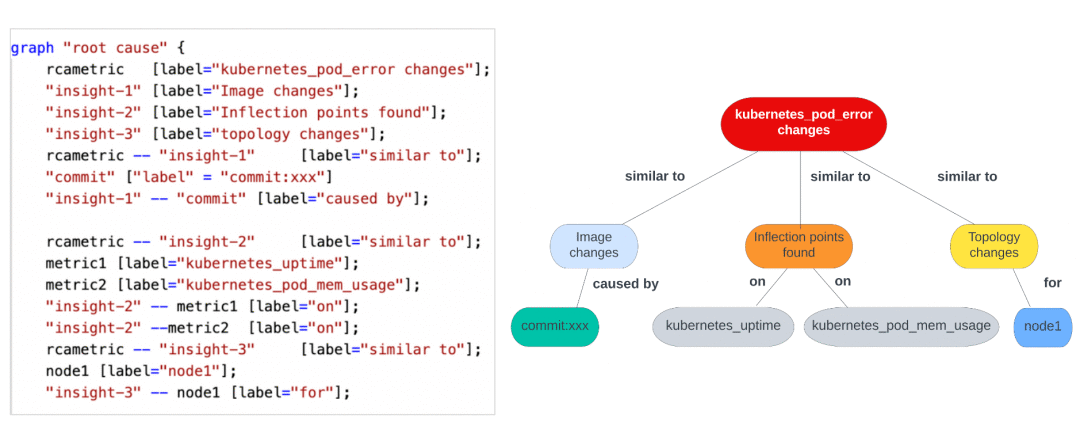
有了这个,我们提示PromptOps解释这个图。以下是PromptOps的回应:
PromptOps>以下是对图形的解释:
该图显示了Kubernetes pod中错误的根本原因。该错误是由pod映像中的更改引起的,这些更改类似于Kubernetes pod_error度量中的更改。该错误也类似于在kubernetes_ptime和kubernetes_pod_mem_usage度量中发现的拐点,以及node1中的拓扑变化。
该图显示了kubernetes_po_error更改的根本原因。有三个见解。首先是图像发生了变化。第二个是在度量kubernetes_ptime和kubernetes_pod_mem_usage中发现了拐点。第三个是节点1的拓扑结构发生了变化。
PromptOps返回了正常运行时间和内存使用指标之间的信息相关性,以及相关的拓扑变化。这些见解包括检查Kubernetes的更改事件、度量、资源使用情况和拓扑结构更改。基于这种自动事件调查,开发人员和操作员应该有足够的上下文来快速确定解决问题的下一步措施。
根据提供的例子,很明显,ChatGPT可以提供宝贵的帮助来缩小Kubernetes的技能差距。ChatGPT为DevOps团队提供了快速的见解和清晰的解释,以解决生产问题。这使初级运营商和初涉Kubernetes的开发人员能够独立学习技术并解决常见问题。
虽然ChatGPT的响应可以快速了解问题,但它需要特定于Kubernetes部署的不同问题的上下文信息。这就是Change AI的用武之地。Change AI平台提供了因果图,将资源容量、基础设施变化、配置变化、指标历史图表和事件时间表联系起来,以优化根本原因分析的路径。
基于ChatGPT的Kubernetes学习方法有可能显著提高DevOps的生产力,同时消除认知过载。通过将ChatGPT与Change AI相结合,团队可以将他们的Kubernetes技能提高一倍,并获得更好的可观察性。
原文链接:https://thenewstack.io/overcoming-the-kubernetes-skills-gap-with-chatgpt-assistance/