前不久作为架构师完成了某知名快消企业的一个业务中台建设。系统上线后,经历了双十一活动的流量高峰,整体运行稳定。最近有空,便将此次架构的思路,心得稍作整理在这篇博客中分享一下。不会深入每一个技术细节,而是把用到的技术、框架、工具做一个简单的回顾,作为日后的参考。
业务架构方面,该系统作为业务中台,主要负责客户资产管理,包括客户的卡、券以及其他虚拟资产。通过对外暴露标准restful接口的方式提供服务。服务的调用方包括自有渠道的App、小程序,以及合作伙伴渠道,包括招行、阿里等。而系统本身也会通过服务网关去调用公司内部的其他业务系统接口,如通过客户中心接口同步会员信息等。

根据目前的统计,这个业务中台,每日的服务调用量在700万次左右,有活动时也会超过1000万次。而大部分交易,发生在上班、午休以及下午3点左右(下午茶)的时间段内。

由于涉及到客户业务细节,这里对业务架构就不做详细说明了。
这个案例中采用了基于SpringBoot的微服务架构。结合企业自身的基础架构设施,进行K8S容器化部署,并采用Kong API Gateway对各业务中台暴露的API接口进行统一管理。
随着微服务架构在企业中的流行,原来大而全的系统被拆分为粒度较小的中台,而系统中的大部分功能则被以restful API形式提供的服务所取代,这使得IT系统能够更加快速地响应业务变化带来的挑战,但同时随着服务的增加,如何有效管理这些服务却成为难题。

在一些中小型项目中,我们一般都会采用Spring Cloud的技术栈,并选择Spring Cloud Gateway来作服务网关。然而,对于一些大型企业,则需要全局考虑服务的治理,网关性能,以及其他扩展功能。
在这个案例中,企业使用了Kong作为API网关。中台将需要开放外部使用的API,通过网关控制台进行注册,添加证书,生成Auth Key供关联方使用。
Kong具有以下一些特性,能够很好地满足大型组织对于服务网关的需求:

整个系统采用JAVA开发后端以及vue开发前端,应用部分共分为4个服务组件,全部进行容器化部署,并通过Ingress Controller负载均衡对外暴露服务:

除控制台前端外,其他三个组件均采用目前主流的java微服务框架SpringBoot 2.3.4开发(考虑到稳定性,未使用最新的2.4版本)。
本案例中,通过开发应用框架,实现了系统中数据表达形式的统一,以及标准的据转换、校验、消息绑定、错误处理等功能。架构师需要对应用框架负责,简明、高效、统一的应用框架,能够提升开发效率,产出标准一致的代码,保证交付质量。
应用框架不在本文的讨论范围内,而以下一些技巧或第三方包,却在我们构建大多数SpringBoot应用中得到使用。
####定制MyBatis 数据层框架采用MyBatis,在大型应用中MyBatis能够帮助程序员更好地控制数据层交互,并进行调优。一般可以在applicaion.yml中配置MyBatis,但当我们需要让MyBatis支持更多定制特性(如:多数据库支持)时,可以通过定义SqlSessionFactory bean来实现。
@Bean
public SqlSessionFactory sqlSessionFactory(DataSource dataSource) throws Exception {
SqlSessionFactoryBean sfb = new SqlSessionFactoryBean();
sfb.setDataSource(dataSource);
sfb.setVfs(SpringBootVFS.class);
Properties props = new Properties();
props.setProperty("dialect", dataConfiguration.getDialect());
props.setProperty("reasonable", String.valueOf(dataConfiguration.isPageReasonable()));
PageHelper pagePlugin = new PageHelper();
pagePlugin.setProperties(props);
Interceptor[] plugins = {pagePlugin};
sfb.setPlugins(plugins);
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
sfb.setMapperLocations(resolver.getResources("classpath*:mappers/"+ dataConfiguration.getDialect()+"/*.xml"));
sfb.setTypeAliasesPackage("com.xxx.bl.core.data.model");
SqlSessionFactory factory = sfb.getObject();
factory.getConfiguration().setMapUnderscoreToCamelCase(true);
// factory.getConfiguration().addInterceptor(new CoreResultSetHandler());
factory.getConfiguration().setCallSettersOnNulls(dataConfiguration.isCallSettersOnNulls());
return factory;
}
复制代码使用logback日志组件
采用logback日志框架,可以在logback配置文件中指定针对不同的Spring profile在不同的环境中采用不同的日志级别,并采用不同的appender。同时引入spring-cloud-starter-sleuth依赖,通过设置traceId,使整个请求全链路上的所有日志打印出一致的traceId,大大方便了各系统间生产问题的协同排查。另外,采用异步方式记录日志,也有利于降低IO阻塞。
<springProfile name="stg">
<root level="error">
<appender-ref ref="STDOUT"/>
<appender-ref ref="SAVE-ERROR-TO-FILE-STG"/>
</root>
<logger name="org.xxx" level="error" additivity="false">
<appender-ref ref="STDOUT"/>
<appender-ref ref="ASYNC-SAVE-TO-FILE-STG"/>
</logger>
</springProfile>
<springProfile name="prod">
<root level="error">
<appender-ref ref="STDOUT"/>
<appender-ref ref="SAVE-ERROR-TO-FILE-PROD"/>
</root>
<logger name="org.xxx" level="error" additivity="false">
<appender-ref ref="ASYNC-SAVE-TO-FILE-PROD"/>
</logger>
</springProfile>
复制代码SSL加密及密码安全
全链路传输加密已成为企业安全中必不可少的措施。通过在classpath中引入CA颁发(也可以使用自签)的jks证书,并在application配置文件中进行简单配置,便可实现SpringBoot应用的SSL加密。
ssl:
enabled: true
key-store: classpath:xxx.net.jks
key-store-type: JKS
key-store-password: RUIEIoUD
key-password: RUIEIoUD
require-ssl: true
复制代码密码以明文形式存放在配置文件中,也是不安全的。你可以jasypt加密配置文件中使用到的密码,或者直接使用Key-Vault方案,比如本案例中会分别在微软云环境中使用Azure Key Vault或本地IDC中使用Cyberark Conjur方案。
###同步与异步服务 我们并没有使用Spring Webflux来支持reactive特性,因为,这会增加开发复杂度,并且Webflux虽然改善了Web容器阻塞机制,但并不能从根本上解决高并发请求到来时的阻塞问题。
在这个案例中,通过搭建了3个节点的RabbitMq镜像集群,作为消息中间件,并通过应用框架的支持,实现了服务的同步异步切换功能。我们将对外提供的服务注册到数据库中,在应用启动时,读入redis缓存。当请求到来时,通过API code判断该请求的响应模式:同步或异步。如果是同步请求则直接处理,而如果是异步请求,则发送到RabbitMq中,再由经过封装的消费者组件进行异步消费,最终达到削峰的目的。

对于开发人员来说,他们只需要关注服务的业务逻辑开发,由应用框架统一处理服务的同步,异步切换,消息发送或失败时的异常处理,以及死信队列的维护等工作。
Dockerfile
案例中的四个组件需要实现容器化部署,分别为SpringBoot应用与Vue应用创建Dockerfile。
典型的SpringBoot应用Dockerfile如下,一般情况下大型组织会构建私有镜像仓库,通过私有仓库拉取镜像的速度更快,能够节省CICD的时间。
FROM openjdk:11-jre
#FROM cargo.xxx.net/library/openjdk:11-jre
ARG JAR_FILE=console-service/build/libs/*.jar
COPY ${JAR_FILE} app.jar
EXPOSE 9002
EXPOSE 9003
ENTRYPOINT [ "java", "-jar", "/app.jar" ]
复制代码vue应用的Dockerfile如下,同样添加了SSL证书,进行传输加密:
FROM cargo.xxx.net/library/nginx:stable-alpine
COPY /dist /usr/share/nginx/html/console
COPY nginx.conf /etc/nginx/nginx.conf
ARG KEY_FILE=stg.xxx.net.key
ARG PEM_FILE=stg.xxx.net.pem
COPY ${KEY_FILE} /etc/ssl/certs/cert.key
COPY ${PEM_FILE} /etc/ssl/certs/cert.pem
EXPOSE 80
CMD [ "nginx", "-c", "/etc/nginx/nginx.conf", "-g", "daemon off;" ]
复制代码编写dockerfile时有以下一些注意事项:
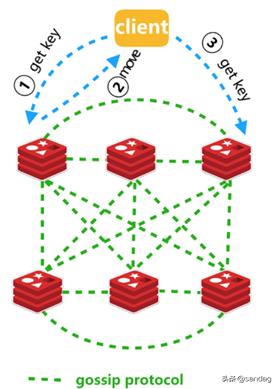
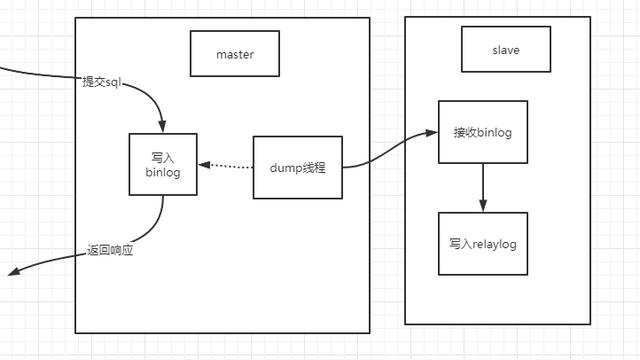
##数据库架构 在账户数据上亿,交易数据几百亿的系统,需要采用分库分表方案。本案例中,采用了MyCat+MySQL的数据库架构方案。采用mycat代理Master与Slave,可灵活进行主从切换。Slave可作为Master热备,也同时可作为读库,实现读写分离。备库除作为准实时的备份外,也可作为运维库或提供大数据平台数据抽取。
同时采用1主2从1备的双机房设计
mycat采用k8s容器化运行,使用k8s service来实现mycat的负载均衡,达到mycat的集群的高可用。若mycat容器节点异常,应用自动连接到另外的mycat节点上。
对数据库的大量操作是读操作,一般占到所有操作70%以上。所以做读写分离还是很有必要的,如果不做读写分离,那么从库也是一种很大的浪费。 mycat通过配置很容易做到读写分离,在从库进行读操作,提升资源利用率,在主库进行写操作,减低主库压力。


热数据缓存
冷数据归档
####DEVOPS流水线 本案例中,通过基于jenkins的CICD平台,将应用代码从github代码库获取,使用gradle进行构建(前端使用npm构建),通过dockerfile打成镜像后,部署到K8S容器平台。

在进行持续集成的过程中,同时加入了安全检查,合规检查以及单元测试(SpringBoot应用使用JUnit,Vue前端应用使用Jest测试框架)的步骤,以保证每一次发布的质量。 ###ConfigMap ConfigMap用于将应用的配置信息与程序的分离,这种方式不仅可以实现应用程序被的复用,而且还可以通过不同的配置实现更灵活的功能。本案例中,SpringBoot应用在K8S部署时,便将application.yml文件以ConfigMap文件的形式进行挂载。需要注意,SpringBoot会优先读取classpath下的配置文件,因此需要在打出springboot应用jar包时,先将配置文件排除,并通过容器启动命令参数来制定挂载的应用配置文件。
-spring.profiles.active=prod
-spring.config.location=/config/application.yml
复制代码###K8S容器部署 在K8S部署平台,可以为每一个服务指定初始的资源,以及节点数量配置。比如我们为SpringBoot应用初始配置,2core 4g的资源配置,节点数量则为20个。
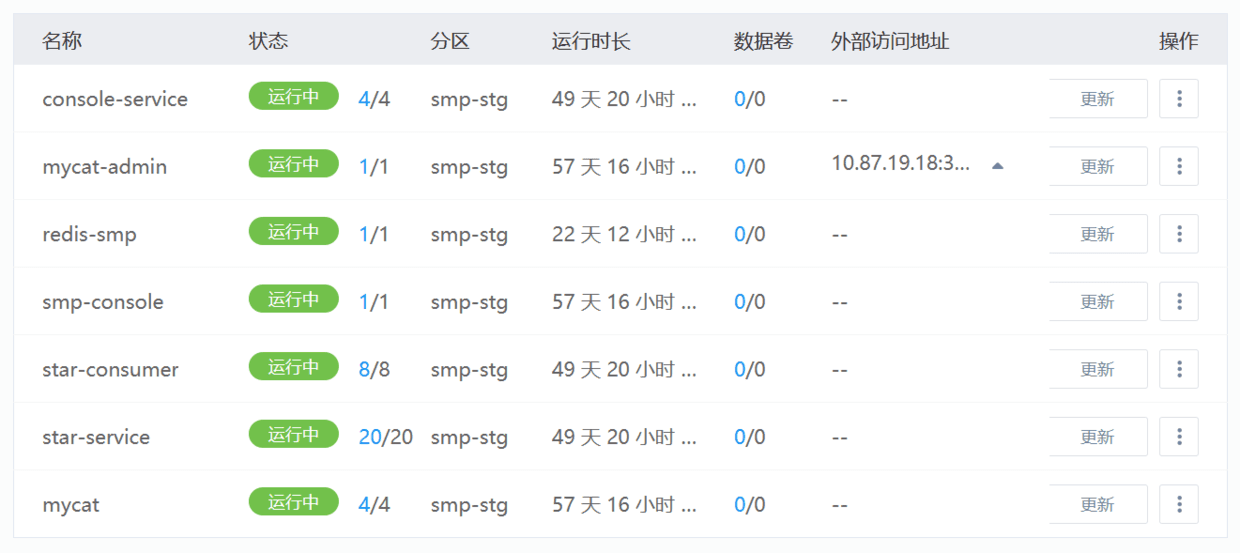
根据需要我们可以采用滚动方式对pod数量进行伸缩。而不会引起服务不可用的情况。

另外,我们也可以利用弹性伸缩,基于某些关键指标,如容器的CPU使用量作为阈值,来触发容器进行弹性伸缩。在这个案例中,通过弹性伸缩机制,在上班以及中午业务高峰时间段内,将更多pod提供给业务服务组件,而在晚上,则会将pod从业务组件收回,提供给需要跑批处理以及异步消费的服务组件。

ELK是一套解决方案而不是一款软件, 三个字母分别是三个软件产品的缩写。 E代表Elasticsearch,负责日志的存储和检索; L代表Logstash, 负责日志的收集,过滤和格式化;K代表Kibana,负责日志的展示统计和数据可视化。

Dynatrace可能是目前最优秀的应用性能管理工具(APM),它既能监控基础设施如服务器,K8S容器,又能自动发现并监控在容器内运行的动态微服务,了解它们如何执行、相互之间如何通信,还能立即检测出性能不佳的微服务。在我们的案例中,通过定制dashboard添加我们所需要关注的监控数据。

Dynatrace还能自动识别服务,并提供更精细的检测数据,为开发或运维人员定位问题,带来了极大的帮助。

今天先记录到这里,随着实践的深入,相信后面还会有更多新的补充,也欢迎大家一起分享经验。
作者:技匠
链接:https://juejin.cn/post/6925238390161932301