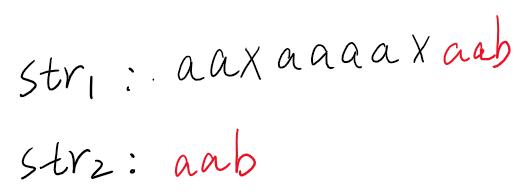KMP(D.E.Knuth,J.H.Morris,V.R.Prat)是三个发明者的名字首字母命名的。用于字符串匹配的经典算法。
这个算法很抽象,研究了些时间才慢慢弄懂里面的一些奥秘之处,并借此记录下来,以便后期回顾。
常规字符串匹配方式:
主串:ABC ABCDAB ABCDABCDABDE
模式串:ABCDABD
我们要在主串里查找匹配串是否存在,那么常规匹配方式如下:
主串和模式串都从头开始匹配,当出现不匹配的字符时,如图1所示,主串A字符和模式串的D字符不匹配,那么说明主串A开头和模式串不匹配,主串往后移从B字符开始重新和模式串进行比较(如图2)。因为主串B和模式串A不相等,所以主串往后移继续和模式串比较(如图3),重复以上操作,知道在主串中找到对应的字串或者找不到。但是这样比较的效率十分低,当出现不相等就会对模式串复位,然后从头开始比较。要想比较速度加快,不用每次模式串都是从头开始比较,下面介绍的KMP算法,就可以做到。

图1

图2

图3
KMP的思想是当主串和模式串不相等时
1.主串不用像常规匹配那样,需要从上一次的下一个位置开始重新和模式串进行匹配,保持当前位置不变和已经移动过的模式串进行匹配,如果模式串移动的字符为0并且第一个字符和主串的当前字符也不相等,那么主串需要往后移动一个字符继续和模式串匹配。
2.模式串将已经对比过的好前缀一次性往后移动多个字符。
如图4,当主串的空格和模式串的D不相等时,主串位置保持不变,模式串不用从0下标开始,而是从下标2开始重新匹配。因为ABCDAB主串和模式中进行对比后是相等的,那么,坏字符D的最长前缀和后缀集合是AB,长度为2。
模式串的起始位置依赖一张表叫部分匹配表。

图4
部分匹配表:

图5
部分匹配表是根据好前缀和好后缀共有元素的长度
A 前缀和后缀的集合为空 共有元素长度为0
AB 前缀【A】,后缀【B】 共有元素长度为0
ABC 前缀【A,AB】,后缀【BC, C】 共有元素长度为0
ABCD 前缀【A,AB,ABC】,后缀【BCD,CD,D】 共有元素长度为0
ABCDA 前缀【A,AB,ABC,ABCD】,后缀【BCDA,CDA,DA,A】 共有元素长度为1
ABCDAB 前缀【A,AB,ABC,ABCDA】,后缀【BCDAB,CDAB,DAB,AB,B】 共有元素长度为2
ABCDABD 前缀【A,AB,ABC,ABCDAB】,后缀【BCDABD,CDABD,DABD,ABD,BD,D】 共有元素长度为0
在程序中部分匹配表可以使用一个数组来保存,可以命名为next数组,next数组的下标为当前正在和主串进行比较的字符下标,其值是当前字符的好前缀和好后缀共有元素的长度。
我们约定next[0]为-1,那么上面的部分匹配转换成next数组如下:
next[0]=-1 A A字符的好前缀和好后缀共有元素长度为0
next[1]=0 AB B字符的好前缀和好后缀共有元素长度为0
next[2]=0 ABC C字符的好前缀和好后缀共有元素长度为0
next[3]=0 ABCD D字符的好前缀和好后缀共有元素长度为0
next[4]=1 ABCDA A字符的好前缀和好后缀共有元素长度为1
next[5]=2 ABCDAB B字符的好前缀和好后缀共有元素长度为2
next[6]=0 ABCDABD D字符的好前缀和好后缀共有元素长度为0
代码实现:
//s:模式串 len:模式串长度 next:next数组保存部分匹配表数据
void getNext(char *s, int len, int *next){
int k = -1; //模式串s下标j的前后缀共有元素长度
int j = 0; //模式串的下标
next[0] = -1;//第一个元素的共有元素约定为-1
while(j < len){
if(k == -1 || s[k] == s[j]){//k=-1表示是第一个字符
//如果前缀和后缀有共有元素,那么前缀和后缀都后移一个字符,然后再次比较。
k++;
j++;
next[j] = k; //将当前字符的前缀和后缀共有元素长度保存到next数组
}else{
k = next[k]; //如果不等,那么前缀字符串根据next数组往前查找和当前字符为后缀匹配的位置,
//如果一直找不到那么k值将会变成成0。就是说主串要从模式开头进行匹配。
}
}
}
有了计算next数组的算法,那么KMP的实现就很简单了
/*
*s:主串 slen:主串长度 p:模式串 plen:模式串长度 next:已经计算过的next数组 res:匹配的下标位置
*
*/
int kmp(char*s , int slen, char*p, int plen, int *next, int *res){
int s_index, p_index=0, res_index=0;
for(s_index = 0; s_index < slen; s_index++){
while(p_index > 0 && s[s_index] != p[p_index]){
//下一个匹配位为next数组的第j-1位
p_index = next[p_index-1]+1;
}
if(s[s_index] == p[p_index]){
p_index ++;//如果相等就都往后移一位
}
//如果匹配串的第一位一直和模式串第一位不相等,那么模式串id s_index一直往后移
if(p_index == plen){
res[res_index++] = s_index-p_index+1;//应为当模式串和匹配串相等时,匹配串的下标会加1,所以会多减1,后面要加上
p_index = 0;
}
}
return res_index;
}
说明: 以上仅仅代表自己的想法。