
本文是对 Monte Carlo Tree Search – beginners guide 这篇文章的文章大体翻译,以及对其代码的解释。
蒙特卡洛树搜索在2006年被Rémi Coulom第一次提出,应用于Crazy Stone的围棋游戏。
蒙特卡洛树搜索大概的思想就是给定一个游戏状态,去选择一个最佳的策略/动作。
蒙特卡洛树搜索实际上是一个应用非常广泛的博弈框架,这里我们将其应用于 有限双人序贯零和博弈 问题中。像围棋、象棋、Tic-Tac-Toe都是有限双人序贯零和博弈游戏。
我们采用 博弈树 (Game Tree)来表示一个游戏:每个结点都代表一个 状态 (state),从一个 结点 (node)移动一步,将会到达它的 子节点 (children node)。子节点的个数叫作 分支因子 (branching factor)。 根节点 (Root node)表示初始状态(initial state)。 终止节点 (terminal nodes)没有子节点了。
在 tic-tac-toe 游戏中表示如下图所示:

你不需要关系你是怎么来到这个 node ,只需要做好之后的事情就好了。
我们希望找到的就是 最佳策略 ( the most promising next move )。如果你知道对手的策略那你可以争对这个策略求解,但是大多数情况下是不知道对手的策略的,所以我们需要用 minimax 的方法,假设你的对手是非常机智的,每次他都会采取最佳策略。
假设A与B博弈,A期望最大化自己的收益,因为是零和博弈,所以B期望A的收益最小,Minimax算法可描述为如下形式:
简单地说,就是给定一个状态 期望找到一个动作 在对手最小化你的奖励的同时找到一个最大化自己的奖励。
Minimax 算法最大的弱点 就是需要扩展整棵树,对于高分支因子的游戏,像围棋、象棋这种,算法就很难处理。
对于上述问题的一种解决方法就是扩展树结构到一定的阈值深度( expand our game tree only up to certain threshold depth d )。因此我们需要一个评估函数,评估 非终止节点 。这对于我们人类来说依据当前棋势判断谁输谁赢是很容易做到的。计算机的解决方法可以参考原文中的:
另一种解决树扩展太大的方法就是 alpha-beta剪枝算法 。它会避免一些分支的展开,它最好的结果就是与minimax算法效果相同,因为它减少了搜索空间。
蒙特卡洛通过多次模拟仿真,预测出最佳策略。最核心的东西就是搜索。搜索是对整棵博弈树的组合遍历,单次的遍历是从根结点开始,到一个未完全展开的节点(a node that is not full expanded)。未完全展开的意思就是它至少有一个孩子节点未被访问,或者称作未被探索过。当遇到未被完全展开过的节点,选择它的一个未被访问的childre node做根结点,进行一次模拟(a single playout/simulation)。仿真的结果反向传播(propagated back)用于更新当前树的根结点,并更新博弈树节点的统计信息。当整棵博弈树搜索结束后,就相当于拿到了这颗博弈树的策略。
我们再理解一下以下几个关键概念:
Playout/simulation是与游戏交互的一个过程,从当前节点移动到终止节点。在simulation过程中move的选择基于rollout policy function:
Rollout Policy也被称作快速走子策略,基于一个状态 选择一个动作 。为了让这个策略能够simulation快,一般选用随机分布(uniform random)。如下图所示

在AlphaGo Zero里面DeepMind‘s直接用一个CNN残差网络输出position evaluation和moves probability。
一个节点如果被访问过了,意味着某个某个simulation是以它为起点的。如果一个节点的所有子节点都被访问过了,那这个节点就称为是完全扩展的,否则就是未完全扩展的。如下图对比所示:

在实际过程中,一开始根节点的所有子节点都未被访问,从中选一个,第一次simulation就开始了。
Simulation过程中rollout policy选择子节点是不被考虑为这个子节点被访问过了, 只有Simulation开始的节点被标记为访问过的 。
从一个近期访问过的节点(有时候也叫做叶结点(left node))做Simulation,当他Simulation完成之后,得出来的结果就需要反向传播回当前博弈树的根结点,Simulation开始的那个节点被标记为访问过了。

反向传播是从叶结点(simulation 开始的那个节点)到根结点。在这条路径上所有的节点统计信息都会被计算更新。
拿到simulation的结果主要更新两个量:所有的simulation reward 和所有节点 (包括simulation开始的那个节点)的访问次数 。
搜索开始时,没有被访问过的节点将会首先被选中,然后simulation,结果反向传播给根结点,之后根节点就可以被认为是全展开的。
为了选出我们路径上的下一个节点来开始下一次模拟,我们需要考虑 的所有子节点 , , , 和其本身节点 的信息,如下图所示:

当前的状态被标记为蓝色,上图它是全展开的,因此它被访问过了并且存储了节点的统计信息:总的仿真回报和访问次数,它的子节点也具备这些信息。这些值组成了我们最后一个部分:树的置信度上界(Upper Confidence Bound Applied to Trees,UCT)。
UCT是蒙特卡罗树搜索中的一个核心函数,用来选择下一个节点进行遍历:
蒙特卡洛树搜索的过程中选UCT最大的那个遍历。
UCT 中第一部分是 ,也被称作 exploitation component ,可以看作是子节点 的胜率估计(总收益/总次数=平均每次的收益)。
看起来这一项已经有足够说服力,因为只要选择胜率高的下一步即可,但是为什么不能只用这一个成分呢?这是因为这种贪婪方式的搜索会很快导致游戏结束,这往往会导致搜索不充分,错过最优解。因此UCT中的第二项称为exploration component。这个成分更倾向于那些未被探索的节点( 较小)。在蒙特卡洛树搜索过程中第二项的取值趋势大概如下图所示,随着迭代次数的增加其值也下降:

参数
用于平衡MCTS中的exploitation和exploration。
在AlphaGo Lee和Alpha Zero算法里面,UCT公式如下:
是来自策略网络的move先验概率,策略网络是从状态得到move分布的函数,目的是为了提升探索的效率。
当游戏视角发生变化的时候exploitation component 也会发生变化。
在 AlphaGo 算法里,有两个policy网络:
Interestingly – in Deepmind’s Monte Carlo Tree Search variant – SL Policy Network output is chosen for prior move probability estimation as it performs better in practice (authors suggest that human-based data is richer in exploratory moves). What is the purpose of the RL Policy Network then? The stronger RL Policy Network is used to generate 30 mln positions dataset for Value Network training (the one used for game state evaluation)
在Alpha Zero里面只有一个网络 ,它不仅是值网络还是策略网络。 It is trained entirely via self-play starting from random initialization. There is a number of networks trained in parallel and the best one is chosen for training data generation every checkpoint after evaluation against best current neural network.
我们应该什么时候结束MCTS过程?如果你开始玩,那么你的“思考时间”可能是有限的(“thinking time” is probably limited),计算能力也是有限的(computational capacity has its boundaries, too)。因此最保险的做法是在你资源允许的情况下尽可能全展开遍历搜索。
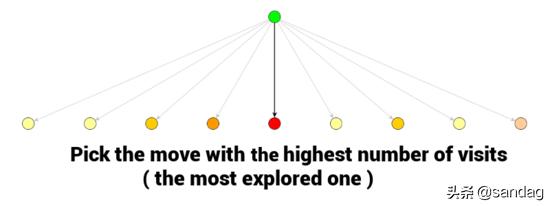
当MSCT程序结束时,最佳的移动通常是访问次数最多的那个节点。因为在多次访问的情况下,评估它的 值必须很高。
当你使用蒙特卡洛树搜索选择了一个动作,在对手眼里,你的这个选择将会变成状态的一部分。反过来对你也是一样的,当对手选择了一个状态之后,你的蒙特卡洛树搜索就可以开始工作了。利用之前的统计信息直接搜索就可以得出结果了。
def monte_carlo_tree_search(root):
while resources_left(time, computational power):
leaf = traverse(root) # leaf = unvisited node
simulation_result = rollout(leaf)
backpropagate(leaf, simulation_result)
return best_child(root)
def traverse(node):
while fully_expanded(node):
node = best_uct(node)
return pick_univisted(node.children) or node # in case no children are present / node is terminal
def rollout(node):
while non_terminal(node):
node = rollout_policy(node)
return result(node)
def rollout_policy(node):
return pick_random(node.children)
def backpropagate(node, result):
if is_root(node) return
node.stats = update_stats(node, result)
backpropagate(node.parent)
def best_child(node):
pick child with highest number of visits















