

在本文中,我们将了解随机森林算法是如何在内部工作的。为了真正理解它,了解一下决策树分类器可能会有帮助。但这并不完全是必需的。
注意:我们不涉及建模中涉及的预处理或特征工程步骤,只查看当我们使用sklearn的RandomForestClassifier包调用.fit()和.transform()方法时,算法中会发生什么。
随机森林是一种基于树的算法。它是多种不同种类的随机树的集合。模型的最终值是每棵树产生的所有预测/估计的平均值。
我们将以sklearn的RandomForestClassifier为基础
sklearn.ensemble.RandomForestClassifier
为了说明这一点,我们将使用下面的训练数据。

注:年龄、血糖水平、体重、性别、吸烟,... f98、f99都是自变量或特征。
糖尿病(Diabetic)是我们必须预测的y变量/因变量。
有了这些基本信息,让我们开始并理解我们将这个训练集传递给算法会发生什么…

一旦我们将训练数据提供给RandomForestClassifier模型,它(该算法)会随机选择一组行。这个过程称为Bootstrapping。对于我们的示例,假设它选择m个记录。

注意- 要选择的行数可由用户在超参数- max_samples中提供)
注意- 一行可能被多次选中

现在,RF随机选择一个子集的特征/列。为了简单起见,我们选择了3个随机特征。
注意,在你的超参数max_features中你可以控制这个数字,例如下面的代码
import sklearn.ensemble.RandomForestClassifier
my_rf = RandomForestClassifier(max_features=8)

一旦选择了3个随机特征,算法将对m个记录(从步骤1开始)进行决策树的拆分,并快速计算度量值。
这个度量可以是gini,也可以是熵。
criterion = 'gini' #( or 'entropy' . default= 'gini’ )
选取基尼/熵值最小的随机特征作为根节点。
记录在此节点的最佳拆分点进行拆分。

该算法执行与步骤2和步骤4相同的过程,并选择另一组3个随机特征。(3是我们指定的数字-你可以选择你喜欢的-或者让算法来选择最佳数字)

它根据条件(gini/熵),选择哪个特征将进入下一个节点/子节点,然后在这里进一步分割。

继续选择特征(列)以选择其他子节点
此过程继续(步骤2、4)选择随机特征并拆分节点,直到出现以下任一情况

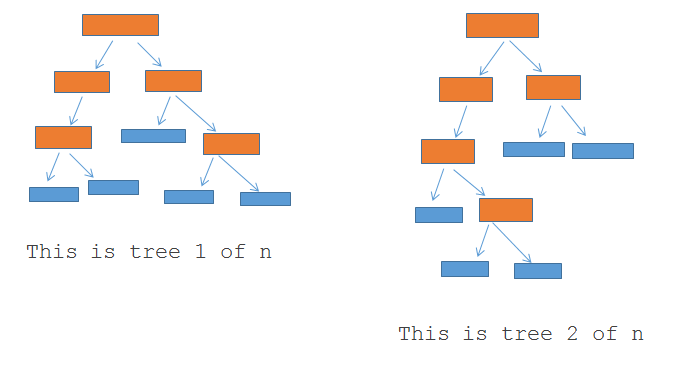
现在你有了第一个“迷你决策树”。

使用随机选择的行(记录)和列(特征)创建的第一个迷你决策树
算法返回到你的数据并执行步骤1-5以创建第二个“迷你树”

这是我们使用另一组随机选择的行和列创建的第二个迷你树
一旦达到默认值100棵树(现在有100棵迷你决策树),模型就完成了fit()过程。
注意 你可以指定要在超参数中生成的树的数量(n_estimators)
import sklearn.ensemble.RandomForestClassifier
my_rf = RandomForestClassifier(n_estimators=300)
现在你有一个由随机创建的迷你树组成的森林(因此得名Random Forest)
现在让我们预测一个看不见的数据集(测试数据集)中的值
为了推断(通常称为预测/评分)测试数据,该算法将记录传递到每个迷你树中。

记录中的值根据每个节点表示的变量遍历迷你树,最终到达一个叶节点。基于该记录结束的叶节点的值(在训练期间决定的),该迷你树被分配一个预测输出。

类似地,相同的记录经过所有的100个小决策树,并且每100个树都有一个预测输出。这个记录的最终预测值是通过对这100棵小树的简单投票来计算的。

现在我们有了对单个记录的预测。
该算法按照相同的过程迭代测试集的所有记录,并计算总体精度!

迭代获得测试集每一行的预测的过程,以达到最终的精度。
[1] sklearn’s documentation for RandomForestClassifier ( version : 3.2.4.3.1)
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html



















