
局部敏感哈希,英文locality-sensetive hashing,常简称为LSH。局部敏感哈希在部分中文文献中也会被称做位置敏感哈希。LSH是一种哈希算法,最早在1998年由Indyk在上提出。不同于我们在数据结构教材中对哈希算法的认识,哈希最开始是为了减少冲突方便快速增删改查,在这里LSH恰恰相反,它利用的正式哈希冲突加速检索,并且效果极其明显。
LSH主要运用到高维海量数据的快速近似查找。近似查找便是比较数据点之间的距离或者是相似度。因此,很明显,LSH是向量空间模型下的东西。一切数据都是以点或者说以向量的形式表现出来的。在细说LSH之前必须先提一下K最近邻查找 (kNN,k-Nearest Neighbor)与c最近邻查找 (cNN,c-Nearest Neighbor )。 kNN问题就不多说了,这个大家应该都清楚,在一个点集中寻找距离目标点最近的K个点。我们主要提一下cNN问题。首先给出最近邻查找(NN,Nearest Neighbor)的定义。

定义 1: 给定一拥有n个点的点P,在此集合中寻找距离q 点最近的一个点。
这个定义很容易被理解,需要说明的是这个距离是个广义的概念,并没有说一定是欧式距离。随着需求的不同可以是不同的距离度量手段。那么接下来给出cNN问题的定义。
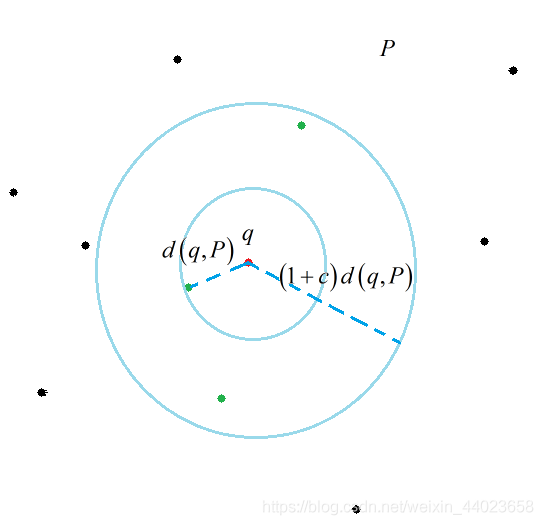
定义 2: 给定一拥有n个点的点集P,在点集中寻找点 这个 满足 其中d 是P中 距离古点最近一点到的的距离。
cNN不同于kNN,cNN和距离的联系更加紧密。LSH本身设计出来是专门针对解决cNN问题,而不是kNN问题,但是很多时候kNN与cNN有着相似的解集。因此LSH也可以运用在kNN问题上。这些问题若使用一一匹配的暴力搜索方式会消耗大量的时间,即使这个时间复杂度是线性的。
也许一次两次遍历整个数据集不会消耗很多时间,但是如果是以用户检索访问的形式表现出来可以发现查询的用户多了,每个用户都需要消耗掉一些资源,服务器往往会承受巨大负荷。那么即使是线性的复杂度也是不可以忍受的。早期为了解决这类问题涌现出了许多基于树形结构的搜索方案,如KD树,SR树。但是这些方法只适用于低维数据。自从LSH的出现,高维数据的近似查找便得到了一定的解决。
LSH不像树形结构的方法可以得到精确的结果,LSH所得到的是一个近似的结果,因为在很多领域中并不需非常高的精确度。即使是近似解,但有时候这个近似程度几乎和精准解一致。 LSH的主要思想是,高维空间的两点若距离很近,那么设计一种哈希函数对这两点进行哈希值计算,使得他们哈希值有很大的概率是一样的。同时若两点之间的距离较远,他们哈希值相同的概率会很小。给出LSH的定义如下:
定义3: 给定一族哈希函数H,H是一个从欧式空间S到哈希编码空间U的映射。如果以下两个条件都满足, 则称此 哈希函数满足性。
若则若则
定义3中B表示的是以q为中心, 或 为半径的空间。其实还有个版本的定义, 用的是距离的方式, 其实都是一样的。(至于说为什么是同时时出现,如果要严密的说这确实是个问题,但是人家大牛的论文下的定义, 不要在意这些细节 我绘制了一幅图来说明一下这个定义。

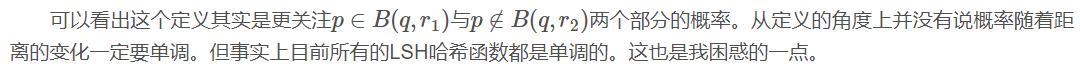
从理论讲解的逻辑顺序上来说,现在还没到非要讲具体哈希函数的时候,但是为了方便理解,必须要举一个实例来讲解会好一些。那么就以曼哈顿距离下(其实用的是汉明距离的特性)的LSH哈希函数族作为一个参考的例子讲解。 曼哈顿距离又称L1L1范数距离。其具体定义如下:
定义 4: 在n维欧式空间 中任意两点 他们之间的买哈顿距离为:
其实曼哈顿距离我们应该并不陌生。他与欧式距离(L2范数距离)的差别就像直角三角形两边之和与斜边的差别。其实在这篇论文发表的时候欧式距离的哈希函数还没有被探究出来,原本LSH的设计其实是想解决欧式距离度量下的近似搜索。所以当时这个事情搞得就很尴尬,然后我们的大牛Indyk等人就强行解释,大致意思是:不要在意这些细节,曼哈顿和欧式距离差不多。他在文章中提出了两个关键的问题。 1.使用L1范数距离进行度量。 2.所有坐标全部被正整数化。 对于第一条他解释说L1范数距离与L2范数距离在进行近似查找时得到的结果非常相似。对于第二条,整数化是为了方便进行01编码。
对数据集 所有的点, 令C作为所有点中坐标的最大值m, 也就是上限。下限是0,这个很明显。然后就可以把 嵌入汉明空间 其中 此处 是数据点在原来欧式空间的维度。对于 个点 如果用 '空间的坐标表示就是:
Unary_ 是一串长度为 二进制的汉明码,其意思是前 位为1 后 位为0。举个例子, C若为5 x 为3,则 Unary=11100 。 是多个 Unary 拼接而成。此时可以发现对于两点 他们之间的曼哈顿距离和通过变换坐标后的汉明距 离是一样的。到此处, 我们可以针对汉明距离来定义一族哈希函数。
##四. 汉明距离下的LSH哈希函数


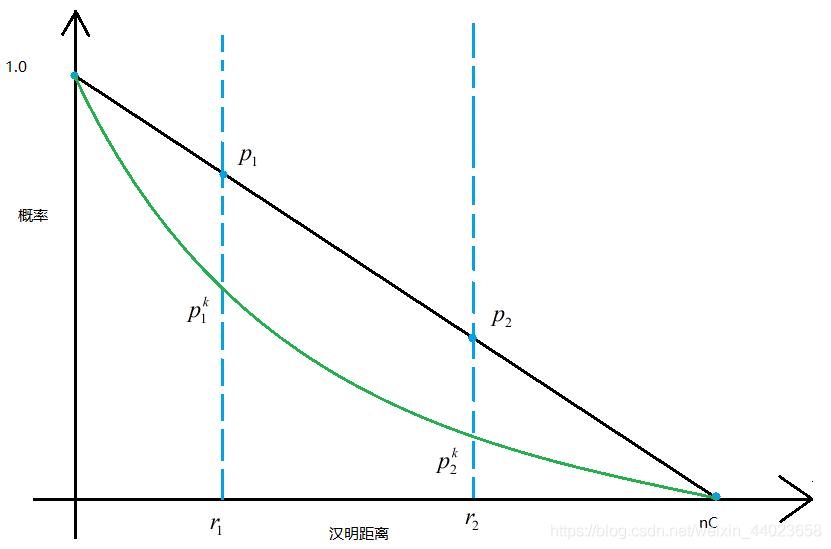


当基本哈希函数确定, 理论上讲只要 通过改变 l都可以将 时的哈希概率差距拉的很大。代价是要 足够大的 这也是LSH一个致命的弊病。 说了这么多我们来举一个实例帮助理解。
例1:数据点集合P由以下6个点构成:
可知坐标出现的最大值是4,则 维度为2, 则 显然n 。我们进行8位汉明码编码。
若我我们现在采用k = 2, l = 3生成哈希函数。 由 构成。每个 由它对应的 构成
假设有如下结果。 分别抽取第2,4位。 分别抽取第1,6位。 分别抽取第3,8位。 哈希表的分布如下图所示。

可以计算出 。则分别取出表1,2,3的11,11,11号哈希桶的数据点与q比较。依次是C,D,E,F。算出距离q最近的点为F。当然这个例子可能效果不是很明显。原始搜索空间为6个点, 现在搜索空间为4个点。对于刚接触LSH的人会有个疑问。如果不同哈希表的数据点重复了 怎么办, 会不会增加搜索空间的大小。
首先要说的是这个概率很小, 为什么呢。试想假设两个不同哈希表的哈希桶对 查询有相同点, 这意味着在两张哈希表中这个点与q都有相同哈希值。如果使用单个哈希函数q和此点被哈希到一起的概率 为 则刚才那个事件发生的概率为 这个概率是很小的。当然也有很多办法可以解决这个问题。这不是一个大问 题。
我在实际运用时k大概总是取10-20之间的数, l大致20-100左右。每次对 q进行候选点匹配时, 候选的样本点数量已 经是P的十分之一到百分之一了。就好比P有10000个数据点, 使用暴力匹配要遍历整个数据集, 使用LSH可能只要匹配1 00到1000个点就可以了。而且往往我都能找到最近点。即使找不到最近的,总体成功率也在90%-98%左右。
之前讲解的是一个大致思想,有很多细节没有说明白。 比如哈希表和哈希桶的具体表现形式。就好比我给出的是个逻辑结构, 并没有说清楚它的物理结构。现在说说通常是怎么 具体实施的。其实我想说的是物理结构这个东西每个人都可以设计一个自己习惯的,不一定非要按某个标准来。車要的是 思想。 当k的数值很大时, 对于拥有大量数据点的 产生不同的哈希值会很多。这种二进制的编码的哈希值最多可以有2 种。这样一来可能会产生大量哈希桶, 于是平我们可以采用一种方法, 叫二级哈希。首先我们可以将数据点p哈希到编码 为 的哈希桶。
然后我们可以用一个普通的哈希将哈希桶 哈希到一张大小为M 的哈希表中。注意这里的 是针对 哈希桶的数目而不是针对点的数量。至于第二个哈希具体这么做, 我想学过数据结构的同学都应该知道。对于哈希桶而 言,我们限制它的大小为 也就是说它最多可以放下 个点。当它的点数量达到B时, 原本我们可以重新开辟一段空间 放多余的点, 但是我不放入, 舍弃它。
假设点集P有n个点, M与B有如下关系:
是内存利用率。对查询q的近邻点时,我们要搜索所有哈希表至少 个点。因此磁盘的访问是有上界的,上界便是l。 我们现在来分析下l,k的取值问题。首先我们列出两个事件。 假如我们的哈希函数是满足 性的。
P1:如果存在一个点 至少存在一个 满足
P2: q通过 哈希到的块中仅包含 以外的点的块数小于cl。
定理 则P1,P2可以保证至少 的概率。其中
总结:
以上便是LSH的基本理论, 我总结一下。对于LSH算的主要流程分为两个部分,一个是建立哈希结构,另一个便是检 索。在知道具体度量方式的情况下,利用该度量下的LSH哈希函数,建立哈希结构。首先选取合适的k,l参数,然后建立 l张哈希表,每张哈希表用k个独立抽取的基本哈希函数联合判断,建立哈希表的内部结构。哈希值相同的点放在一起,哈 希值不同的放在不同的地方。至于查询,当q成为我们的查询点, 首先计算q在每张哈希表的哈希值,取出对应哈希值的哈 希桶内所有点,与q做距离计算。找到满足我们条件的点作为查询结果。
说到Hash,大家都很熟悉,是一种典型的Key-Value结构,最常见的算法莫过于MD5。其设计思想是使Key集合中的任意关键字能够尽可能均匀的变换到Value空间中,不同的Key对应不同的Value,即使Key值只有轻微变化,Value值也会发生很大地变化。这样特性可以作为文件的唯一标识,在做下载校验时我们就使用了这个特性。但是有没有这样一种Hash呢?他能够使相似Key值计算出的Value值相同或在某种度量下相近呢?甚至得到的Value值能够保留原始文件的信息,这样相同或相近的文件能够以Hash的方式被快速检索出来,或用作快速的相似性比对。位置敏感哈希(Local Sensitive Hashing, LSH)正好满足了这种需求,在大规模数据处理中应用非常广泛,例如已下场景:
LSH(Location Sensitive Hash),即位置敏感哈希函数。与一般哈希函数不同的是位置敏感性,也就是散列前的相似点经过哈希之后,也能够在一定程度上相似,并且具有一定的概率保证。 LSH的形式化定义可参见前面部分。
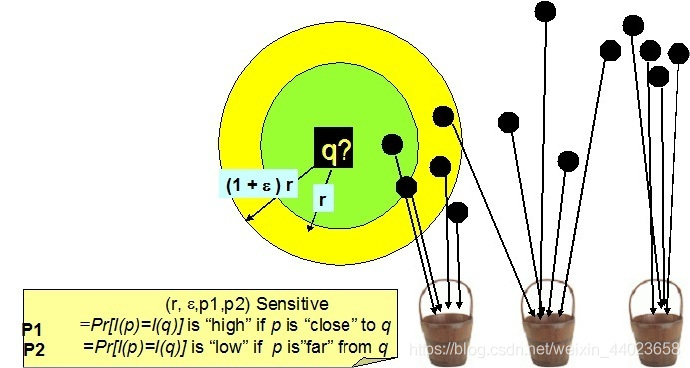
如下图,空间上的点经位置敏感哈希函数散列之后,对于q,其rNN有可能散列到同一个桶(如第一个桶),即散列到第一个桶的概率较大,会大于某一个概率阈值p1;而其(1+emxilong)rNN之外的对象则不太可能散列到第一个桶,即散列到第一个桶的概率很小,会小于某个阈值p2.
LSH的作用:
◆高维下近似查询 相似性检索在各种领域特别是在视频、音频、图像、文本等含有丰富特征信息领域中的应用变得越来越重要。丰富的特征信息一般用高维向量表示,由此相似性检索一般通过K近邻或近似近邻查询来实现。一个理想的相似性检索一般需要满足以下四个条件[4]:
此外, 检索模式应能快速地构造索引数据结构, 并且可以完成插入、删除等操作。
传统主要方法是基于空间划分的算法——tree类似算法,如R-tree,Kd-tree,SR-tree。这种算法返回的结果是精确的,但是这种算法在高维数据集上的时间效率并不高。实验[5]指出维度高于10之后,基于空间划分的算法时间复杂度反而不如线性查找。LSH方法能够在保证一定程度上的准确性的前提下,时间和空间复杂度得到降低,并且能够很好地支持高维数据的检索。
现有的很多检索算法并不能同时满足以上的所有性质。以前主要采用基于空间划分的算法–tree 算法, 例如: R-tree[6], Kd-tree[7],SR-tree。这些算法返回的结果都是精确的, 然而它们在高维数据集上时间效率并不高。文献[5]的试验指出在维度高于10之后, 基于空间划分的算法的时间复杂度反而不如线性查找。
1998年, P.Indy和R.Motwani提出了LSH算法的理论基础。1999 年Gionis A,P.Indy和R.Motwani使用哈希的办法解决高维数据的快速检索问题, 这也是Basic LSH算法的雏形。2004 年, P.Indy 提出了LSH 算法在欧几里德空间(2-范数)下的具体解决办法。同年, 在自然语言处理领域中, Deepak Ravichandran使用二进制向量和快速检索算法改进了Basic LSH 算法, 并将其应用到大规模的名词聚类中, 但改进后的算法时间效率并不理想。
2005 年, Mayank Bawa, Tyson Condie 和Prasanna Ganesan 提出了LSH Forest算法, 该算法使用树形结构代替哈希表, 具有自我校正参数的能力。2006 年, R. Panigrahy用产生近邻查询点的方法提高LSH 空间效率, 但却降低了算法的空间效率。2007年,William Josephson 和Zhe Wang使用多重探测的方法改进了欧几里德空间(2-范数)下的LSH 算法, 同时提高了算法的时间效率和空间效率。
◆分类和聚类 根据LSH的特性,即可将相近(相似)的对象散列到同一个桶之中,则可以对图像、音视频、文本等丰富的高维数据进行分类或聚类。
◆数据压缩。如广泛地应用于信号处理及数据压缩等领域的Vector Quantization量子化技术。 总而言之,哪儿需要近似kNN查询,哪儿都能用上LSH.
1, 基于Stable Distribution投影方法 2, 基于随机超平面投影的方法; 3, SimHash; 4, Kernel LSH
1, 基于Stable Distribution投影方法
2008年IEEE Signal Process上有一篇文章Locality-Sensitive Hashing for Finding Nearest Neighbors是一篇较为容易理解的基于Stable Dsitrubution的投影方法的Tutorial, 有兴趣的可以看一下. 其思想在于高维空间中相近的物体,投影(降维)后也相近。基于Stable Distribution的投影LSH,就是产生满足Stable Distribution的分布进行投影,最后将量化后的投影值作为value输出. 更详细的介绍在Alexandr Andoni维护的LSH主页中,理论看起来比较复杂,不过这就是LSH方法的鼻祖啦,缺点显而易见:你需要同时选择两个参数,并且量化后的哈希值是一个整数而不是bit形式的0和1,你还需要再变换一次。如果要应用到实际中,简直让你抓狂。
2, 基于随机超平面投影的方法
大神Charikar改进了上种方法的缺点,提出了一种随机超平面投影LSH. 这种方法的最大优点在于:
1),不需要参数设定
2),是两个向量间的cosine距离,非常适合于文本度量
3),计算后的value值是比特形式的1和0,免去了前面算法的再次变化
3, SimHash
前面介绍的LSH算法,都需要首先将样本特征映射为特征向量的形式,使得我们需要额外存储一个映射字典,难免麻烦,大神Charikar又提出了大名鼎鼎的SimHash算法,在满足随机超平面投影LSH特性的同时避免了额外的映射开销,非常适合于token形式的特征。 首先来看SimHash的计算过程: a,将一个f维的向量V初始化为0;f位的二进制数S初始化为0; b,对每一个特征:用传统的hash算法(究竟是哪种算法并不重要,只要均匀就可以)对该特征产生一个f位的签名b。对i=1到f: 如果b的第i位为1,则V的第i个元素加上该特征的权重; 否则,V的第i个元素减去该特征的权重。 c,如果V的第i个元素大于0,则S的第i位为1,否则为0; d,输出S作为签名。
大家引用SimHash的文章通常都标为2002年这篇Similarity Estimation Techniques from Rounding Algorithms, 而这篇文章里实际是讨论了两种metric的hash. 作者猜测, SimHash应该是随机超平面投影LSH,而不是后来的token形式的SimHash. 其实只是概念的归属问题, 已经无关紧要了
我想很多人引用上篇文章也有部分原因是因为07年google研究院的Gurmeet Singh Manku在WWW上的这篇paper: Detecting Near-Duplicates for Web Crawling, 文中给出了simhash在网络爬虫去重工作的应用,并利用编码的重排列方式解决快速Hamming距离搜索问题.
4, Kernel LSH
前面讲了三种LSH算法,基本可以解决一般情况下的问题,不过对于某些特定情况还是不行:比如输入的key值不是均匀分布在整个空间中,可能只是集中在某个小区域内,需要在这个区域内放大距离尺度。又比如我们采用直方图作为特征,往往会dense一些,向量只分布在大于0的区域中,不适合采用cosine距离,而stable Distribution投影方法参数太过敏感,实际设计起来较为困难和易错,不免让我们联想,是否有RBF kernel这样的东西能够方便的缩放距离尺度呢?或是我们想得到别的相似度表示方式。这里就需要更加fancy的kernel LSH了。

















