一、集合概述
当我们在使用JAVA进行编程开发时,经常会遇到一些需要集中存放的多个数据,这时我们可以选择“数组”或者“集合”,关于数组的知识可以参考上一篇文章,今天我们主要讲集合的使用。
集合和数组既然都是容器,它们有什么区别呢?
1、数组长度固定,集合长度可变。
数组是静态的,一个数组实例具有固定的大小,一旦创建了就无法改变容量了,而且生命周期也是不能改变的,还有数组也会做边界检查,如果发现有越界现象,会报RuntimeException异常错误,当然检查边界会以效率为代价。而集合的长度是可变的,可以动态扩展容量,可以根据需要动态改变大小。
2、数组中只能是同一类型的元素且可以存储基本数据类型和对象。集合不能存放基本数据类型,只能存对象,类型可以不一致。
3、集合以类的形式存在,具有封装、继承、多态等类的特性,通过简单的方法和属性即可实现各种复杂操作,大大提高了软件的开发效率
下面有一张集合家族图:

由上面的图片可以看出:Java的集合类主要由两个接口派生而出:Collection和Map,Collection和Map是Java集合框架的根接口。


下面我们一步一步来介绍集合家族的成员。
二、Collection接口
Collection 接口是Set,List,Queue接口的父接口,该接口定义的方法可以也可用于操作子接口集合,具体方法见下图

Collection的使用:
1、增加和移除元素
import java.util.ArrayList;
import java.util.Collection;
/** * Collection的简单使用 */
public class Test {
public static void main(String[] args) {
Collection collection=new ArrayList();
//添加元素
collection.add("str1");
//虽然集合里不能放基本类型的数剧,但是jdk支持自动装箱
collection.add(4);
System.out.println("collection的长度:"+collection.size());
//删除指定元素
collection.remove(4);
System.out.println("collection的长度:"+collection.size());
//判断集合是否包含指定字符串
System.out.println("判断集合是否包含字符串:"+collection.contains("str1"));
collection.add("测试collection");
System.out.println("collection:"+collection); }
}
运行结果:collection的长度:2collection的长度:1判断集合是否包含字符串:falsecollection:[str1, 测试collection]add()方法向Collection中增加元素,如果Collection结构改变了,作为add()方法的结果,将返回true。
如果一个Set的实例中已经存在了这个元素,那么不会重复增加,这个Set实例的结构也不会发生变化。
如果在一个List上调用这个方法,而这个List已经存在了这个元素,那么这个List将有两个这个元素。
remove()方法移除一个元素。如果Collection中存在这个元素并且被移除了,这个方法将返回true。如果元素不存在,将返回false。
2、检测一个Collection是否包含一个确定的元素
Collection接口提供contains()和containsAll()两个方法来检查一个Collection是否包含一个或多个元素。
3、迭代一个Collection
Collection collection = new HashSet();
//... add elements to the collection
Iterator iterator = collection.iterator();
while(iterator.hasNext()){
Object object = iterator.next();
//do something to object;
}或者使用for循环
Collection collection = new HashSet();//... add elements to the collection
for(Object object : collection) {
//do something to object;
}二、Iterator接口(迭代器)
Iterator主要遍历Collection集合中的元素,用于遍历单列集合,也有称为迭代器。因为Collection中有iterator()方法,所以每一个子类集合对象都具备迭代器。迭代是快速取出集合中元素的一种方式。
子类集合中任意一个集合创建的对象可以使用iterator()方法获取一个Iterator对象,这个对象就是该集合的迭代器。
常用方法:
boolean hasNext():若被迭代的集合元素还没有被遍历,返回true.
Object next():返回集合的下一个元素.
void remove():删除集合上一次next()方法返回的元素。(若集合中有多个相同的元素,都可以删掉)
简单使用:
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class text {
public static void main(String[] args) {
Collection<String> coll=new ArrayList<>();
coll.add("rr");
coll.add("c");
coll.add("gf");
coll.add("bb");
//使用迭代器对集合进行遍历
Iterator<String> it=coll.iterator();
while (it.hasNext()){
String e=it.next();
System.out.println(e);
}
}
}三、List接口(有序可重复)
Collection子接口
List最大特点:List是有序的集合,集合中每个元素都有对应的顺序序列。用的贼多。
List接口中常用子类:
ArrayList:底层的数据结构是数组,线程不安全,查询速度快,默认大小10,自动扩充,每次扩充扩充前的一半。
LinkedList:底层的数据结构是链表,增删速度快。取出List集合中元素的方式:
Vector: 底层的数据结构就是数组,与ArrayList相同,不同点:线程安全,默认大小10,每次扩充1倍,Vector无论查询和增删都巨慢。
(1)LinkedList<E>泛型类(链表)
概念:链表是由若干个被称为结点的对象组成的一种数据结构。
单链表:每个结点含有一个数据和下一个结点的引用。
双链表:每个结点含有一个数据和上一个结点和下一个结点的引用。
使用LinkedList类创建链表对象:(E必须是具体类型)
例: LinkedList<String>myList = new LinkedList<String>();
或:List<Striing> list = new LinkedList<String>();
常用方法:

常用方法的简单使用:
1、add()方法:添加元素
public static void main(String[] args) {
// 创建集合对象
List<String> arrayList = new ArrayList<String>();
// 往集合的指定位置上添加给定的元素
arrayList.add(0, "a");
arrayList.add(1, "b");
arrayList.add(2, "c");
// 或者在最后添加元素
arrayList.add("d");
// 遍历集合,查看结果
// 获取迭代器对象
Iterator<String> ite = arrayList.iterator();
// 输出
while (ite.hasNext()) {
System.out.println(ite.next());
} }
输出结果:a
b
c
d2、addAll()方法:连接多个集合
// 创建集合对象
List<String> arrayList = new ArrayList<String>();
// 往集合的指定位置上添加给定的元素
arrayList.add(0, "a");
arrayList.add(1, "b");
arrayList.add(2, "c");
List<String> list1 = new ArrayList<String>();
// 往集合的指定位置上添加给定的元素
list1.add(0, "e");
list1.add(1, "r");
list1.add(2, "e");
arrayList.addAll(list1);
//输出后arrayList为{"a","b","c","e","r","e"}3、get()方法:获取元素
// 创建集合对象
List<String> arrayList = new ArrayList<String>();
// 往集合的指定位置上添加给定的元素
arrayList.add(0, "a");
arrayList.add(1, "b");
arrayList.add(2, "c");
// 或者在最后添加元素
arrayList.add("d");
System.out.println(arrayList.get(0));//输出a
System.out.println(arrayList.get(1));//输出b
System.out.println(arrayList.get(2));//输出c4、remove()方法:移除元素
// 创建集合对象
List<String> arrayList = new ArrayList<String>();
// 往集合的指定位置上添加给定的元素
arrayList.add(0, "a");
arrayList.add(1, "b");
arrayList.add(2, "c");
// 或者在最后添加元素
arrayList.add("d");
//删除第一个元素
arrayList.remove(0);
System.out.println(arrayList.get(0));//输出b
System.out.println(arrayList.get(1));//输出c
System.out.println(arrayList.get(2));//输出d注意:移除一个元素以后,在被移除元素的后面的每个元素索引减1
5、set()方法:替换元素
// 创建集合对象
List<String> arrayList = new ArrayList<String>();
// 往集合的指定位置上添加给定的元素
arrayList.add(0, "a");
arrayList.add(1, "b");
arrayList.add(2, "c");
// 或者在最后添加元素
arrayList.add("d");
//第一个元素设置为acd
arrayList.set(0, "acd");
System.out.println(arrayList.get(0));//输出acd
System.out.println(arrayList.get(1));//输出b
System.out.println(arrayList.get(2));//输出c// 创建集合对象
List<String> arrayList = new ArrayList<String>();
// 往集合的指定位置上添加给定的元素
arrayList.add(0, "a");
arrayList.add(1, "b");
arrayList.add(2, "c");
arrayList.add("d");
// 第一种遍历方式
for (int i = 0; i < arrayList.size(); i++) {
System.out.println(arrayList.get(i));
}
// 第二种遍历方式
for (String arr : arrayList) {
System.out.println(arr);
}
// 第三种遍历
Iterator<String> iter = arrayList.iterator();
while (iter.hasNext()) {
String s = (String) iter.next();
System.out.println(s);
}四、 Set接口(无序,元素不可重复)
Collection的接口,Set无法记住添加的顺序,不允许包含重复的元素。
常用子类:
HashSet:散列存放无序,每次重新散列,哈希表
TreeSet:排序,红黑树,
LinkedHashSet:有序存放,带链表的哈希表
(1)HashSet类(哈希表)
特性:
负载因子越大,查询速度越慢,负载因子越小,空间浪费越大。
HashSet集合保证元素唯一性:通过元素的hashCode方法,和equals方法完成的。
(1)HashSet元素的添加
当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,判断已经存储在集合中的对象的hashCode值是否与添加的对象的hashCode值一致:若不一致:直接添加进去;若一致,再进行equals方法比较,equals方法如果返回true,表明对象已经添加进去了,就不会再添加新的对象了,否则添加进去;
如果我们重写了equals方法,也要重写hashCode方法,反之亦然;。
HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode方法返回值也相等。如果需要某个类的对象保存到HashSet集合中,覆写该类的equals()和hashCode()方法,应该尽量保证两个对象通过equals比较返回true时,他们的hashCode返回也相等。往HashSet集合里面存入数据,要先后调用两个方法:hashCode方法和equals方法!!!
(2)TreeSet<E>泛型类(树集)
TreeSet<E>创建的对象称为树集。用于对Set集合进行元素的指定顺序排序,排序需要依据元素自身具备的比较性
储存方式:树集采用树结构储存数据,树结点中的数据会按存放数据的,“大小”顺序一层一层的依次排列,同层中从左往右按小到大的顺序递增排列,下一层的都比上一层的小。
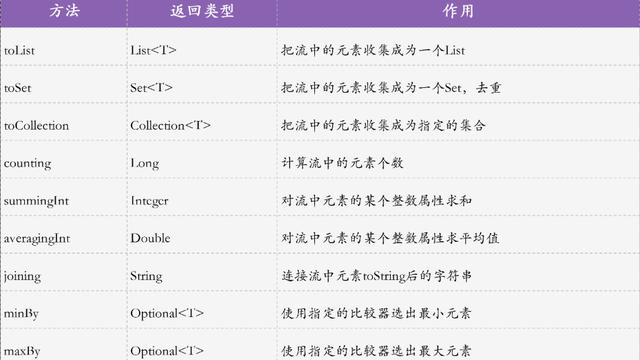
(3) Collections类操作集合
排序方式:自然排序。Collections类会调用元素的sort()方法来比较元素之间的大小关系,如果想实现两个对象之间比较大小,此时需要排序元素的类必须实现Compareble接口,并覆写其int compareTo(Object o)方法。
重点:
TreeSet集合排序有两种方式:Comparable和Comparator区别:
1:让元素自身具备比较性,需要元素对象实现Comparable接口,覆盖compareTo方法。
2:让集合自身具备比较性,需要定义一个实现了Comparator接口的比较器,并覆盖compare方法,并将该类对象作为实际参数传递给TreeSet集合的构造方法。
第二种方式较为灵活,该方法用于比较对象,a和b是实现了Comparable接口类创建的两个对象,那么:
当a.compareTo(b)>0称a大于b,
当a.compareTo(b)<0,称a小于b,
当a.compareTo(b)=0;称a等于b;
对于TreeSet集合而言,判断两个对象相等的标准是:compareTo()方法比较返回 0;
Set几种遍历方式:
public static void main(String[] args) {
Set<String> s = new HashSet<String>();
s.add("fff");
s.add("jkl");
s.add("eric");
s.add("loc");
s.add("hy");
s.add("tes");
System.out.println("第一种遍历方式");
Frist(s);
System.out.println("第二种遍历方式1");
Second1(s);
System.out.println("第一种遍历方式2");
Second2(s);
System.out.println("第一种遍历方式3");
Second3(s);
}
private static void Second3(Set<String> s) {
// 第三种情况:自己创建的数组大于集合元素的个数,这样会把前几个位置填充,剩下的返回null。
String[] ss = new String[10];
s.toArray(ss);
for (int i = 0; i < ss.length; i++) {
System.out.print(ss[i] + " ");
}
}
private static void Second2(Set<String> s) {
// 第二种情况:自己创建的数组大小正好等于集合的元素个数,这样就不用创建新的数组,返回的和创建的是同一个数组。
String[] ss = new String[6];
s.toArray(ss);
for (int i = 0; i < ss.length; i++) {
System.out.print(ss[i] + " ");
}
}
private static void Second1(Set<String> s) {
// 第二种遍历方式,含泛型的数组
// 第一种情况,自己创建的数组大小<小于集合的元素个数,这种情况会在集合内部产生一个新的数组,将之返回
String[] ss = new String[2];
String[] i1 = s.toArray(ss);
for (int i = 0; i < ss.length; i++) {
System.out.print(ss[i] + " ");
}
System.out.println("n" + Arrays.toString(i1));
}
private static void Frist(Set<String> s) {
// 第一种遍历方式:
Object[] o = s.toArray();
for (int i = 0; i < o.length; i++) {
System.out.print(o[i] + " ");
}
System.out.println();
}
五、Map集合(键值对)
Map接口存储一组成对的键(key)-值(value)对象,key要求不允许重复,可无序,value允许重复,也可无序。HahMap是其最常用的实现类。用的贼多!
注意:
1). 数据添加到HashMap集合后,所有数据类型将转换成Object类型,所有从其中获取数据时需要进行强制类型转换
2).HashMap不保证映射的顺序,特别是不保证顺序恒久不变。
常用方法:

常用方法总结
1、put();添加元素
Map<String, Object> map = new HashMap<String, Object>();
map.put("name", "小华");
map.put("sex", "女");
map.put("age", "30");
map.put("phone", "13322323322");
System.out.println(map);//输出{phone=13322323322, sex=女, name=小华, age=30}2、get();获取元素
Map<String, Object> map = new HashMap<String, Object>();
map.put("name", "小华");
map.put("sex", "女");
map.put("age", "30");
map.put("phone", "13322323322");
System.out.println(map.get("name"));//输出:小华3、remove();删除元素
Map<String, Object> map = new HashMap<String, Object>();
map.put("name", "小华");
map.put("sex", "女");
map.put("age", "30");
map.put("phone", "13322323322");
map.remove("age");//移除age元素
System.out.println(map);//输出:{phone=13322323322, sex=女, name=小华}Map的几种遍历方式
Map<String, Object> map = new HashMap<String, Object>();
map.put("name", "小华");
map.put("sex", "女");
map.put("age", "30");
map.put("phone", "13322323322");
//第一种遍历方式:在for循环中使用entries实现Map的遍历
for(Map.Entry<String, Object> entry : map.entrySet()){
String mapKey = entry.getKey();
Object mapValue = entry.getValue();
System.out.println(mapKey+":"+mapValue);
}
//第二种遍历方式:在for循环中遍历key或者values,
//一般适用于只需要map中的key或者value时使用,在性能上比使用entrySet较好
//key
for(String key : map.keySet()){
System.out.println(key);
}
//value
for(Object value : map.values()){
System.out.println(value);
}
//第三种遍历方式:通过Iterator遍历
Iterator<Entry<String, Object>> entries = map.entrySet().iterator();
while(entries.hasNext()){
Entry<String, Object> entry = entries.next();
String key = entry.getKey();
Object value = entry.getValue();
System.out.println(key+":"+value);
}
//第四种遍历方式:通过键找值遍历,这种方式的效率比较低,因为本身从键取值是耗时的操作
for(String key : map.keySet()){
Object value = map.get(key);
System.out.println(key+":"+value);
}文末总结:
在实际开发中,我们常用的集合主要是List和Map两种,这两种几乎可以说每天都在使用,所以说对List和Map的掌握非常重要。
另外我还准备了Java集合的视频教程供各位小伙伴们学习:



想要学习了解关于集合的更多知识,可以点赞转发加关注,然后私信回复【Java集合1034】即可免费得到获取方式啦,免费,免费,免费,重要的事情说三遍。