
作者:Aniruddha Bhandari
翻译:王琦
校对:和中华
本文约3700字,建议阅读10分钟。
本文介绍了Python中的生成器和迭代器。在处理大量数据时,计算机内存可能不足,我们可以通过生成器和迭代器来解决该问题。
Python 是一种美丽的编程语言。我喜欢它提供的灵活性和难以置信的功能。我喜欢深入研究Python的各种细微差别,并了解它如何应对不同的情况。
在使用Python的过程中,我了解到了一些功能,这些功能的使用与其简化的复杂度不相称。我喜欢称它们为Python中“隐藏的宝石”。很多人对此并不了解,但对于分析和数据科学专家来说,它们非常有用。
Python迭代器和生成器正好属于这一类。它们的潜力是巨大的!

如果你曾经在处理大量数据时遇到麻烦(谁没有呢?!),并且计算机内存不足,那么你会喜欢Python中的迭代器和生成器的概念。
与其将所有数据一次性都放入内存中,不如将它按块处理,只处理当时所需的数据,对吗?这将大大减少我们计算机内存的负载。这就是迭代器和生成器的作用!
因此,让我们仔细读读本文,探索Python迭代器和生成器的世界吧。
我假设你熟悉Python的基础知识。如果没有,我建议你先从下面的热门课程学起:
Python数据科学:
https://courses.analyticsvidhya.com/courses/introduction-to-data-science?utm_source=blog&utm_medium=python-iterators-and-generators
这是我们要介绍的内容:
“可迭代对象是能够一次返回其一个成员的对象”。
通常使用for循环完成此操作。像列表、元组、集合、字典、字符串等等之类的对象被称为可迭代对象。简而言之,任何你可以循环的对象都是可迭代对象。
我们可以使用for循环逐个地返回可迭代的元素。在这里,我们使用for循环遍历列表的元素:
# iterables sample = ['data science', 'business analytics', 'machine learning'] for i in sample: print(i)
既然我们知道了什么是可迭代对象,那么实际上我们是如何遍历这些值的?以及我们的循环如何知道何时停止?进入到迭代器部分!
迭代器是代表数据流的对象,即可迭代。它们在Python中实现了迭代器协议。这是什么?
好吧,迭代器协议允许我们在一个可迭代对象中使用两种方法来循环遍历项:__iter __()和__next __()。所有的可迭代对象和迭代器都有__iter __()方法,该方法返回一个迭代器。
迭代器跟踪可迭代对象的当前状态。
但可迭代对象和迭代器不同之处在于__next __()方法只能由迭代器访问。这使得无论何时只要我们要求迭代器返回下一个值,迭代器就会返回下一个值。
让我们创建一个简单的可迭代对象、本例中为一个列表以及使用__iter __()方法来构造一个迭代器来了解其工作原理:
sample = ['data science', 'business analytics', 'machine learning'] # generating an iterator it = sample.__iter__() print(it) # iterables do not have __next__() method sample.__next__() 
是的,正如我所说,可迭代对象有用于创建迭代器的__iter __()方法,但它们没有仅迭代器才有的__next __()方法。因此,让我们再试一次,然后尝试从列表中检索值:
sample = ['data science', 'business analytics', 'machine learning'] # generating an iterator it = sample.__iter__() print(it.__next__()) print(it.__next__()) print(it.__next__()) 
完美!但等一下,我不是说迭代器也具有__iter __()方法吗?那是因为迭代器也是可迭代的,但反过来不成立。它们是自己的迭代器。让我通过遍历迭代器向你展示这个概念:
sample = ['data science', 'business analytics', 'machine learning'] it = sample.__iter__() itit = it.__iter__() print(type(itit)) print(itit.__next__()) print(itit.__next__()) print(itit.__next__()) 
酷!但我们可以使用iter()和next()来代替__iter__()和__next__()方法,它们提供了一种更简洁的方法:
sample = ['statistics', 'linear algebra', 'probability'] # iterator it = iter(sample) # next values print(next(it)) print(next(it)) print(next(it))
但如果我们超过了调用next()方法的限制次数,该怎么办?这会发生什么呢?
print(next(it)) 
是的,我们得到了一个错误!如果我们在到达迭代器的末尾之后尝试访问下一个值,则会引起StopIteration异常,该异常的意思是“你不能更进一步了!”。
我们可以使用异常处理来处理此错误。实际上,我们可以自己构建一个循环来遍历可迭代的项:
sample = ['statistics', 'linear algebra', 'probability'] it = iter(sample) while True: # this will execute till an error is raised try: val = next(it) # when we reach end of the list, error is raised and we break out of the loop except StopIteration: break print(val) 
如果你退后一步,你会意识到,这正是for循环在底层运行的方式。我们在此处手动循环中所做的操作,for循环会自动执行相同的操作。这就是为什么for循环比遍历可迭代对象更可取,因为它们会自动处理异常。
每当我们迭代一个可迭代对象时,for循环通过iter()知道要迭代的项,并使用next()方法返回后续的项。
既然我们知道了Python迭代器是如何工作的,我们可以更深入地研究并从头开始创建一个迭代器,以更好地了解其是如何凑效的。
我将创建一个用于打印所有偶数的简单迭代器
class Sequence(): def __init__(self): self.num = 2 def __iter__(self): return self def __next__(self): val = self.num self.num += 2 return val 让我们分解一下这段Python代码:
我们可以创建Sequence对象来遍历Sequence类,在该对象上调用next()方法:
it = Sequence() print(next(it)) print(next(it)) print(next(it)) print(next(it)) print(next(it)) 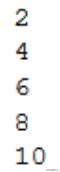
我没有写sequence结束的条件,因此迭代器将永远继续返回下一个值。但我们可以使用停止条件轻松地对其进行更新:
sample = ['statistics', 'linear algebra', 'probability'] # iterator it = iter(sample) # next values print(next(it)) print(next(it)) print(next(it))我刚刚加入了一条if语句,只要值超过10,该语句就会停止迭代:
it = Sequence() for i in it: print(i)
在这里,我没有使用next()方法从迭代器返回值,而是使用了for循环,该循环的工作方式与之前相同。
生成器也是迭代器,但更加优雅。使用生成器,我们可以实现与迭代器相同的功能,但不必在类中编写iter()和next()函数。相反,我们可以使用一个简单的函数来完成与迭代器相同的任务:
# fibonacci sequence using a generator def fib(): prev, curr = 0, 1 # infinite loop while prev<5: value = prev # Calculate the next number in the sequence. Using Tuple unpacking. prev, curr = curr, prev + curr # yield the value yield value 你是否注意到这个生成器函数和常规函数的不同?是的,yield关键字!
普通函数使用return关键字返回值。但是生成器函数使用yield关键字返回值。这就是生成器函数与常规函数不同的地方(除了这种区别,它们是完全相同的)。
yield关键字的工作方式类似于普通的return关键字,但有额外的功能:它能记住函数的状态。因此,下次调用generator函数时,它不是从头开始,而是从上次调用中停止的位置开始。
让我们看看它是如何工作的:
# generator object gen=fib() print(gen) # values print(next(gen)) print(next(gen)) print(next(gen)) print(next(gen)) print(next(gen)) 
生成器属于“生成器”类型,它是迭代器的一种特殊类型,但仍然是迭代器,因此它们也是懒惰的工作者。除非next()方法明确要求它们这样做,否则它们不会返回任何值。
最初创建fib()生成器函数的对象时,它会初始化prev和curr变量。现在,当在对象上调用next()方法时,生成器函数会计算值并返回输出,同时记住函数的状态。因此,下次调用next()方法时,该函数将从上次停止的地方开始,从那里继续。
每当使用next()方法时,该函数将继续生成值,直到prev变得大于5,这时将引起StopIteration异常,如下所示:
print(next(gen))
你不必在每次执行生成器时都编写函数。相反,你可以使用生成器表达式,就像列表生成式一样。唯一的区别是,与列表生成式不同,生成器表达式包含在圆括号内,如下所示:
squared_gen = (x*x for x in range(2,5)) print(squared_gen)
但它们仍然很懒,因此你需要使用next()方法。但你现在知道使用for循环可以更好地返回值:
for i in squared_gen: print(i) 
当你编写简单的代码时,生成器表达式非常有用,因为它们易读、易理解。但随着代码变得更复杂,它们的功能会迅速变弱。在这种情况下,你发现自己会重新使用生成器函数,生成器函数在编写更复杂的函数方面提供了更大的灵活性。
一个重要的问题:为什么要先考虑用迭代器?
我在文章开头提到了这一点:之所以使用迭代器,是因为它们为我们节省了大量内存。这是因为迭代器在生成时不会计算项,而只会在调用它们时计算。
如果我创建一个包含1000万个项的列表,并创建一个包含相同数量项的生成器,则它们内存大小上的差异将令人震惊:
import sys # list comprehension mylist = [i for i in range(10000000)] print('Size of list in memory',sys.getsizeof(mylist)) # generator expression mygen = (i for i in range(10000000)) print('Size of generator in memory',sys.getsizeof(mygen)
对于相同的数量的项,列表和生成器在内存大小上存在巨大差异。这就是迭代器的美。
不仅如此,你可以使用迭代器逐行读取文件中的文本,而不是一次性读取所有内容。这会再次为你节省大量内存,尤其是在文件很大的情况下。
在这里,让我们使用生成器来迭代读取文件。为此,我们可以创建一个简单的生成器表达式来懒惰地打开文件,一次读取一行:
file = "Greetings.txt" # generator expression lines = (line for line in open(file)) print(lines) # print lines print(next(lines)) print(next(lines)) print(next(lines)) 
这很棒,但对于数据科学家或分析师而言,他们最终都要在Pandas的 dataframe中处理大型数据集。当你不得不处理庞大的数据集时,也许这个数据集有几千行数据点甚至更多。如果Pandas可以解决这一难题,那么数据科学家的生活将变得更加轻松。
好吧,你很幸运,因为Pandas的read_csv()(
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html)有处理该问题的chunksize参数。它使你可以按指定大小的块来加载数据,而不是将整个数据加载到内存中。处理完一个数据块后,可以对dataframe对象执行next()方法来加载下一个数据块。就这么简单!
我将读取Black Friday数据集(
https://datahack.analyticsvidhya.com/contest/black-friday/?utm_source=blog&utm_medium=
python-iterators-and-generators),该数据集包含550,068行数据,读取时设置每块的大小为10,这样做只是为了演示该函数的用法:
import pandas as pd # pandas dataframe df = pd.read_csv('./Black Friday.csv', chunksize=10) # print first chunk of data next(df)
# print second chunk of data next(df) 
很有用,不是吗?
我确信你现在已经习惯于使用迭代器,而且一定在考虑把所有函数转换为生成器!你开始喜欢Python编程的强大之处。
你以前使用过Python迭代器和生成器吗?或者你要与社区分享其他“隐藏的宝石”?大家可以在下方评论!
原文标题:
What are Python Iterators and Generators? Programming Concepts Every Data Science Professional Should Know
原文链接:
https://www.analyticsvidhya.com/blog/2020/05/python-iterators-and-generators/
编辑:黄继彦
校对:谭佳瑶















