
作为数据分析师,我们日常工作中使用的最多自然是SQL查询,是真正的“金刚钻”本领。
通常包括了Spark SQL、Hive SQL、MySQL等等,我们主要通过它们提取数据库中的数据记录。
而在处理一些外部数据时,如TXT文本数据、CSV日志数据等,SQL没有Excel或者Python来的灵活。
如果需要把数据进行报表化、可视化,我们又会偏向使用PowerBI或者Tableau这类商业BI工具。
这些工具之间的设计思路、运行原理、编写语法、操作步骤等等,的确存在着很大不同点。
但是它们又有着最大的共同点:必须围绕我们的目标需求来执行,否则再强的工具也毫无意义而言了。
比如你要筛选出天津市的销售订单,你无论用何种工具方法,都得把订单给找出来,整别的都没用的!
所以,在解决问题这点上,它们没有不同,更没有强弱之分。
选择分析工具,不是看谁功能多,而是看谁能解决问题!
面对同一目标,四大数据分析工具都是如何操作的呢?
实际工作中,我们经常在不同工具间来回切换,或者同时配合使用几种工具
因此我们总是需要不断记忆和搜索相关的操作步骤,这是一个很繁琐又浪费时间的过程。
为了彻底解决这个问题,本次老海把四个工具放在一起,同步横向对比:
在相同目标要求下,Excel、MySQL、Power BI、Python 四大数据分析工具的操作要点
比如:筛选出天津市的销售订单,这四种工具各自都是如何具体操作的,尽量做到一目了然!
与某种工具的深度文章不同,此次主要是常见步骤的操作对比,是操作方法的大集合。
本次内容由老海独家编辑整理,整个过程相当耗时,由于内容较多,计划分为上中下三篇完成。
感兴趣的朋友,可以关注我,收藏文章方便后期查找。
OK,我们下面来同步对比这些工具操作情况:
演示工具版本环境:
OFFCIE2013或2016,
MYSQL8.0以上,
Python3.7,
PowerBI 2020年5月版本
案例模拟数据情况:
本次依旧使用之前的模拟数据,与业务无关,仅供演示:
以下是涉及的表结构,共6张数据表,本文中主要涉及销售数据表、产品表、顾客信息表
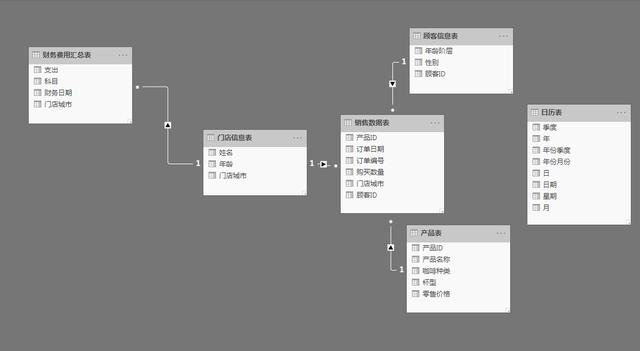
数据实例,如下图所示:
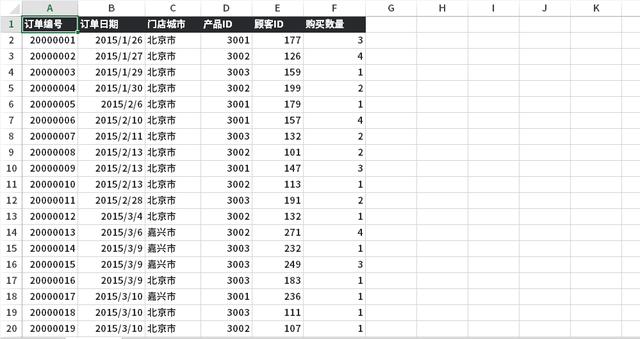
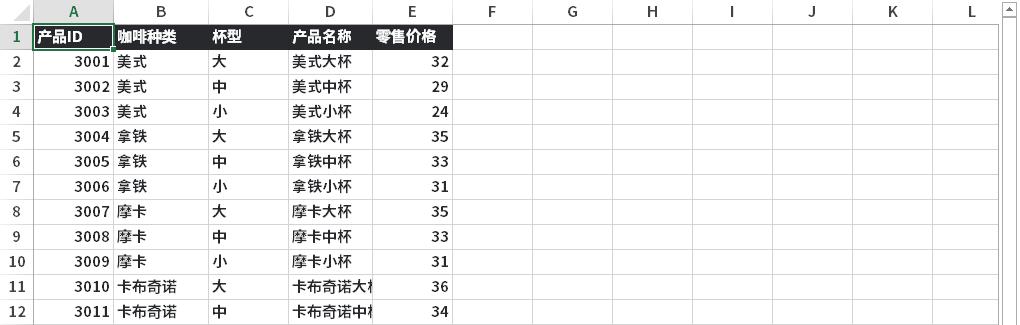
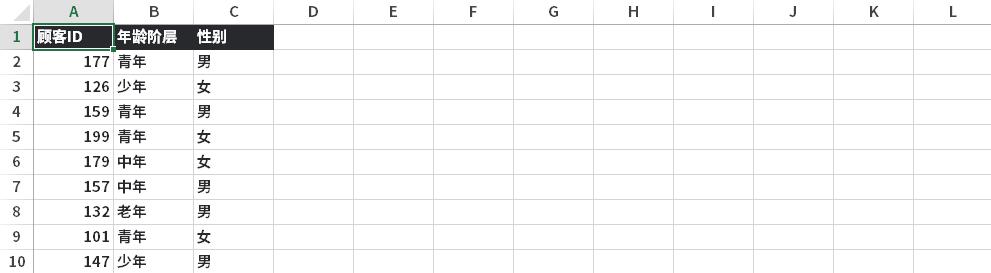
数据集相对比较简单,容易理解。
OK,接下来,我们将按数据预处理的基本流程开始操作演示:
数据准备和导入
当使用Excel时:
- 没啥说的,直接打开xlsx或者xls文件即可。
- 打开速度与你自己的电脑配置直接相关,同样的配置情况下,笔记本的打开速度要大打折扣。
- 经常玩EXCEL数据比较大的同学,老海建议你上个台式机吧,速度快还稳定,特别爽。
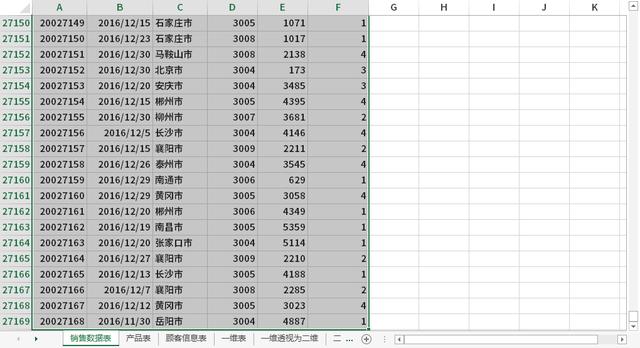
特别注意:Excel本身有数据记录的数量限制,如果你的数据量很大,使用EXCEL文件类型,可能会造成数据读取不全,以及各种卡顿报错。
所以当数据量够大的时候,建议直接更换其他工具,请不要在Excel上一路走黑。
当使用MySQL时:
我们一般可连接数据库后台,添加公司的主机、账户密码登录即可,一般公司局域网内使用
特别提示:MySQL8.0以后,登录密码编码类型发生了变化,可能出现报错
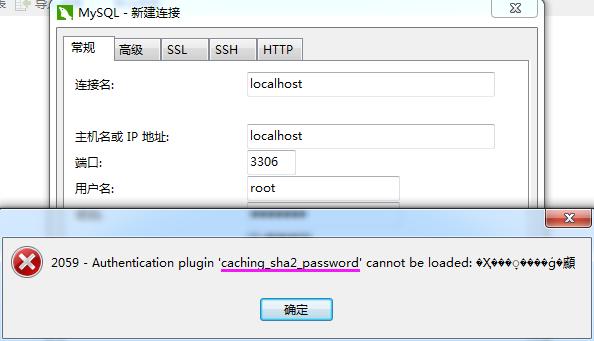
一般需要先启动MySQL服务:

设置密码、修改密码编码方式、刷新服务,三个步骤来解决

- 第一步:OK,这里我们使用本地搭建的环境,采用人工数据导入的方式
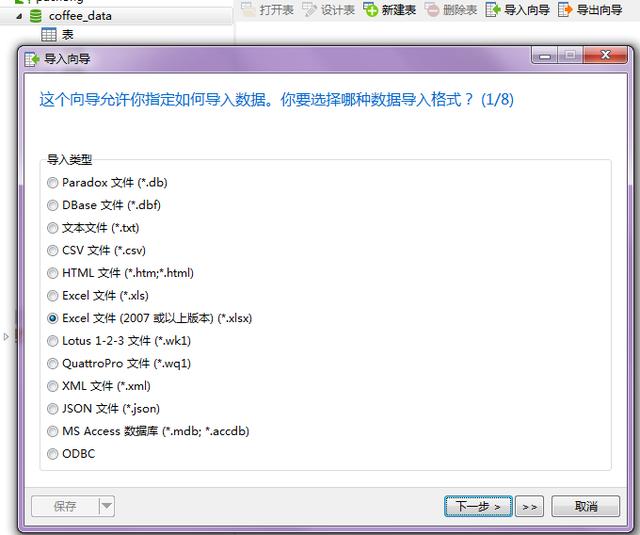
- 第二步:选择相应的数据文件类型,一般为XLS、XLSX、CSV、TXT、JSON等等。
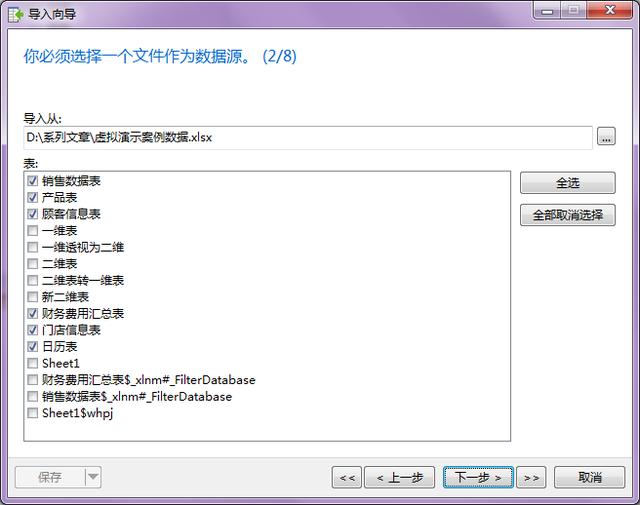
- 第三步:然后我们选择数据源里的具体表格,比如这里我们选择了6个表格
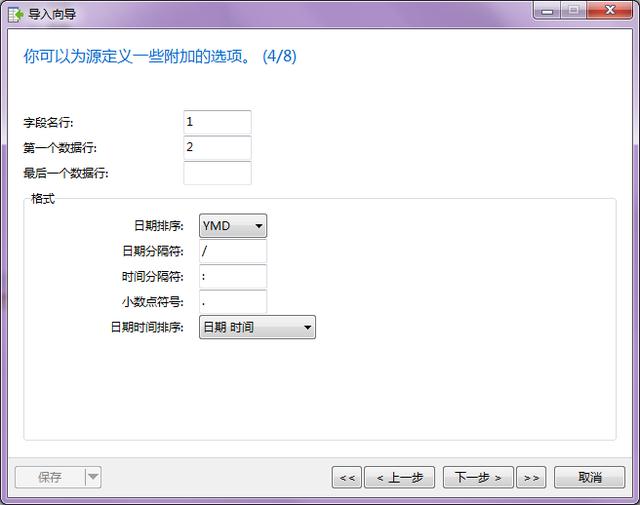
- 第四步:设置数据字段名称行,一般都是第一行
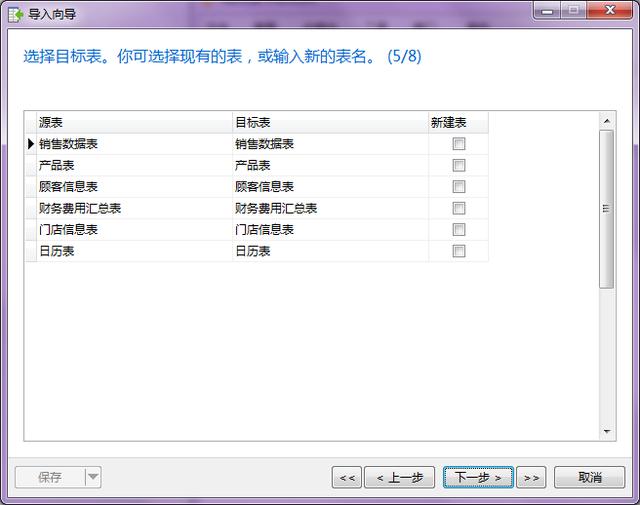
- 第五步:可以设置导入后表名,这里为了方便演示,就不再调整了。
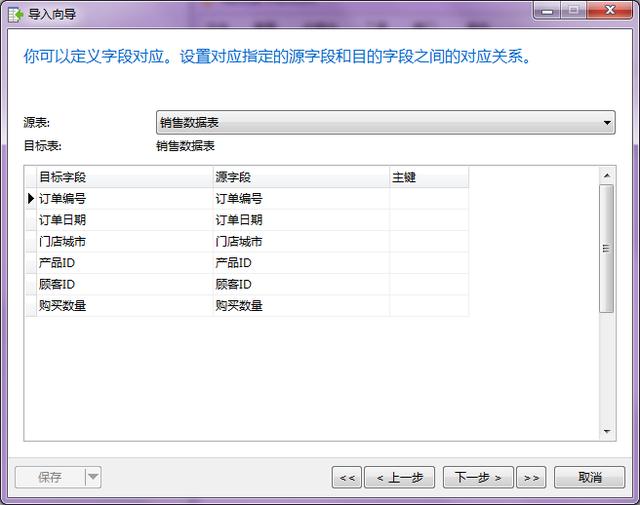
- 第六步:同样可以设置导入表中的字段名称,这里老海不再调整。
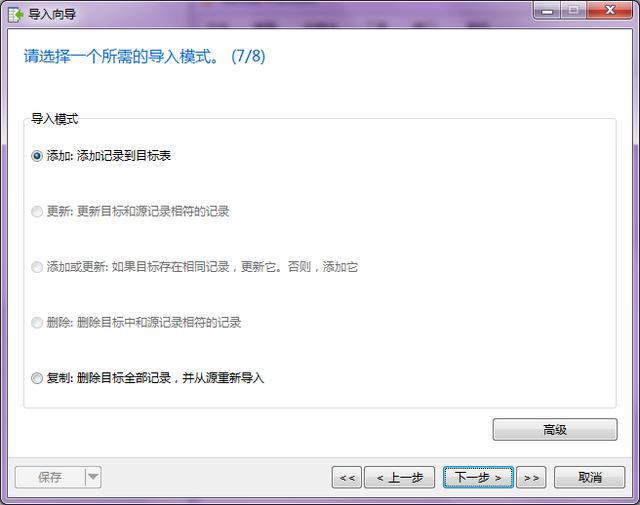
- 第七步:然后选择导入模式,是添加、更新、还是复制,这里我们同样选择默认。
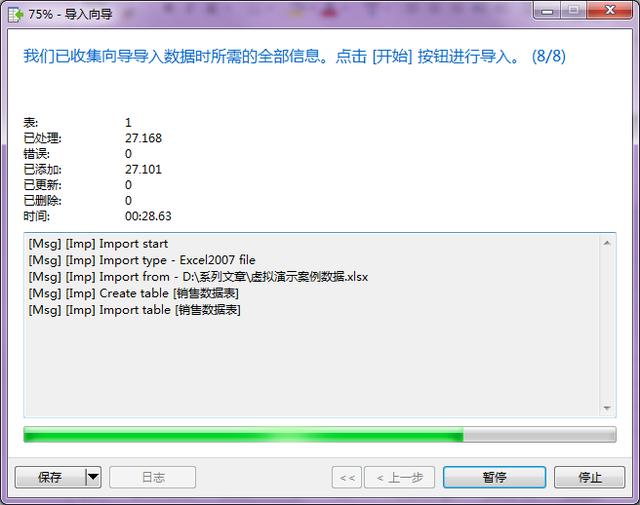
- 第八步:点击“开始”按钮,数据不大的话,很快就完成了。
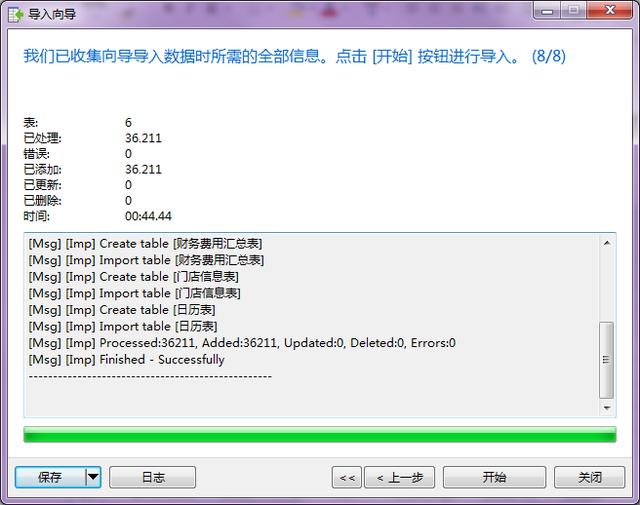
特别注意:当提示成功导入后,记得点击“关闭”,而不是“开始”,不然又会重新导入
此时我们可以看到数据表已经导入成功了,还可以打开数据表看一下是否显示正常。
当使用Power BI时:
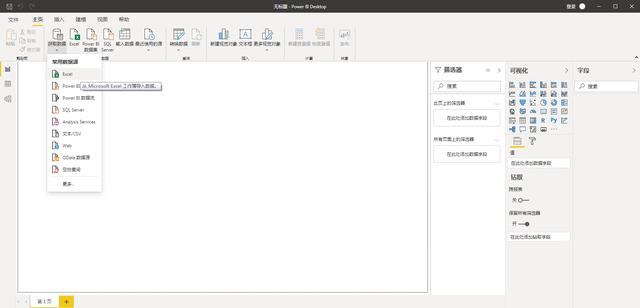
- 第一步:我们打开PowerBI,选择“获取数据”,选择“常见数据源”中的Excel
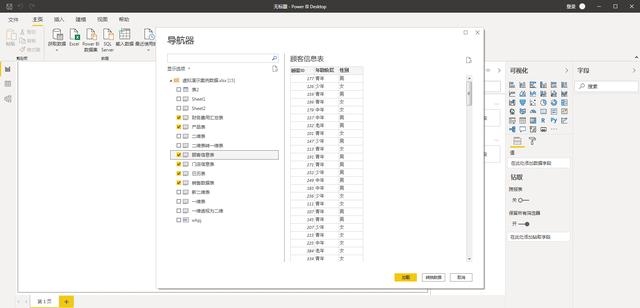
- 第二步:然后选择,需要导入的数据表,这里演示选择了6个表格导入到数据模型里
- 第三步:我们可以看到数据表里面具体的数据字段情况,检查是否显示正常。
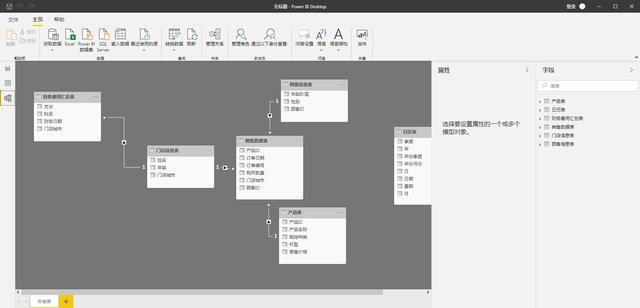
特别注意:PowerBI导入多个数据表格后,会自动选择字段进行表格关联,但这种关联不一定是你实际业务的情况。
你要根据业务工作的实际情况来确定字段是否合理,关联方式是否合理,比如是左连接、还是右连接等等。
使用Python:
- 第一步:我们先引入必要的pandas、numpy、sys等包,查看运行环境
- 第二步:然后设定好我们的工作路径,这里是根据我们自己的情况来自行设置的。

- 第三步:最后我们引入需要处理的数据源

特别注意:当我们使用pandas读取Excel表格数据时,默认会只读取第1个sheet,因此当需要读取特定的sheet时,请通过参数来指定完成。
另外pandas的读取速度,与数据文件的大小、以及你自己设备的内存直接相关,当数据文件很大,比如10G,一般会受到你设备内存大小的影响,读取速度变慢,此时考虑分批读取或者使用SQL在服务器上处理。
OK,以上就是关于模拟数据背景、以及数据准备与导入的内容。
限于篇幅,上篇先介绍到这里,欢迎后续后续的2篇内容,涉及数据查看与筛选、更新与删除、分组聚合、多表关联、多表联合、排序与分组、存储与导出等操作。
本系列文章内容较长,建议随手收藏下来,相信总有需要的时候!












