正则表达式(Regular Expressions),也称为 “regex” 或 “regexp” 是使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,这样程序就可以将该模式与任意文本字符串相匹配。
使用正则表达式,可以为要匹配的可能字符串集指定规则;此集可能包含英语句子,电子邮件地址,TeX命令或你喜欢的任何内容
正则表达式引擎:
采用不同算法,检查处理正则表达式的软件模块 PCRE (perl compatible regular expressions)
正则表达式的元字符分类: 字符匹配,匹配次数,位置锚定,分组
Python/ target=_blank class=infotextkey>Python 的正则表达式是 PCRE标准 的。
# 字符匹配
. 匹配任意单个字符(换行符除外)
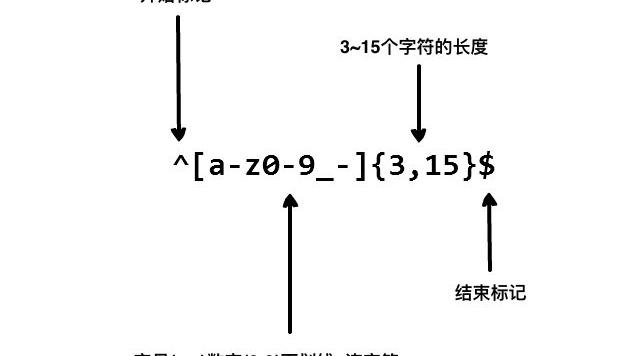
[]匹配指定范围内的任意单个字符: [0-9] [a-z]
^[xxx]以[]内的任意字符开头
[^xxx]: 除了[]内的字符,相当于取反
# 匹配次数
用于指定前面的字符要出现几次
* 匹配前面的字符的任意次,包括0次, 贪婪匹配:尽可能长的匹配
.* 任意长度的任意字符
? 匹配其前面的字符0或1次
+ 匹配前面的字符至少1次
{n} 匹配前面的字符n次
{m,n} 匹配前面的字符至少m次,最多n次如{1,3} 匹配1到3次
{n,} 匹配前面的字符至少n次
# 位置锚定
# 用于定位出现的位置
^ 行首
$ 行尾
^$ 空行
# 分组
() 分组,用()将多个字符捆绑在一起,当作一个整体处理
后向引用: 1,2
# | 或者
a|b a 或 b
(A|a)bc Abc或abc
# 转义
反斜杠后面可以跟各种字符,以指示各种特殊序列。它也用于转义所有元字符.因此您仍然可以在模式中匹配它们,如果你需要匹配 [ 或 ,你可以在它们前面加一个反斜杠来移除它们的特殊含义:[ 或 \。
d 匹配任何十进制数,等价于类 [0-9]
w 匹配任何字母与数字字符包括下划线;这相当于类 [a-zA-Z0-9_]。
s 匹配任何空白字符;这等价于类 [ tnrfv]。
D 匹配任何非数字字符;这等价于类 [^0-9]。
W 匹配任何非字母与数字字符;这相当于类 [^a-zA-Z0-9_]。
S 匹配任何非空白字符;这相当于类 [^ tnrfv]。在 python 中使用正则表达式要使用 re 模块。
[正则表达式][
https://docs.python.org/zh-cn/3/howto/regex.html#regex-howto ]
[re模块使用][
https://docs.python.org/zh-cn/3/library/re.html ]