0. 学习目标
在顺序存储方式中,根据数据元素的序号就可随机存取表中任何一个元素,但同时在插入和删除运算需要移动大量的元素,造成算法效率较低。解决此缺陷的一个办法是:对线性表采用链式存储方式。在链表存储方式中,在逻辑上相邻的数据元素在存储空间中不一定相邻,数据元素的逻辑次序是通过链表中指针链接实现的。本节将介绍链式存储结构的特点以及各种基本操作的实现。 通过本节学习,应掌握以下内容:
线性表的链式存储及实现方法
链表基本操作的实现
利用链表的基本操作实现复杂算法
1. 线性表的链式存储结构
链式存储结构用于存放线性表中的元素的存储单元在内存中可以是连续的,也可以是零散分布的。由于线性表中各元素间存在着线性关系,为了表示元素间的这种线性关系,链式存储结构中不仅要存储线性表中的元素,还要存储表示元素之间逻辑关系的信息。所以用链式存储结构表示线性表中的一个元素时至少需要两部分信息,除了存储每一个数据元素值以外,还需存储其后继或前驱元素所在内存的地址。采用链式存储结构表示的线性表简称链表 (Linked List)。
1.1 指针相关概念
在继续进行讲解前,我们首先来了解指针的相关概念,以便更好的理解链表。假设我们需要处理一个大型数据文件,这一文件已经被读取保持在内存中,当我们在函数间传递文件时,并不会直接传递整个文件,我们需要创建变量来保存文件在内存中的位置,这些变量很小,很容易在不同的函数之间传递。
使用指针的好处之一就是可以用一个简单的内存地址就可以指向一个更大的内存地址段。计算机硬件中存在对指针的支持,称为间接寻址。
与 C 语言等不同,在 Python/ target=_blank class=infotextkey>Python 中,我们不需要直接操作指针,但这并不意味着 Python 中不使用指针。例如赋值语句 l = list([1, 2, 3]),我们通常会说 l 是列表类型的变量,或者直接说 l 是一个列表,但这并不准确,变量 l 是对列表的引用(指针),list 构造函数在内存中的创建一个 list 并返回该 list 起始的内存位置,这就是存储在 l 中的内容,Python 隐藏了这种复杂性。
1.2 指针结构
每个指针结构都包含一个或多个指向结构中其他元素的链接,这些链接的类型取决于我们创建的数据类型,例如在链表中, 我们将链接到结构中的下一个或上一个元素。
指针结构具有如下优点:
- 不需要连续的顺序存储空间
- 可以快速添加或删除结点,在常数时间内扩展结构空间
但指针的这种灵活性是有代价的,即需要额外的空间来存储地址。例如有一个整数线性表,我们在每个结点中不仅需要存储一个整数数据,同时还需要一个额外空间用于存储指向下一个结点的指针。
1.3 结点
一个结点是一个数据容器,以及一个或多个指向其它结点的链接,链接就是一个指针。一种简单的结点只有到下一个结点的链接。假如我们有一个包含水果清单的链表,我们知道字符串实际上并不存储在结点中,而是有一个指向实际字符串的指针,如下图所示,其中包含两个结点,第一个结点有一个指向存储在内存中的字符串 (Apple) 的指针和一个存储下一个结点地址的指针,因此,这个简单结点的存储要求是两个内存地址,包括数据域和指针域:

我们还需要考虑的一个问题是,最后一个结点的指针域,我们需要确保每个结点的指针域都指向一个明确的值。如果我们要明确让最后一个结点的指针域不指向任何内容,那么在 Python 中,我们需要使用特殊值 None 来表示什么都没有。 如下图所示,链表的最后一个结点的指针域指向 None:

1.4 结点类
接下来,我们将实现上述结点结构:
class Node:
def __init__(self, data=None):
self.data = data
self.next = None
Next 指针初始化为 None,这意味着默认结点为端点,除非更改 Next 的值,这样可以确保正确终止链表。我们也可以根据需要向结点类添加其他内容,例如我们可以创建一个 Fruit 类,用于存储不同水果售价信息等数据,并使用数据域链接到 Fruit 类的实例。 为了能够打印节点信息,我们需要重载 str 方法:
def __str__(self):
return str(self.data)
2. 单链表的实现
通常,“链表”是指单链表,单链表由许多结点组成,其中每个结点都有只有一个指向直接后继的 next 指针,链表中最后一个节点的链接为 None,表示链表结束。访问数据元素只能由链表头依次到链表尾,而不能做逆向访问,这是一种最简单的链表。而其它链表类型(包括双向链表、循环链表等)将在之后小节中进行讲解。
单链表分为带头结点和不带头结点两种类型。因为链表中的第一个结点没有直接前驱,它的地址需要放在链表的头指针变量中;而其它结点的地址放入直接前驱结点的指针域中。在链表中插入和删除结点时,对第一个结点和其它结点的处理是不同的。因此为了操作方便,就在链表的头部加入一个“头结点”,其指针域中存放第一个数据结点的地址,头指针变量中存放头结点的地址。下图 (a) 中表示不带头结点的链表,其头指针 linked_list 指向第一个数据结点,而图 (b) 中表示不带头结点的链表头指针 linked_list 指向头结点,头结点的指针域指向第一个数据结点:

Note:在接下来的实现的单链表基本操作中,若不特别说明,采用带有头结点的链表。
2.1 单链表的初始化
单链表表的初始化建立一个空的带头结点的单链表,其表长 length 初始化为 0,此时链表中没有元素结点,只有一个头结点,其指针域为空:
class SinglyLinkedList:
def __init__(self):
self.length = 0
# 初始化头结点
head_node = Node()
# 头指针指向头结点
self.head = head_node
创建单链表 SinglyLinkedList 对象的时间复杂度为O(1)。
2.2 获取单链表长度
由于我们在链表中使用 length 跟踪链表中的项数,因此求取单链表长度只需要重载 len 从对象返回 length 的值,因此时间复杂度为O(1):
def __len__(self):
return self.length
2.3 读取指定位置元素
为了实现读取链表指定位置元素的操作,我们将重载 getitem 操作。我们已经知道单链表中的结点只能顺序存取,即访问前一个结点后才能接着访问后一个结点。因此要访问单链表中第i个元素值,必须从头指针开始遍历链表,依次访问每个结点,直到访问到第i个结点为止。因此操作的复杂度为O(n)。同时,我们希望确保索引在可接受的索引范围内,否则将引发 IndexError 异常:
def __getitem__(self, index):
if index > self.length - 1 or index < 0:
rAIse IndexError("SinglyLinkedList assignment index out of range")
else:
count = -1
current = self.head
while count < index:
current = current.next
count += 1
return current.data
我们也可以实现修改指定位置元素的操作,只需要重载 setitem 操作,其复杂度同样为O(n):
def __setitem__(self, index, value):
if index > self.length - 1 or index < 0:
raise IndexError("SinglyLinkedList assignment index out of range")
else:
count = -1
current = self.head
while count < index:
current = current.next
count += 1
current.data = value
2.4 查找指定元素
当查找指定元素时,需要设置一个跟踪链表结点的指针 current,初始时 current 指向链表中的第一个数据结点, 然后顺着 next 域依次指向每个结点,每指向一个结点就判断其值是否等于指定值 value,若是则返回该结点索引;否则继续往后搜索,如果链表中无此元素,则引发 ValueError 异常,其时间复杂度为O(n):
def locate(self, value):
count = -1
current = self.head
while current != None and current.data != value:
count += 1
current = current.next
if current and current.data == value:
return count
else:
raise ValueError("{} is not in sequential list".format(value))
2.5 在指定位置插入新元素
单链表结点的插入只需要修改结点指针域的值,使其指向新的链接位置,而无需移动任何元素。 例如我们要在链表中索引为 i ii 处插入一个新结点,必须首先找到所插位置的前一个结点 i − 1 i-1i−1,再进行插入,设指针 previous 指向待插位置的前驱结点,指针 current 指向插入前链表中索引为 i ii 的结点,同时也是待插位置的后继结点,指针 new_node 指向待插新结点,插入操作过程如下所示:

使用 Python 实现算法如下:
def insert(self, index, data):
count = -1
current = self.head
# 判断插入位置的合法性
if index > self.length or index < 0:
raise IndexError("SinglyLinkedList assignment index out of range")
else:
node = Node(data)
while count < index:
# 查找插入位置
previous = current
current = current.next
count += 1
# 插入新结点
node.next = previous.next
previous.next = node
self.length += 1
也可以利用上述思想,直接在链表中插入结点:
def insert_node(self, index, node):
count = -1
current = self.head
if index > self.length or index < 0:
raise IndexError("SinglyLinkedList assignment index out of range")
else:
while count < index:
previous = current
current = current.next
count += 1
node.next = previous.next
previous.next = node
self.length += 1
2.6 删除指定位置元素
要删除链表中第 i ii 个结点,首先在单链表中找到删除位置的前一个结点 previous,指针 current 指向要删除的结点,将 previous 的指针域修改为待删除结点 current 的后继结点的地址,删除后的结点需动态的释放。下图 (b) 中的粉色虚线表示删除结点 current 后的指针指向:

使用 Python 实现算法如下:
def __delitem__(self, index):
if index > self.length - 1 or index < 0:
raise IndexError("SinglyLinkedList assignment index out of range")
else:
count = -1
previous = self.head
while count < index - 1:
previous = previous.next
count += 1
current = previous.next
previous.next = current.next
self.length -= 1
del current
在插入和删除操作中,都是先确定操作位置,然后再进行插入和删除操作,所以其时间复杂度均为O(n)。由于算法在进行插入和删除操作时没有移动元素的位置,只是修改了指针链接,所以采用链表存储方式进行插入和删除操作要比顺序存储方式的效率高。
2.7 其它一些有用的操作
2.7.1 链表元素输出操作
将单链表转换为字符串以便进行打印,使用 str 函数调用对象上的 str 方法可以创建适合打印的字符串表示:
def __str__(self):
s = "["
current = self.head.next
count = 0
while current != None:
count += 1
s += str(current)
current = current.next
if count < self.length:
s += '-->'
s += "]"
return s
2.7.2 删除指定元素
与删除指定位置元素略有不同,删除指定元素需要在链表中删除第一个具有与给定值相同数据元素的结点,其时间复杂度同样为O(n):
def del_value(self, value):
current = self.head
previous = self.head
while current != None:
if current.data == value:
previous.next = current.next
self.length -= 1
del current
return
else:
previous = current
current = current.next
raise ValueError("The value provided is not present!")
2.7.3 在链表尾部追加新元素
为了方便的在链表尾部追加新元素,可以实现函数 append:
def append(self, value):
node = Node(value)
current = self.head
while current.next is not None:
current = current.next
current.next = node
self.length += 1
此算法的时间复杂度为O(n),如果需要经常在链表尾部追加新元素,可以使用增加尾指针 tail 用于追踪链表的最后一个元素,利用尾指针在链表尾部追加新元素时间复杂度可以降至O(1)。
3. 单链表应用
接下来,我们首先测试上述实现的链表,以验证操作的有效性,然后利用实现的基本操作来实现更复杂的算法。
3.1 单链表应用示例
首先初始化一个链表 sllist,并在其中追加若干元素:
sllist = SinglyLinkedList()
# 在链表末尾追加元素
sllist.append('apple')
sllist.append('lemon')
# 在指定位置插入元素
sllist.insert(0, 'banana')
sllist.insert(2, 'orange')
我们可以直接打印链表中的数据元素、链表长度等信息:
print('链表为:', sllist)
print('链表长度为:', len(sllist))
print('链表第0个元素为:', sllist[0])
# 修改数据元素
sllist[0] = 'pear'
print('修改链表数据后:', sllist)
以上代码输出如下:
链表为: [banana-->apple-->orange-->lemon] 链表长度为: 4 链表第0个元素为: banana 修改链表数据后: [pear-->apple-->orange-->lemon]
接下来,我们将演示在指定位置添加/删除元素、以及如何查找指定元素等:
# 在指定位置添加/删除结点
sllist.insert(1, 'grape')
print('在位置1添加grape后链表数据:', sllist)
del(sllist[2])
print('修改链表数据后:', sllist)
# 删除指定元素
sllist.del_value('pear')
print('删除pear后链表数据:', sllist)
sllist.append('watermelon')
print('添加watermelon后链表数据:', sllist)
以上代码输出如下:
在位置1添加grape后链表数据: [pear-->grape-->apple-->orange-->lemon] 修改链表数据后: [pear-->grape-->orange-->lemon] 删除pear后链表数据: [grape-->orange-->lemon] 添加watermelon后链表数据: [grape-->orange-->lemon-->watermelon]
3.2 利用单链表基本操作实现复杂操作
[1] 利用基本运算函数,将一单链表逆置,如下图 (a) 所示为逆置前链表,图 (b) 为逆置后链表,并要求算法的空间复杂度为O(1):

为了保证算法的空间复杂度为O(1),只能修改原结点的指针,设置指针 current, 令其指向 head->next,并令head.next=None,然后使用 current 指针依次遍历每个结点并插入到 head 之后。该算法只需要对链表顺序扫描一遍即可完成倒置,因此时间复杂度为O(n),算法实现如下:
def reverse_linked_list(sllist):
head_node = sllist.head
if head_node.next:
current = head_node.next
head_node.next = None
sllist.length = 0
while current:
previous = current
current = current.next
sllist.insert_node(0, previous)
return sllist
# 算法测试
sllist = SinglyLinkedList()
for i in range(5):
sllist.append(i)
print('逆置前:', sllist)
print('逆置后:', reverse_linked_list(sllist))
算法输出如下:
逆置前: [0-->1-->2-->3-->4] 逆置后: [4-->3-->2-->1-->0]
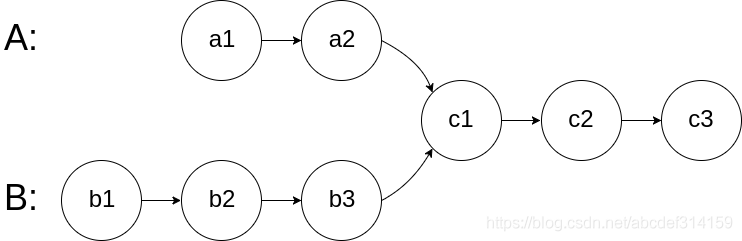
算法执行流程如下所示:

[2] 删除单链表中的重复结点,如下图操作所示,(a) 为删除前的情况,(b) 为删除后的状态。

用指针 previous 指向第一个数据结点,并使用另一个指针 curent 指向 previous 的直接后继开始遍历整个链表,当遇到具有相同的数据元素的结点时将其删除;然后 previous 指向下一个结点,重复删除过程;直到 previous 指向最后结点时算法结束:
def delete_same_node(sllist):
previous = sllist.head.next
if not previous:
return
while previous:
current = previous
while current.next:
if current.next.data == previous.data:
same = current.next
current.next = current.next.next
sllist.length -= 1
del same
else:
current = current.next
previous = previous.next
return sllist
# 算法测试
sllist = SinglyLinkedList()
print('删除重复结点前:', sllist)
sllist.append(10)
sllist.append(11)
sllist.append(10)
sllist.append(10)
sllist.append(11)
print('删除重复结点后', delete_same_node(sllist))
该算法的时间复杂度为O(n2),程序输出如下:
删除重复结点前: [10-->11-->10-->10-->11] 删除重复结点后: [10-->11]
算法执行流程如下所示: