1、链表是物理存储单元上非连续的、非顺序的存储结构,数据元素的逻辑顺序是通过链表的指针地址实现,有一系列结点(地址)组成,结点可动态的生成。
2、结点包括两个部分:(1)存储数据元素的数据域(内存空间),(2)存储指向下一个结点地址的指针域。
3、相对于线性表顺序结构,操作复杂。
4.链表分为 (1)单链表 (2)双链表 (3)单向循环链表 (4)双向循环链表
二:链表的作用
1、实现数据元素的存储按一定顺序储存,允许在任意位置插入和删除结点。
2、包括单向结点,双向结点,循环接点
三:链表与数组的区别
说到链表那肯定要聊一下数组,为什么会出现链表呢?
(1)数组:使用一块连续的内存空间地址去存放数据,但
例如:
int a[5]={1,2,3,4,5}。突然我想继续加两个数据进去,但是已经定义好的数组不能往后加,只能通过定义新的数组
int b[7]={1,2,3,4,5,6,7}; ***********这样就相当不方便比较浪费内存资源,对数据的增删不好操作。
(2)链表:使用多个不连续的内存空间去存储数据, 可以 节省内存资源(只有需要存储数据时,才去划分新的空间),对数据的增删比较方便。
四、链表的优缺
优点:
(1)插入和删除速度快,保留原有的物理顺序,在插入或者删除一个元素的时候,只需要改变指针指向即可。(2)没有空间限制,存储元素无上限,只与内存空间大小有关。(3)动态分配内存空间,不用事先开辟内存
缺点:
(1)占用额外的空间以存储指针,比较浪费空间,不连续存储,malloc函数开辟空间碎片比较多) (2) 查找速度比较慢,因为在查找时,只能顺序查找,需要循环链表
五、关于头指针,头节点,首元节点的那些事
头指针:指向链表第一个节点的指针(不一定是头节点,因为……链表要是没有头节点呢?),没有实际开辟空间 (即没有用malloc等动态分配内存) 而且必须存在,因为头指针不存在,就不便于对链表进行操作。
头节点:不是必须存在(若存在则为链表的第一个节点)其主要作用是使所有链表(包括空表)的头指针非空,并使对单链表的插入、删除操作不需要区分是否为空表或是否在第一个位置进行(还是挺有用的)。其数据域可以不储存任何数据,若储存则通常是链表的长度啥的。
首元节点:第一个数据域中储存有效数据的节点 若头节点不存在 则其为链表的第一个节点,是一定要存在的(除非是空表)
有关链表的一些操作
1.单链表
节点结构默认为:
struct ListNode
{
int val;
struct ListNode *next;
}
①单链表的创建
//创建链表
struct ListNode* createList()
{
struct ListNode*p=NULL,*tAIl=NULL,*head=NULL;//p为待开辟的节点指针,tail为指向链表尾部的指针,head为指向链表头部的指针。
//笔者喜欢在创建链表时 创建head tail 两个指针 虽然不一定都用得到
int num; //将指针置空是个好习惯
scanf("%d",&num);
//尾插法 顺序插法
while(num!=-1)//假设以num/val值为-1作为链表的结束标志 或者你用定长条件也行
{
p=(struct ListNode*)malloc(sizeof(struct ListNode));//注意此处用sizeof计算大小时在ListNode前要加struct关键字
p->val=num;
p->next=NULL;
if(head==NULL)//第一次循环时将头指针head指向p
{
head=p;
}
else
{
tail->next=p;
}
tail=p;//此句放else里面也行 笔者更喜欢在第一次循环时就将tail与p与head产生关联
scanf("%d",&num);
}
// 头插法 逆序插法
// while(num!=-1)
// {
// p=(struct ListNode*)malloc(sizeof(struct ListNode));
// p->val=num;
// if(head==NULL)
// {
// head=p;
// }
// else
// {
// p->next=head;
// head=p;
// }
// }
tail->next=NULL//用p->next也行 这是尾插法
return head;//返回链表头指针
}
②链表节点的插入
struct ListNode *insertList(ListNode *head,int index,int num)//index 表示在链表中插入的位置(从1开始)原位置的元素接在其后 num表示要插入的数值
{
struct ListNode *p=NULL,q;//在此q为虚拟节点 主要方便对链表进行操作
int cnt=1;//计数器从1开始计数
if(head==NULL&&head->next==NULL)//链表为空 返回一个空指针
return NULL;
if(index==1)//若插在头结点(在此特指链表的第一个节点)的位置
{
p=(struct ListNode*)malloc(sizeof(struct ListNode));//给p开辟实际空间 用来储存操作存入的值
p->val=num;
p->next=head;
head=p;
}
else
{
q=head;
while(q->next!=NULL&&cnt<=index)//对于链表我们通常对当前节点的下一个节点进行操作
{
if(cnt+1<index)//为什么要加一呢?因为表示下一个位置
{
q=q->next;
}
else
{
p=(struct ListNode *)malloc(sizeof(struct ListNode));
p->val=num;
p->next=q->next;
q->next=q;
}
}
}
if(cnt<index)//如果cnt还是 小于 index 则表明插在链表末尾
{
p=(struct ListNode*)malloc(sizeof(struct ListNode));
p->val=num;
p->next=NULL;
q->next=p;
}
return head;
}
③链表节点的删除
struct ListNode *deleteList(struct ListNode *head,int num)//执行删除节点val值为num的操作
{
struct ListNode *p=NULL,*q=NULL;//p,q均为辅助指针 不给他们开辟实际空间
if(head->val==num)//若删除节点为头结点
{
p=head;
head=head->next;
free(p);
}
else//若删除节点为除头结点外的其他节点
{
p=head;
while(p->next!=NULL)
{
if(p->next->val==num)
{
q=p->next;
p->next=p->next->next;
free(q);
}
else
{
p=p->next;
}
}
}
return head;
}
链表的遍历
void printList(struct ListNode *head)
{
struct ListNode *p=head;//p依然为辅助指针
while(p!=NULL)//因为是遍历(打印输出)操作 所以对当前节点进行操作即可
{
printf("%d",p->val);
p=p->next;
}
}
双向链表
双向链表即单链表由单向的链变成了双向的链(一个指针域(next)变成一前一后两个指针域(prev,next)) 这里只演示双向链表的创建
另:
节点结构为:
struct ListNode
{
int val;
ListNode *prev;
ListNode *next;
};
双向链表的创建
struct ListNode *createDbList()
{
struct ListNode*p=NULL,*head=NULL,*tail=NULL;
int num;
scanf("%d",&num);
while(num!=-1)//以-1作为创建链表结束的标志
{
p=(struct ListNode*)malloc(sizeof(struct ListNode));
p->val=num;
if(head==NULL)//这里主要演示尾插法
{
head=p;
p->prev=NULL; //就不将双向链表和循环链表相互掺和了
}
else
{
tail->next=p;
p->prev=tail;
}
tail=p;
}
tail->next=NULL;
}
循环链表
即将链表首尾相接 同样这里只演示循环链表的创建
struct ListNode *createList()
{
struct ListNode*p,*head,*tail;
int num;
scanf("%d",&num);
while(num!=-1)
{
p=(struct ListNode*)malloc(sizeof(struct ListNode));
p->val=num;
if(head==NULL)
{
head=p;
}
else
{
tail->next=p;
}
tail=p;
}
tail->next=head;//创建结束后将链表首尾相接
}
静态链表
静态链表的节点通常用结构体数组表示
struct staticListNode
{
int val;
int cur;//游标cur用来储存后继节点的下标
};
1.Floyd判圈法:判断链表是否有环(快慢指针的应用)
对于链表找环路的问题,有一个通用的解法——快慢指针(Floyd) 。给定两个指针, 分别命名为 slow 和 fast ,起始位置在链表的开头。每次 fast 前进两步, slow 前进一步。如果 fast 可以走到尽头,那么说明没有环路;如果fast 可以无限走下去,那么说明一定有环路,且一定存 在一个时刻 slow 和 fast 相遇。当 slow 和 fast 第一次相遇时,我们将 fast 重新移动到链表开头,并 让 slow 和 fast 每次都前进一步。当 slow 和 fast 第二次相遇时,相遇的节点即为环路的开始点。
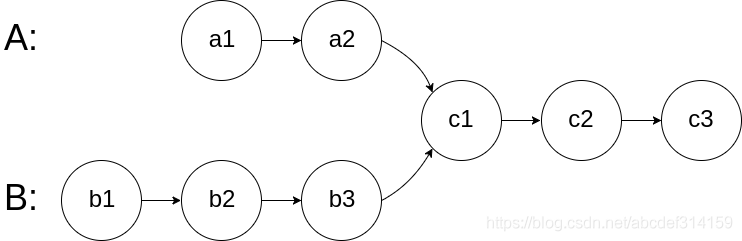
2. 判断两个链表是否相交
假设链表 A 的头节点到相交点的距离是 a,链表 B 的头节点到相交点的距离是 b,相交点到链表终点的距离为 c。我们使用两个指针,分别指向两个链表的头节点,并以相同的速度前进,若到达链表结尾,则移动到另一条链表的头节点继续前进。按照这种前进方法,两个指针会在a + b + c 次前进后同时到达相交节点
————————————————
版权声明:本文为CSDN博主「legendarykk」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.NET/legendarykk/article/details/125592024