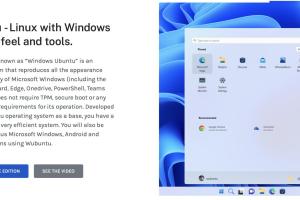
某云上用户反馈,虚拟机cpu负载 软中断SI 指标高 ,请求云厂商协助排查

从图示来看,cpu3 软中断任务明显 ,大量的负载中断都发生在cpu3上
linux 中的中断处理程序分为上半部和下半部:
上半部对应硬件中断,用来快速处理中断。
下半部对应软中断,用来异步处理上半部未完成的工作。
Linux 中的软中断包括网络收发、定时、调度、等各种类型,可以通过查看 /proc/softirqs 来观察软中断的运行情况
排查过程
1. vmstat 1 : 可以看到cpu 每秒上下文切换和中断次数较多,cpu 有较多队列等待

cs(context switch)是每秒上下文切换的次数。
in(interrupt)则是每秒中断的次数。
r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待CPU的进程数。
b(Blocked)则是处于不可中断睡眠状态的进程数。
2.pidstat -w 查看进程上下文切换情况
# 每隔5秒输出1组数据
$ pidsat -w 5
Linux 4.15.0 (ubuntu) 09/23/18 _x86_64_ (2 CPU)
08:18:26 UID PID cswch/s nvcswch/s Command
08:18:31 0 1 0.20 0.00 sysemd
08:18:31 0 8 5.40 0.00 rcu_schedcswch ,表示每秒自愿上下文切换(voluntary context switches)的次数,
nvcswch ,表示每秒非自愿上下文切换(non voluntary context switches)的次数
3. cat /proc/softirqs : 查看软中断统计 : 可以分析发现 ,cpu3 上的中断条目最多�.NET_RX 网络数据包接收软中断的变化比较快 ,网卡收发包大部分处理都在cpu3 , 单cpu 有处理阻塞现象

4.. ethtool -l eth0 查看网卡队列情况 : 网卡队列只有一个 , NET_RX 中断负载在cpu3 ,初步定位单队列原因导致网络中断网络中断不能负载均衡,大部都集中在cpu3 处理

5.使能网络中断负载均衡 , 打算调整虚拟机网卡队列数,virsh edit domAIn , 添加如下 : 队列改成为8

6.在控制台重启虚拟机 ,通过VNC 登录虚拟机看是否生效 ,检查已经生效

7.再次查看cpu中断负载情况 : top 命令查看 : 发现si中断比较分散在各个核上 ,问题解决

通过增加网络多队列,让cpu 软中断负载均衡 ,问题得到解决
举例说明软中断机制 :
举个生活中的例子"
比如说你订了一份外卖,但是不确定外卖什么时候送到,也没有别的方法了解外卖的进度,但是,配送员送外卖是不等人的,到了你这儿没人取的话,就直接走人了。所以你只能苦苦等着,时不时去门口看看外卖送到没,而不能干其他事情。
不过呢,如果在订外卖的时候,你就跟配送员约定好,让他送到后给你打个电话,那你就不用苦苦等待了,就可以去忙别的事情,直到电话一响,接电话、取外卖就可以了。 这里的“打电话”,其实就是一个中断。
没接到电话的时候,你可以做其他的事情;只有接到了电话(也就是发生中断),你才要进行另一个动作:取外卖。
这个例子你就可以发现,中断其实是一种异步的事件处理机制,可以提高系统的并发处理能力。
事实上,为了解决中断处理程序执行过长和中断丢失的问题,Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部:
上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关工作。
下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。
比如说前面取外卖的例子,上半部就是你接听电话,告诉配送员你已经知道了,其他事儿见面再说,然后电话就可以挂断了;下半部才是取外卖的动作,以及见面后商量发票处理的动作。
除了取外卖,我再举个最常见的网卡接收数据包的例子,让你更好地理解。
网卡接收到数据包后,会通过硬件中断的方式,通知内核有新的数据到了。这时,内核就应该调用中断处理程序来响应它。
对上半部来说,既然是快速处理,其实就是要把网卡的数据读到内存中,然后更新一下硬件寄存器的状态(表示数据已经读好了),最后再发送一个软中断信号,通知下半部做进一步的处理。
而下半部被软中断信号唤醒后,需要从内存中找到网络数据,再按照网络协议栈,对数据进行逐层解析和处理,直到把它送给应用程序。
所以,这两个阶段你也可以这样理解:
上半部直接处理硬件请求,也就是我们常说的硬中断,特点是快速执行;
而下半部则是由内核触发,也就是我们常说的软中断,特点是延迟执行;
其他场景举例 :
提问 : 经常听同事说大量的网络小包会导致性能问题,为什么呢?
回答 : 因为大量的网络小包会导致频繁的硬中断和软中断,所以大量网络小包传输很慢,但如果将网络包一次传递,是不是会快很多呢 ,就是这个道理