作者:jeremyshi,腾讯 TEG 后台开发工程师
随着移动互联网、物联网、云计算等信息技术蓬勃发展,数据量呈爆炸式增长。如今我们可以轻易得从海量数据里找到想要的信息,其中离不开搜索引擎技术的帮助。特别是其中的索引、检索和排序机制,我们无需深入了解背后复杂的信息检索原理,即可实现基本的全文检索功能。数据量达到十亿,百亿规模仍然可以秒级返回检索结果。对于系统容灾、数据安全性、可扩展性、可维护性等我们关注的实际问题,在开源搜索引擎领域排名第一的 Elasticsearch 里均能得到有效解决。
Elasticsearch(ES)是一个基于 Lucene 构建的开源分布式搜索分析引擎,可以近实时的索引、检索数据。具备高可靠、易使用、社区活跃等特点,在全文检索、日志分析、监控分析等场景具有广泛应用。由于高可扩展性,集群可扩展至百节点规模,处理 PB 级数据。通过简单的 RESTful API 即可实现写入、查询、集群管理等操作。除了检索,还提供丰富的统计分析功能。以及官方功能扩展包 XPack 满足其他需求,如数据加密、告警、机器学习等。另外,可通过自定义插件,如 COS 备份、QQ 分词等满足特定功能需求。下面主要介绍 ES 的架构以及基本原理。

Elasticsearch集群
基本概念 :

数据模型类别
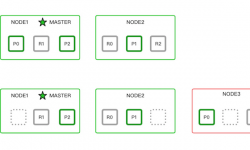
从上面架构图可以看出,ES 架构非常简洁。内置自动发现实现 Zen discovery,当一个节点启动后,通过联系集群成员列表即可加入集群。由其中一个节点担任主节点,用于集群元数据管理,维护分片在节点间的分配关系。当新节点加入集群后,Master 节点会自动迁移部分分片至新节点,均衡集群负载。

节点加入集群
分布式集群难免有节点故障。主节点会定期探测集群其他节点存活状态,当节点故障后,会将节点移出集群。并自动在其他节点上恢复故障节点上的分片。主分片故障时会提升其中一个副本分片为主分片。其他节点也会探活主节点,当主节点故障后,会触发内置的类 Raft 协议选主,并通过设置最少候选主节点数,避免集群爆裂。

节点离开集群
除了集群管理,索引数据读写也是我们关心的重要部分。ES 采用 peer-to-peer 架构,每个节点保存全量分片路由信息,也就是每个节点均可以接收用户读写。如发送写入请求至节点 1,写入请求默认通过文档 ID 的 Hash 值确定写入到哪个主分片,这里假设写入到分片 0。写完主分片 P0,并行转发写入请求至副本分片 R0 所在节点,当副本分片所在节点确认写入成功后返回客户端报告写入成功,保障数据安全性。并且写入前,会确保 quorum 数量的副本数,避免网络分区导致写入数据不一致。

写入操作
查询采用分布式搜索,如请求发给节点 3 后,请求会转发至索引的主分片或副本分片所在节点。当然如果写入、查询均带有路由字段信息。请求只会发送给部分分片,避免全量分片扫描。这些节点完成查询后将结果返回给请求节点,由请求节点汇聚各个节点的结果返回给客户端。

查询操作
介绍完 ES 集群基本原理,下面简单介绍下 ES 的底层存储引擎 Lucene。首先 Lucene 是一款高性能的信息检索库,提供索引和检索基本功能。ES 在此基础上解决可靠性、分布式集群管理等问题最终形成产品化的全文检索系统。
Lucene 解决的核心问题便是全文检索。与传统的检索方式不同,全文检索避免在查询时进行全部内容扫描。比如数据写入后,首先会对写入的文档字段内容分词,形成词典表和与它关联的倒排表。查询时由关键词分词结果直接匹配词典表内容,并获取关联的文档列表,快速获取结果集。并通过排序规则,优先展示匹配度高的文档。

倒排索引
Lucene 为了加快索引速度,采用了 LSM Tree 结构,先把索引数据缓存在内存。当内存空间占用较高或到达一定时间后,内存中的数据会写入磁盘形成一个数据段文件(segment)。段文件内包含词典、倒排表、字段数据等等多个文件。

LSM Tree结构
为了兼容写入性能和数据安全性,如避免内存缓冲区里的数据因为机器故障丢失。ES 在写内存的同时也会写事物日志 Translog。内存里的数据会定期生成新的段文件,写入开销更低的文件系统缓存即可打开和读取实现近实时搜索。

写入缓冲与持久化
ES 的典型使用场景有日志分析、时序分析、全文检索等。
日志是互联网行业基础广泛的数据形式。典型日志有用来定位业务问题的运营日志,如慢日志、异常日志;用来分析用户行为的业务日志,如用户的点击、访问日志;以及安全行为分析的审计日志等。
Elastic 生态提供了完整的日志解决方案。通过简单部署,即可搭建一个完整的日志实时分析服务。ES 生态完美的解决了日志实时分析场景需求,这也是近几年 ES 快速发展的一个重要原因。日志从产生到可访问一般在 10s 级,相比于传统大数据解决方案的几十分钟、小时级时效性非常高。ES 底层支持倒排索引、列存储等数据结构,使得在日志场景可以利用 ES 非常灵活的搜索分析能力。通过 ES 交互式分析能力,即使在万亿级日志的情况下,日志搜索响应时间也是秒级。日志处理的基本流程包含:日志采集 -> 数据清洗 -> 存储 -> 可视化分析。Elastic Stack 通过完整的日志解决方案,帮助用户完成对日志处理全链路管理。

日志分析链路
其中:

可视化组件Kibana
3.2 时序分析场景 时序数据是按时间顺序记录设备、系统状态变化的数据。典型的时序数据有传统的服务器监控指标数据、应用系统性能监控数据、智能硬件、工业物联网传感器数据等。早在 2017 年我们也基于 ES 进行了时序分析场景的探索。时序分析场景具有高并发写入、低查询时延、多维分析的特点。由于 ES 具有集群扩展、批量写入、读写带路由、数据分片等能力,目前已实现线上单集群最大规模达到 600+节点、1000w/s 的写入吞吐、单条曲线或单个时间线的查询延时可控制在 10ms。另外 ES 提供灵活、多维度的统计分析能力,实现查看监控按照地域、业务模块等灵活的进行统计分析。另外,ES 支持列存储、高压缩比、副本数按需调整等能力,可实现较低存储成本。最后时序数据也可通过 Kibana 组件轻松实现可视化。
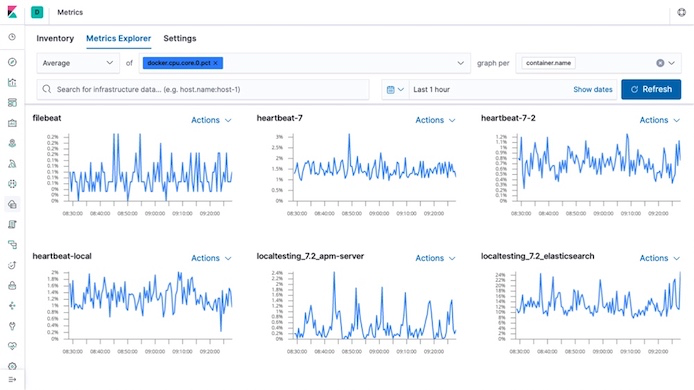
时序数据可视化面板
3.3 搜索服务场景 搜索服务典型场景有像京东、拼多多、蘑菇街中的商品搜索;应用商店中的应用 App 搜索;论坛、在线文档等站内搜索。这类场景用户关注高性能、低延迟、高可靠、搜索质量等。如单个服务最大需达到 10w+ QPS,请求平均响应时间在 20ms 以内,查询毛刺低于 100ms,高可用如搜索场景通常要求 4 个 9 的可用性,支持单机房故障容灾等。目前云上 Elasticsearch 服务已支持多可用区容灾,故障分钟级恢复能力。通过 ES 高效倒排索引,以及自定义打分、排序能力与丰富的分词插件,实现全文检索需求。在开源全文检索领域,ES 在 DB-Engines 搜索引擎类别持续多年排名第一。

DB-Engines搜索引擎排名
公司内外部均有大量的日志实时分析、时序数据分析、全文检索需求场景。目前我们已联合 Elastic 公司在腾讯云上提供了内核增强版 ES 云服务简称 CES,其中内核增强包括 Xpack 商业套件和内核优化。在服务公司内部以及公有云客户过程中,也遇到了较多问题和挑战,比如超大规模集群,千万级数据写入,以及云上用户丰富的使用场景等。下面主要介绍我们在内核层面,从可用性,性能,成本等方面进行的优化措施。

可用性 问题表现在三个方面,第一,ES 内核 系统健壮性不足 ,这也是分布式系统共性难题。例如异常查询、压力过载集群容易出现雪崩。集群可扩展性不足,比如集群分片数超 10w 会出现明显的元数据管理瓶颈。以及集群扩容、节点异常后加回集群,存在节点、多硬盘之间数据不均问题。第二, 容灾方面 需保障机房网络故障时可快速恢复服务,自然灾害下防止数据丢失,误操作后快速恢复数据等可靠性、数据安全性问题。另外也包括在运营过程中也发现的一些 ES 系统缺陷 ,比如说 Master 节点堵塞、分布式死锁、滚动重启缓慢等。

针对上面的问题,在 系统健壮性 方面,我们通过服务限流,容忍机器网络故障、异常查询等导致的服务不稳定问题。通过优化集群元数据管理逻辑,提升集群扩展能力一个数量级,支持千亿节点集群、百万级分片数。集群均衡方面,通过优化节点、多硬盘间的分片均衡,保证大规模集群的压力均衡。
容灾方案 方面,我们通过扩展 ES 的插件机制实现数据备份和回档,可把 ES 的数据备份到 COS,保障数据安全性;通过管控系统建设支持跨可用区容灾,用户可以按需部署多个可用区,以容忍单机房故障。采用垃圾桶机制,保证用户在欠费、误操作等场景下,集群数据可快速恢复。系统缺陷方面,我们修复了滚动重启、Master 阻塞、分布式死锁等一系列 Bug。其中滚动重启优化,可加速节点重启速度 5+倍。Master 堵塞问题,我们在 ES 6.x 版本和官方一起做了优化。
性能 问题,比如以日志、监控为代表的时序场景,对写入性能要求非常高,写入并发可达 1000w/s。然而我们发现在带主键写入时,ES 性能会衰减 1+倍。压测场景下发现 CPU 存在无法充分利用的情况。通常搜索服务对查询性要求非常高,一般要求 20w QPS, 平均响应时间小于 20ms,并且需尽量避免 GC、以及执行计划不优等造成的查询毛刺问题。

为了解决这些问题。写入方面,针对主键去重场景,我们通过利用段文件上记录的最大最小值进行查询裁剪,加速主键去重的过程,写入性能提升 45%,具体可参考Lucene-8980。对于压测场景下 CPU 不能充分利用的问题,通过优化 ES 刷新 Translog 时锁粒度,避免资源抢占,提升性能提升 20%,具体可参考ES-45765 /47790。我们也正在尝试通过向量化执行优化写入性能,通过减少分支跳转、指令 Miss,预期写入性能可提升 1 倍。
查询方面,我们通过优化段文件合并策略,对于非活跃段文件会自动触发合并,收敛段文件数以降低资源开销,提升查询性能。根据每个段文件上记录的最大最小值进行查询剪枝,提升查询性能 40%。通过 CBO 策略,避免缓存较大开销的 Cache 操作导致产生 10+倍的查询毛刺,具体可参考Lucene-9002。另外还包括优化 Composite 聚合中的性能问题,实现真正的翻页操作,以及优化带排序场景的聚合使得性能提升 3-7 倍。此外,我们也在尝试通过一些新硬件来优化性能,比如说英特尔的 AEP、Optane、QAT 等。

成本 方面主要体现在以日志、监控为代表的时序场景对机器资源的消耗。结合线上典型的日志、时序业务统计数据发现,硬盘、内存、计算资源的成本比例接近 8:4:1。可以得出硬盘、内存是主要矛盾,其次是计算成本。而这类时序类场景有很明显的访问特性,也就是数据具有冷热特性。时序数据访问具有近多远少的特点,比如近 7 天数据的访问量占比可达到 95%以上,而历史数据访问较少,并且通常都是访问统计类信息。
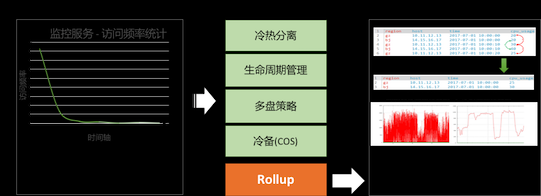
硬盘成本 方面,由于数据具有明显的冷热特性,我们采用冷热分离架构,使用混合存储的方案来平衡成本和性能。由于历史数据通常只是访问统计信息,我们采用预计算 Rollup 换取存储和查询性能,类似物化视图。对于完全不使用历史数据,也可以备份到更廉价的存储系统如 cos。其他一些优化方式包括多盘策略兼容数据吞吐与数据容灾,以及通过生命周期管理等定期删除过期数据等。
内存成本 方面,我们发现特别是大存储机型,存储资源采用了 20%内存已不足。为了解决内存不足问题,我们采用 Off-Heap 技术,来提升堆内内存利用率,降低 GC 开销,并且提升单个节点管理磁盘的能力。将内存占比较大的 FST 移到堆外管理,通过堆内存放堆外对象地址,避免堆内外数据拷贝。通过 JAVA 弱引用机制实现堆外对象内存回收,进一步提升内存使用率。实现 32GB 堆内内存可管理 50 TB 左右磁盘空间,较原生版本有 10 倍提升,并且性能持平,而 GC 优势提升明显。
除了内核层面的优化,该平台层通过管控平台,支持云上服务资源管理、实例实例管理等实现服务托管。方便快捷进行实例创建和规格调整。通过运维支撑平台中的监控系统、运维工具等保障服务质量。并通过正在建设的智能诊断平台发现服务潜在问题,实现了对内外部提供稳定可靠的 ES 服务。

腾讯内部,我们通过主导 ES 产品开源协同,发现潜在问题,共同优化完善 ES,避免不同的团队重复踩坑。同时我们也将优秀的方案积极贡献给社区,和官方及社区的 ES 爱好者们共同推动 ES 的发展。以腾讯 ES 内核研发为代表的团队,截至目前我们共提交了 60 多个 PR,其中有 70% 被合并,公司内 ES 开源协同 PMC 成员共有 6 位 ES/Lucene 社区 contributor。
Elasticsearch 在腾讯内外部广泛应用于日志实时分析、时序数据分析、全文检索等场景。目前单集群规模达到千级节点、万亿级吞吐。通过内核增强版 ES 为大家提供高可靠,低成本,高性能的搜索分析服务。后续我们仍然需在可用性,性能和成本等方面持续优化 ES。比如集群可扩展性不足问题,通过优化集群扩展性支持百万级分片秒级创建 index。ES 的存储成本问题,目前正在研发存储与计算分离方案,进一步缩减成本,提升性能。以及存在使用和维护成本高的问题,后续通过多级分区、智能诊断等提升 ES 的自动化和故障自愈能力,降低用户使用和维护成本。未来,也会进一步探索 ES 在多维分析领域的其他可能性。持续在大数据领域提供更有价值的搜索分析服务。
了解更多
欢迎对 ES 内核技术感兴趣的同学,在腾讯云体验 Elasticearch 服务。