ByConity 基于 ClickHouse 内核开发,采用计算存储分离的架构、主流的 OLAP 引擎和自研的表引擎,提供便捷的弹性扩缩容和极速的分析性能,覆盖实时分析和海量数据的离线分析,帮助企业更好地挖掘数据价值。
责编 | 夏萌
出品 | CSDN(id:csdnnews)
5 月 22 日,字节跳动宣布开源 ByConity 云原生数据仓库。
▶项目地址:https://Github.com/ByConity/ByConity
字节跳动是国内使用 ClickHouse 规模最大的企业之一,此前随着其业务发展和数据规模的增加,在不同的业务场景中遇到了一系列的问题,包括扩缩容成本高、复杂查询性能受限等。为了满足业务诉求,字节跳动数据平台团队在 ClickHouse 社区版本基础上做出架构升级,开发出云原生版本、存储计算分离的数据仓库 ByConity,并自研优化器,提升其复杂查询等性能。
本文将深度介绍 ByConity 项目背景、工作原理、功能特性、技术架构,以及未来规划。
项目背景
ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的 OLAP 引擎优化,如列存储、向量化执行、MPP 执行、查询优化等,ByConity 可以提供优异的读写性能。
ByConity 的背景可以追溯到 2018 年,当时字节跳动开始在内部使用 ClickHouse,因为业务的发展,要服务于大量的用户,数据规模变得越来越巨大。由于 ClickHouse 是 Shared-Nothing 的架构,每个节点是独立的,不会共享存储资源等,因而计算资源和存储资源是紧耦合的,这使得 ClickHouse 在使用过程中会遇到以下情况:
基于这些痛点,字节在 ClickHouse 架构基础上进行了升级,于 2020 年在内部启动了 ByConity 项目,2022年准备开源,并于 2023 年 1 月发布 Beta 版本,5 月底正式对外开源。

图1 字节 ClickHouse 使用情况
据介绍,ByConity 开源之前,字节跳动数据平台团队也曾考虑将自研修改合并回 ClickHouse 社区,与 ClickHouse 核心研发团队、ClickHouse 创业公司负责人做了几次闭门沟通,得到的反馈是架构差异过大、合并难度和代价大、无法联合开发。于是,按照 ClickHouse 社区给到的建议,数据平台团队决定独立开源,并跟 ClickHouse 社区消息同步。
功能特性
ByConity 引入了计算与存储分离的架构,将原本计算和存储分别在每个节点本地管理的架构,转换为在分布式存储上统一管理整个集群内所有数据的架构,使得每个计算节点成为一个无状态的单纯计算节点,并利用分布式存储的扩展能力和计算节点的无状态特性实现动态的扩缩容。正是由于这种改进,使得 ByConity 具有以下重要特性:
技术架构
3.1 整体架构
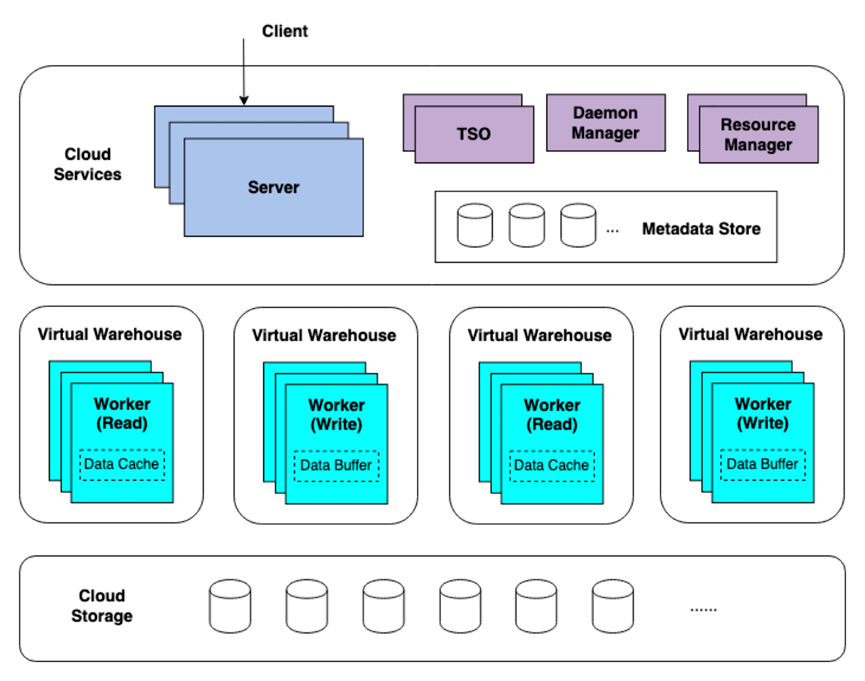
ByConity 的架构分为三层,如图2所示,包括服务接入层,计算层和数据存储层。服务接入层负责客户端数据和服务的接入,也就是 ByConity Server;ByConity 的计算资源层,由一个或者多个计算组构成,每个 Virtual Warehouse(VW)是一个计算组;数据存储层由分布式文件系统,如 HDFS、S3 等构成。
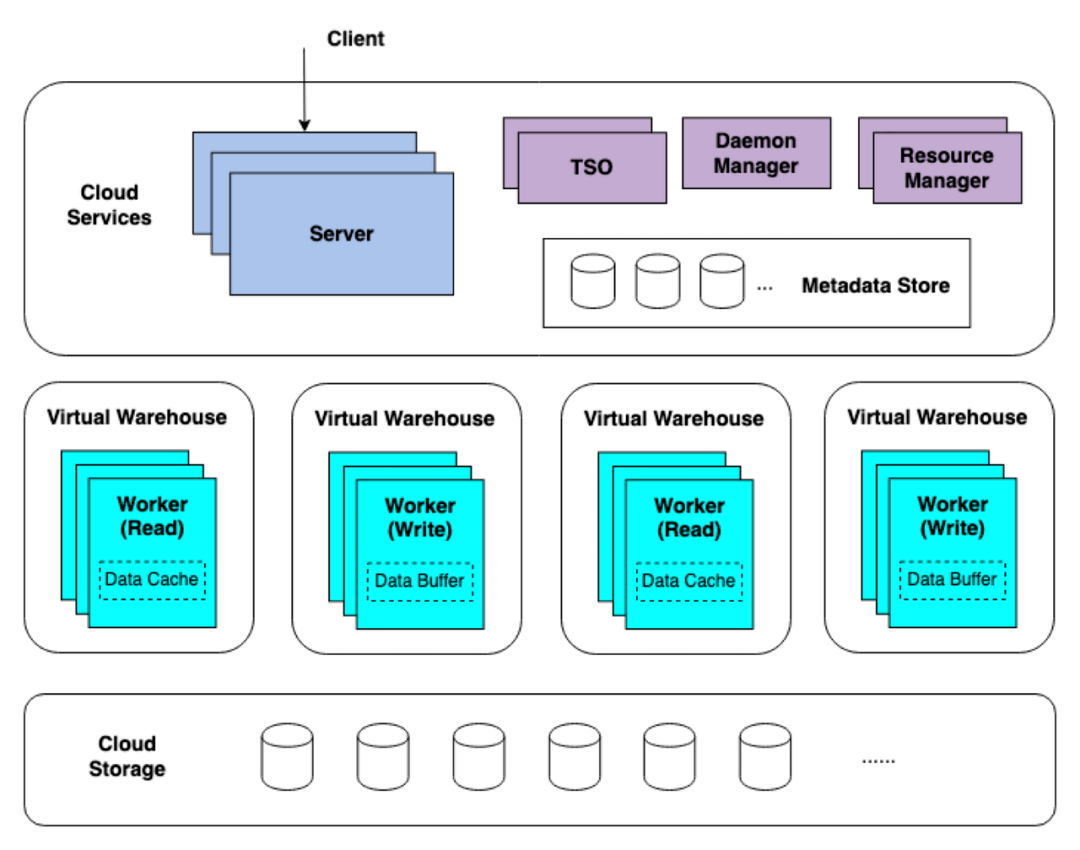
图2 ByConity 三层技术架构图
3.2 工作原理
图 3 是 ByConity 组件交互图,图中虚线部分表示一个 SQL 的流入,实线部分的双向箭头表示组件内的交互,单向箭头表示数据的处理并输出给客户端。字节跳动数据平台团队将通过一个 SQL 的完整生命周期来具体分析它在 ByConity 各个组件的交互过程。
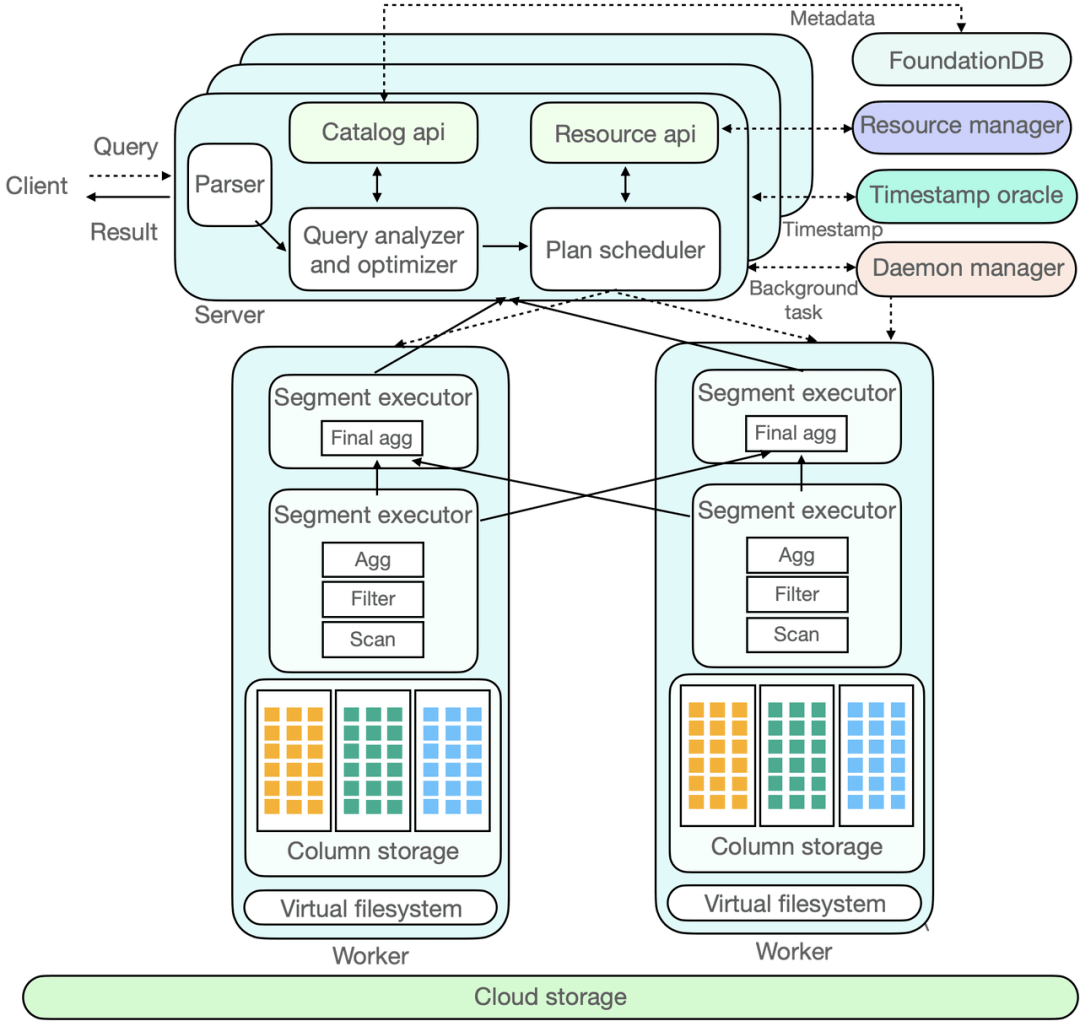
图3 ByConity 内部组件交互图
ByConity 还有两个主要的组件,分别是 Time-stamp Oracle 和 Deamon Manager。前者支持事务处理,后者则对后来的一些任务进行管理和调度。
3.3 主要组件库1)元数据管理
ByConity 提供了一个高可用和高性能的元数据读写服务--Catalog Server,并且支持了完备的事务语义特性(ACID)。同时字节跳动数据平台团队对 Catalog Server 做了比较好的抽象,使得后端的存储系统是可插拔的,当前他们支持的是苹果开源的 FoundationDB,后面可以通过扩展去支持更多的后端存储系统。
2)查询优化器
查询优化器是数据库系统的核心之一。一个优秀的优化器可以大大提高查询性能。尤其是在复杂的查询场景下,优化器可以带来数倍至数百倍的性能提升。ByConity 自研优化器基于两个方向提升优化能力:
ByConity 目前支持两种查询调度策略:Cache-aware 调度和 Resource-aware 调度。其中:
Cache-aware 调度针对计算和存储分离的场景,旨在最大化 Cache 的使用避免冷读。Cache-aware 调度策略会尽可能地将任务调度到拥有对应数据缓存的节点上,实现计算命中 Cache,提升读写性能。同时,由于系统进行动态的扩缩容,当计算组的拓扑发生变化时,需要最小化 Cache 失效对查询性能的影响。
Resource-aware 调度通过感知整个集群中计算组不同节点的资源使用情况,并有针对性地进行调度,以最大化资源利用,同时还会进行流量控制,确保合理使用资源,避免过载造成的负面影响,如系统宕机等。
4)计算组
ByConity支持不同的租户使用不同的计算资源,如图4 所示。在 ByConity 新的架构下,很容易实现了多租户隔离和读写分离等特性。不同租户可以使用不同的计算组,实现多租户隔离,同时支持读写分离。由于扩缩容方便,计算组可以按需进行动态的扩缩容,保证资源利用率高效。当资源利用率不高时,可以进行资源共享,借调计算组给其他租户使用,实现资源的最大化利用并降低成本。
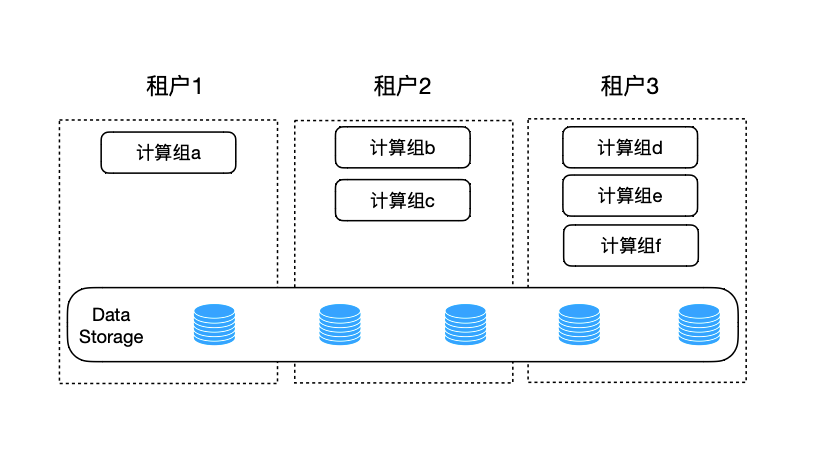
图4 计算组和多租户
5)虚拟文件系统
虚拟文件系统模块作为数据读写的中间层,ByConity 做了比较好的封装,将存储作为一种服务暴露给其他模块使用,实现“存储服务化”。虚拟文件系统提供了一个统一的文件系统抽象,屏蔽了不同的后端实现,方便扩展并支持多种存储系统,如 HDFS 或对象存储等。
6)缓存加速
ByConity 通过缓存进行查询加速,在计算-存储分离的架构下,ByConity 在元数据和数据维度都进行缓存加速。在元数据维度,通过在 ByConity 的 Server 端的内存中进行缓存,以 Table 和 Partition 作为粒度。在数据维度,通过在ByConity 的 Worker 端,也就是计算组进行缓存,而且在 Worker 端的缓存是层次化的,同时利用了 Memory 和磁盘,以 Mark 集合作为缓存粒度,从而有效地提高查询速度。
7)如何获取和部署
ByConity 目前支持四种获取和部署模式,欢迎社区开发者使用,并提 Issue:
开源规划
Roadmap:https://github.com/ByConity/ByConity/issues/26
据悉,ByConity 在 2023 年的开源社区路线图中包括多个关键里程碑。这些里程碑旨在增强 ByConity 的功能、性能和易用性。其中,开发新的存储引擎、支持更多的数据类型和与其他数据管理工具的集成是字节跳动重点关注领域。具体包含以下几个方向:
社区合作共建
总之,ByConity 是一个开源的云原生数据仓库,提供读写分离、弹性扩缩容、租户资源隔离和数据读写的强一致性。其计算-存储分离的架构,结合主流的 OLAP 引擎优化,确保了优异的读写性能。随着 ByConity 的不断发展和改进,其希望成为未来云原生数据仓库的重要工具。
据了解,ByConity 发布 Beta 版本后,得到了来自华为、电子云、展心展力、天翼云、唯品会、传音控股等十几家企业开发者的支持,他们帮助 ByConity 分别在各自的环境下跑通了 TPC-DS 验证,有些在自身业务场景下进行测试并反馈出不错的效果,并提出了诸多改进建议。
ByConity 项目负责人对此表示非常感谢,他也欢迎有意向的团队一起参与社区共建。据了解,目前 ByConity 已收到一些社区伙伴共建的意愿和想法。例如,ByConity 与华为终端云的交流中达成了共建合作,未来会在 Kerberos 鉴权、ORC 的支持、以及支持 S3 存储上一起共建。