环境说明
- flink-1.13.1-bin-scala_2.11.tgz
- [hadoop-2.7.3.tar.gz
- [flink-cdc-connectors](https://Github.com/ververica/flink-cdc-connectors)(git clone源码编译)
- [hudi](https://github.com/Apache/hudi)(git clone源码编译)
- spark-2.4.8-bin-hadoop2.7.tgz
- scala-2.11
- oracle jdk-1.8.x
准备MySQL数据
-- MySQL
CREATE DATABASE mydb;
USE mydb;
CREATE TABLE products (
id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
description VARCHAR(512)
);
ALTER TABLE products AUTO_INCREMENT = 101;
INSERT INTO products
VALUES (default,"scooter","Small 2-wheel scooter"),
(default,"car battery","12V car battery"),
(default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"),
(default,"hammer","12oz carpenter's hammer"),
(default,"hammer","14oz carpenter's hammer"),
(default,"hammer","16oz carpenter's hammer"),
(default,"rocks","box of assorted rocks"),
(default,"jacket","water resistent black wind breaker"),
(default,"spare tire","24 inch spare tire");
CREATE TABLE orders (
order_id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
order_date DATETIME NOT NULL,
customer_name VARCHAR(255) NOT NULL,
price DECIMAL(10, 5) NOT NULL,
product_id INTEGER NOT NULL,
order_status BOOLEAN NOT NULL -- 是否下单
) AUTO_INCREMENT = 10001;
INSERT INTO orders
VALUES (default, '2020-07-30 10:08:22', 'Jark', 50.50, 102, false),
(default, '2020-07-30 10:11:09', 'Sally', 15.00, 105, false),
(default, '2020-07-30 12:00:30', 'Edward', 25.25, 106, false);
启动flink的sql client
./bin/sql-client.sh
创建flink cdc表,以mysql作为数据源,将数据写入到es中和kafka中
创建mysq的flink-sql表
--Flink SQL
-- 设置 checkpoint 间隔为 3 秒
Flink SQL> SET execution.checkpointing.interval = 3s;
Flink SQL> set dfs.client.block.write.replace-datanode-on-fAIlure.enable = ture;
Flink SQL> set dfs.client.block.write.replace-datanode-on-failure.policy = NEVER;
Flink SQL> CREATE TABLE products (
id INT,
name STRING,
description STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'products'
);
Flink SQL> CREATE TABLE orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'orders'
);
Flink SQL> CREATE TABLE shipments (
shipment_id INT,
order_id INT,
origin STRING,
destination STRING,
is_arrived BOOLEAN,
PRIMARY KEY (shipment_id) NOT ENFORCED
) WITH (
'connector' = 'postgres-cdc',
'hostname' = 'localhost',
'port' = '5432',
'username' = 'postgres',
'password' = 'postgres',
'database-name' = 'postgres',
'schema-name' = 'public',
'table-name' = 'shipments'
);
同步数据到ES
Flink SQL> CREATE TABLE enriched_orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
product_name STRING,
product_description STRING
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://localhost:9200',
'index' = 'enriched_orders'
);
Flink SQL> INSERT INTO enriched_orders
SELECT o.*, p.name, p.description
FROM orders AS o
LEFT JOIN products AS p ON o.product_id = p.id
;
- 打开kibana webUI http://localhost:5601/查看数据,
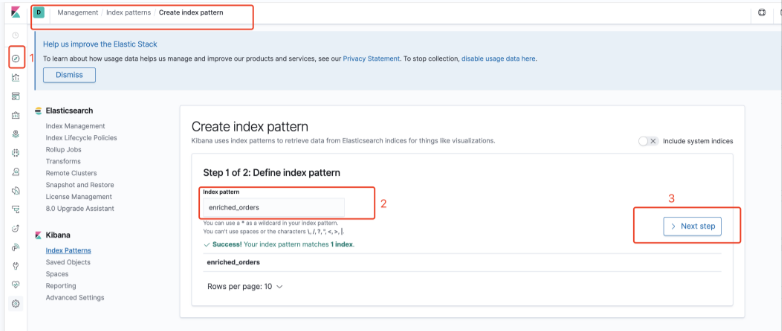
创建索引
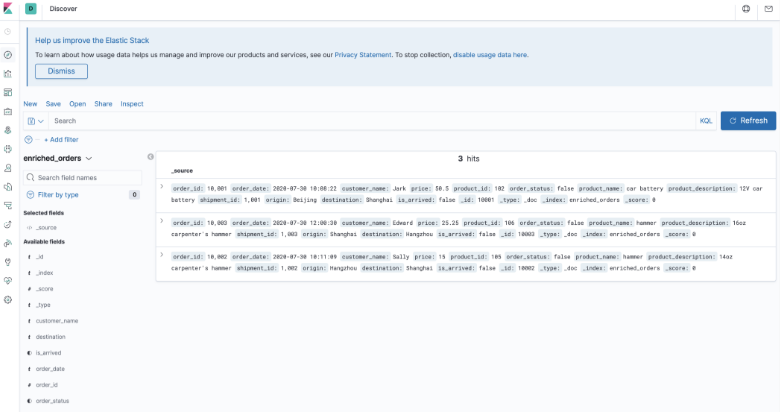
可以看到数据了
为更好的体验CDC的数据同步,可以 修改 mysql 里面的数据,观察 elasticsearch 里的结果
sink到kafka
--Flink SQL
Flink SQL> CREATE TABLE kafka_gmv (
day_str STRING,
gmv DECIMAL(10, 5)
) WITH (
'connector' = 'kafka',
'topic' = 'kafka_gmv',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'changelog-json'
);
Flink SQL> INSERT INTO kafka_gmv
SELECT DATE_FORMAT(order_date, 'yyyy-MM-dd') as day_str, SUM(price) as gmv
FROM orders
WHERE order_status = true
GROUP BY DATE_FORMAT(order_date, 'yyyy-MM-dd');
-- 读取 Kafka 的 changelog 数据,观察 materialize 后的结果
Flink SQL> SELECT * FROM kafka_gmv;
- 观察kafka的数据
kafka-console-consumer.sh --topic kafka_gmv --bootstrap-server kafka:9092 --from-beginning
- 更新 orders 数据,观察SQL CLI 和 kafka console 的输出
-- 更新MySQL
UPDATE orders SET order_status = true WHERE order_id = 10001;
UPDATE orders SET order_status = true WHERE order_id = 10002;
UPDATE orders SET order_status = true WHERE order_id = 10003;
INSERT INTO orders
VALUES (default, '2020-07-30 17:33:00', 'Timo', 50.00, 104, true);
UPDATE orders SET price = 40.00 WHERE order_id = 10005;
DELETE FROM orders WHERE order_id = 10005;