它在线上每天服务几十万的用户,并且流水过亿。没有所谓的微服务、分布式,就是一个war包,然后扔到Tomcat里面去。里面的代码很多,目前我看到的最大的一个类是28000多行代码。是的,我没有多打一个0,确确实实的2w8千多行。
有朋友关心线上是如何部署的,这里分享一下我的方案,大家也可以一起讨论一下。
我曾经独立负责过一个微服务,它承载了晚高峰每小时2000w+次的请求,平均到每秒是大概是5500次的接口调用,线上是用了4台4C8G的阿里云服务器,单机单服务部署方案。
关于业务开发的一些心得,我个人的几点看法:
- 复杂的场景简单化,一定要越简单越好,只有简单了,你才hold住,bug才会少;
- 先不要去考虑性能的事情,先保证功能没bug吧,然后再去考虑性能的事情,当然你的经验会让你写的代码性能优越,优秀的程序员自带性能;
- 高并发的前提是高可用,没有了可用性,谈高并发都是扯淡;
- 写好你自己的代码,然后去压测它,单接口压测、链路压测,找到慢的地方(怎么找?),想办法去优化它,然后你就慢慢的成为了高手,高并发经验就这么来的;
- 能用缓存的就用缓存,数据库其实也很牛逼,前提是你的sql要足够快,慢sql是性能的第一杀手!
- redis基本能hold住大部分的并发请求,当然MQ也很好用,尽量用这些中间件,别自己写了,除非你们有基础架构组。
上述都是扯淡,言归正传。
1、部署架构
开始说我的单体应用是怎么部署的,一图胜千言:

整体情况如下:
- 一个api域名指向阿里云的SLB,SLB指向三台ECS服务器的内网IP并指定端口,权重都100;
- 三台Job服务器,专门去跑任务(各种埋点统计、数据报表、业务job等等);
- 6台ECS的配置都是4C8G,连续包月,费用不高;
- 一台16G集群版Redis,高并发就靠它了;
- 阿里云数据库RDS一主一从,代码里读写分离;
- 日志还是要好好打的,一个优秀的程序员一定会合理有效的log.info、log.error;
2、关于代码开发、测试&部署
如果我说我自己开发、自己测试、自己部署你相信吗?是的,这一切都得我自己来做,我还得自己CR自己的代码,所以这很难。
我没有高大上的方法,也从来不写单元测试,只是写完了自己测试一下,然后自己再过一遍自己的代码,这需要清晰的逻辑。很多时候,思考的时间远远超过写代码的时间,以下是我的一些方法或工具:
- 我有一个代码仓库,使用的是云效codeup;
- 我通过jenkins去构建并发布;
- 我的发布粒度是文件级别,即只同步更改过的class文件或者其他配置文件到指定的服务器上,利用版本控制工具;
- 纯人工灰度,jenkins先发布一台服务,看日志并校验数据验证功能,预计5分钟左右的时间,继续发布剩余的机器,一台一台发布;
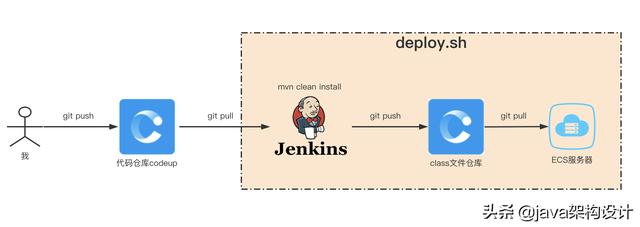
代码提交到部署到服务器大概是这样的一个流程:
我必须要解决一些问题:
- 线上访问量高,如何无缝重启服务?
- 线上日志刷太快,肉眼无法捕捉有效信息,如何确定上线功能是ok的?
- 如何降低上线风险?
- 出现问题,如何快速回滚,最小化业务损失?
- 我怎么能知道线上的代码有问题?(佐证(报表数据)、日志监控)
同时,因为这是一个个人维护的项目,我必须使用一些小而美的技术或者工具,来避免增加运维成本,因此上云是最好的选择。但这不一定适用于你,使用自己熟练的工具才是第一优先级。
3、解决这些问题
1、线上访问量高,如何无缝重启服务?
为了能够做到无缝重启,我需要在重启一台服务器的时候,先把它摘掉,以前我是手动登录阿里云后台去SLB实例管理控制台把这台机器的权重改为0,等重启完毕并且稳定以后(load负载下降到正常值),再恢复权重的100,确定没有问题后,再继续其他2台服务的上述操作。
这样的人工操作占据了我太多的时间,我就在想,能不能我写一个脚本,当我执行这个脚本时候,调用SLB的API先摘掉它,然后服务正常启动后,再调用SLB的API恢复它?幸运的是阿里云提供了这样的API,而我的重启脚本只需要在restart之前,curl一下这个api,并在启动之后,再调用一下恢复权重的api就好了。
这样我就实现了无缝重启。
2、线上日志刷太快,肉眼无法捕捉有效信息,如何确定上线功能是ok的?
我个人是喜欢打很详细的业务日志,检索指定日志(grep -ni 'xxx' server.log)这是我最常用的线上排查问题的方式。但是我有三台api服务,三台job服务,我需要有一个日志聚合的地方,方便查询所有的日志。
很多公司采用的方案是搭建一套ELK日志收集、检索的系统,但这不适合个人,我采用的是阿里云的日志服务。
所有的日志保存7天,7天只是我个人的选择,节约成本并且可控而已,我并不建议你们也这么做。
阿里巴巴8月3日发布的《JAVA开发手册嵩山版》上有说日志最少保存15天,可以看到三个周一,国家规定是保存60天。

有了实时收集的日志,我就可以查看一段时间以内接口请求的数量,error级别的日志量等各种维度的数据,通过这些数据来验证代码是否有问题,但这依旧不能彻底解决我的问题。
无论如何单凭日志是无法决定上线的功能是否有问题,只能证明代码没有运行异常。
3、降低上线风险、快速回滚
为了尽可能的降低上线的风险,我需要清楚的知道每次上线的时候明确改动的文件有哪些,它对业务的影响范围如何。
每一次上线后,我都需要观察如下几个维度的数据情况:
- 3分钟内,error级别的日志数量;
- 10分钟内,交易数据怎么样?
- 30分钟,当前小时的arpu值同比前天、昨天的数据如何?
- 重点关注本次上线功能是否如期运行,所产生数据是否与期望一致。
很多时候,项目的回滚不是因为程序运行出错了,而是因为业务数据不理想,更可气的是,一旦回滚之后,业务数据确实又恢复上来了。
因此,我需要能够方便的回滚到任何一个版本,且尽可能的降低上线的风险。
还记得上面那个部署的图吗?

具体流程:我的代码提交到仓库后,通过jenkins进行构建,产生最终的class文件,并通过版本控制上传到class文件仓库,最终增量同步文件到服务器上去,并打一个tag作为本次上线的记录,这一切都通过脚本来操作完成。
4、结束语
我的经验并不适合你,你得有自己的一套知识体系,并且它曾经被你实际验证过,而且你应该不断提升这些技能的熟练度,然后再去看别人怎么玩,最后你才会有所比较,知道好与不好,获得真正属于自己的心得。