ByteBuf是为了解决ByteBuffer的问题和满足网络应用程序开发人员的日常需求而设计的.
JDK中ByteBuffer的缺点:
ByteBuf做了哪些增强?
三个重要属性:
提供了两个指针变量来支持顺序读和写操作,分别是readerIndex和writeInDex,也就把缓冲区分成了三个部分:
0[ --已读可丢弃区域-- ]reaerIndex[ --可读区域-- ]writerIndex[ --待写区域-- ]capacity常用方法定义:
我们可以对这些api做一些测试,如下:
package io.netty.example.echo;
import JAVA.util.Arrays;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
/**
* @author daniel
* @version 1.0.0
* @date 2021/12/20
*/
public class ApiTest {
public static void main(String[] args) {
//1.创建一个非池化的ByteBuf,大小为10字节
ByteBuf buf = Unpooled.buffer(10);
System.out.println("原始ByteBuf为:" + buf.toString());
System.out.println("1.ByteBuf中的内容为:" + Arrays.toString(buf.array()));
System.out.println();
//2.写入一段内容
byte[] bytes = {1,2,3,4,5};
buf.writeBytes(bytes);
System.out.println("写入的bytes为:" + Arrays.toString(bytes));
System.out.println("写入一段内容后ByteBuf为:" + buf);
System.out.println("2.ByteBuf中的内容为:" + Arrays.toString(buf.array()));
System.out.println();
//3.读取一段内容
byte b1 = buf.readByte();
byte b2 = buf.readByte();
System.out.println("读取的bytes为:" + Arrays.toString(new byte[]{b1, b2}));
System.out.println("读取一段内容后ByteBuf为:" + buf);
System.out.println("3.ByteBuf中的内容为:" + Arrays.toString(buf.array()));
System.out.println();
//4.将读取的内容丢弃
buf.discardReadBytes();
System.out.println("丢弃已读取的内容后ByteBuf为:" + buf);
System.out.println("4.ByteBuf中的内容为:" + Arrays.toString(buf.array()));
System.out.println();
//5.清空读写指针
buf.clear();
System.out.println("清空读写指针后ByteBuf为:" + buf);
System.out.println("5.ByteBuf中的内容为:" + Arrays.toString(buf.array()));
System.out.println();
//6.再次写入一段内容,比第一段内容少
byte[] bytes2 = {1,2,3};
buf.writeBytes(bytes2);
System.out.println("再写入的bytes2为:" + Arrays.toString(bytes2));
System.out.println("再写入一段内容后ByteBuf为:" + buf);
System.out.println("6.ByteBuf中的内容为:" + Arrays.toString(buf.array()));
System.out.println();
//7.将ByteBuf清空
buf.setZero(0, buf.capacity());
System.out.println("内容清空后ByteBuf为:" + buf);
System.out.println("7.ByteBuf中的内容为:" + Arrays.toString(buf.array()));
System.out.println();
//8.再次写入一段超过容量的内容
byte[] bytes3 = {1,2,3,4,5,6,7,8,9,10,11};
buf.writeBytes(bytes3);
System.out.println("写入超量的bytes3为:" + Arrays.toString(bytes3));
System.out.println("写入超量内容后ByteBuf为:" + buf);
System.out.println("8.ByteBuf中的内容为:" + Arrays.toString(buf.array()));
System.out.println();
}
}从这些api的使用中就可以体会到ByteBuf比ByteBuffer的强大之处,我们可以深入研究一下它在写入超量数据时的扩容机制,也就是buf.writeBytes(byte[])方法
容量默认值为256字节,最大值为Integer.MAX_VALUE,也就是2GB
实际调用
AbstractByteBuf.writeBytes,如下:
AbstractByteBuf.writeBytes
@Override
public ByteBuf writeBytes(byte[] src) {
writeBytes(src, 0, src.length);
return this;
}AbstractByteBuf.writeBytes(src, 0, src.length);
@Override
public ByteBuf writeBytes(byte[] src, int srcIndex, int length) {
ensureWritable(length); //检查是否有足够的可写空间,是否需要扩容
setBytes(writerIndex, src, srcIndex, length);
writerIndex += length;
return this;
}AbstractByteBuf.ensureWritable(length);
@Override
public ByteBuf ensureWritable(int minWritableBytes) {
ensureWritable0(checkPositiveOrZero(minWritableBytes, "minWritableBytes"));
return this;
}AbstractByteBuf.ensureWritable0(checkPositiveOrZero(minWritableBytes, "minWritableBytes"));
final void ensureWritable0(int minWritableBytes) {
final int writerIndex = writerIndex(); //获取当前写下标
final int targetCapacity = writerIndex + minWritableBytes; //计算最少需要的容量
// using non-short-circuit & to reduce branching - this is a hot path and targetCapacity should rarely overflow
if (targetCapacity >= 0 & targetCapacity <= capacity()) { //判断当前容量是否够用
ensureAccessible(); //检查ByteBuf的引用计数,如果为0则不允许继续操作
return;
}
if (checkBounds && (targetCapacity < 0 || targetCapacity > maxCapacity)) { //判断需要的容量是否是合法值,不合法为true直接抛出越界异常
ensureAccessible();//检查ByteBuf的引用计数,如果为0则不允许继续操作
throw new IndexOutOfBoundsException(String.format(
"writerIndex(%d) + minWritableBytes(%d) exceeds maxCapacity(%d): %s",
writerIndex, minWritableBytes, maxCapacity, this));
}
// Normalize the target capacity to the power of 2.(标准化为2的次幂)
final int fastWritable = maxFastWritableBytes();
int newCapacity = fastWritable >= minWritableBytes ? writerIndex + fastWritable
: alloc().calculateNewCapacity(targetCapacity, maxCapacity); //计算扩容后容量(只要扩容最小64)
// Adjust to the new capacity.
capacity(newCapacity); //设置新的容量
}alloc().calculateNewCapacity(targetCapacity, maxCapacity) -> AbstractByteBufAllocator
@Override
public int calculateNewCapacity(int minNewCapacity, int maxCapacity) {
checkPositiveOrZero(minNewCapacity, "minNewCapacity"); //最小所需容量
if (minNewCapacity > maxCapacity) { //判断最小所需容量是否合法
throw new IllegalArgumentException(String.format(
"minNewCapacity: %d (expected: not greater than maxCapacity(%d)",
minNewCapacity, maxCapacity));
}
final int threshold = CALCULATE_THRESHOLD; // 4 MiB page 阈值超过4M以其他方式计算
if (minNewCapacity == threshold) { //等于4M直接返回4M
return threshold;
}
// If over threshold, do not double but just increase by threshold.
if (minNewCapacity > threshold) { //大于4M,不需要加倍,只需要扩大阈值即可
int newCapacity = minNewCapacity / threshold * threshold;
if (newCapacity > maxCapacity - threshold) {
newCapacity = maxCapacity;
} else {
newCapacity += threshold;
}
return newCapacity;
}
// 64 <= newCapacity is a power of 2 <= threshold
final int newCapacity = MathUtil.findNextPositivePowerOfTwo(Math.max(minNewCapacity, 64)); //计算不少于所需容量的最小的2次幂的值
return Math.min(newCapacity, maxCapacity); //取容量所允许的最大值和计算的2次幂的最小值,当然在这儿就是newCapacity=64
}总结一下就是最小所需容量是否等于阈值,如果是直接返回阈值此后直接扩大阈值,否则以64为最小2次幂为基础每次扩大二倍直到阈值.
netty针对ByteBuf提供了8中具体的实现方式,如下:
|
堆内/堆外 |
是否池化 |
访问方式 |
具体实现类 |
备注 |
|
heap堆内 |
unpool |
safe |
UnpooledHeapByteBuf |
数组实现 |
|
heap堆内 |
unpool |
unsafe |
UnpooledUnsafeHeapByteBuf |
Unsafe类直接操作内存 |
|
heap堆内 |
pool |
safe |
PooledHeapByteBuf |
|
|
heap堆内 |
pool |
unsafe |
PooledUnsafeHeapByteBuf |
~ |
|
direct堆外 |
unpool |
safe |
UnpooledDirectByteBuf |
NIO DirectByteBuffer |
|
direct堆外 |
unpool |
unsafe |
UnpooleUnsafedDirectByteBuf |
~ |
|
direct堆外 |
pool |
safe |
PooledDirectByteBuf |
~ |
|
direct堆外 |
pool |
unsafe |
PooledUnsafeDirectByteBuf |
~ |
在使用时,都是通过ByteBufAllocator分配器进行申请,同时分配器具有内存管理的功能。
在这儿堆内和堆外没有什么区别,对api的使用时一样的,仅仅是通过Unpooled申请的不一样.
那个safe和unsafe有什么区别呢?
以UnpooledHeapByteBuf和UnpooledUnsafeHeapByteBuf中的getByte(int index)方法为例进行分析
UnpooledHeapByteBuf
@Override
public byte getByte(int index) {
ensureAccessible();
return _getByte(index); //真正的获取字节的方法
}
@Override
protected byte _getByte(int index) {
return HeapByteBufUtil.getByte(array, index); //通过HeapByteBufUtil工具类获取数据
}HeapByteBufUtil
static byte getByte(byte[] memory, int index) {
return memory[index];
}UnpooledHeapByteBuf从堆内数组中获取数据,这是安全的
UnpooledUnsafeHeapByteBuf
@Override
public byte getByte(int index) {
checkIndex(index);
return _getByte(index);
}
@Override
protected byte _getByte(int index) {
return UnsafeByteBufUtil.getByte(array, index);
}PlatformDependent0
static byte getByte(byte[] data, int index) {
return UNSAFE.getByte(data, BYTE_ARRAY_BASE_OFFSET + index);
}UnpooledUnsafeHeapByteBuf是通过UNSAFE来操作内存的
现在我们来研究一下Unsafe
Unsafe意味着不安全的操作,但是更底层的操作会带来性能提升和特殊功能,Netty中会尽力使用unsafe以提升系统性能
Java语言很重要的特性就是一次编译到处运行,所以它针对底层的内存或者其他操作做了很多封装,而unsafe提供了一系列我们操作底层的方法,可能会导致不兼容或不可知的异常.
比如:
既然这些东西都是jdk封装好的,而是netty也是直接使用的,所以我们无论在使用safe还是unsafe的时候都是无感知的,我们无需关系底层的操作逻辑,因为api都是一样的,只是实现不一样
是否还有一个疑问,池化和非池化是什么意思?
比如在使用Unpooled.buffer(10)申请一个缓存区的时候,默认非池化申请的一个缓冲区.
池化和非池化的区别主要是申请内存缓存空间以及缓存空间的使用上,体现为内存复用.
理论如此,netty中是如何做到内存复用的?
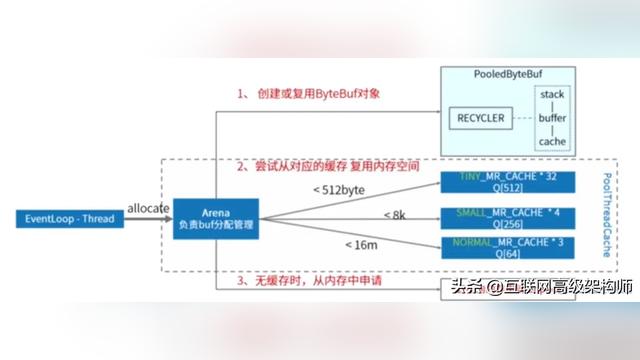
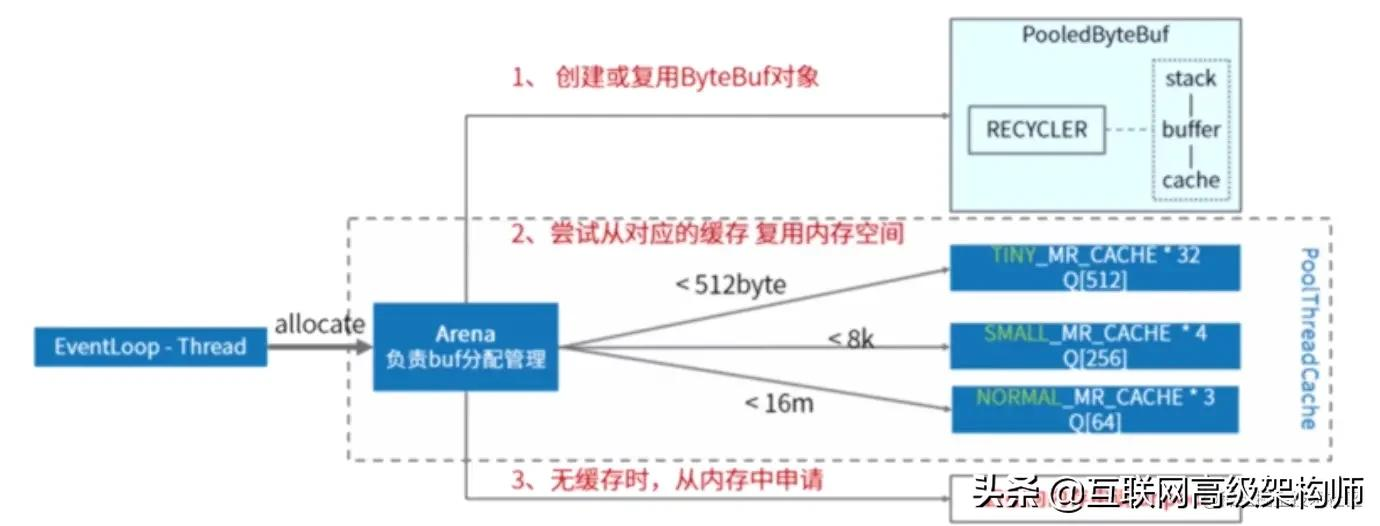
在netty中每一个EventLoopThread由PooledBytebufAllocator内存分配器实力维护了一个线程变量叫做PoolThreadCache,在这个变量中维护了3种规格的MemoryRegionCache数组用作内存缓存,MemoryRegionCache内部是链表,队列里面存Chunk.
首先内存内存分配器会寻找合适的ByteBuf对象进行复用;
之后从内存数组中找到合适的内存空间进行复用;
PoolChunk里面维护了内存引用,内存复用的做法就是把ByteBuf的memory指向chunk的memory.
如果没有找到对应的缓存空间,则直接向内存申请unpool的缓存空间.
netty中默认(池化)也是这样做的,这也是netty性能高效的一个原因,但是就像example例子一样,如果我们自己创建的话,netty推荐我们使用unpool.
==需要注意的是即使创建了可复用的ByteBuf,但是使用过后一直没有被release,也就是没有被回收也是不能被复用的,这是应用设计时应该注意的.==
说了半天的废话,总算是要说到零拷贝机制了
Netty的零拷贝机制是一种应用层的表现,和底层JVM/操作系统内存机制并无过多关联,你可认为netty就是一个软件,我们在用这个软件来创造另一个软件.
ByteBuf的零拷贝机制也是Netty高性能的一个原因.
作者:梧桐小站
链接:
https://juejin.cn/post/7049754668653608997
来源:稀土掘金