Dota2 Ti 结束了,还是有些忧伤的,毕竟一年不如一年了,一鼓作气,再而衰… 明年 TI 成绩可能还没有今年好,不破不立,中国队明年加油!
今天继续 seo 系列,总结下最近 SEO 方面的学习,要想做好 SEO,肯定是要了解搜索引擎原理的,所以我先从这里入手学习,话不多说,上干货。
搜索引擎的搜索流程肯定是相当复杂的,对于我们来说最关心网站的排名逻辑,如果是应用的话我们最关心应用的排名,搜索引擎都有自己的爬虫程序,俗称蜘蛛。蜘蛛爬取就像用户访问浏览器,访问了之后网站会返回自己的 html 代码,这时候蜘蛛程序会把这些存储到数据库,方便后续用来检索,当然搜索引擎都会使用多个蜘蛛来爬取的。
这里就涉及到了一个协议,蜘蛛会先访问网站根目录的 robots.txt ,这里面可以配置禁止蜘蛛爬取的文件目录,要谨慎配置,因为大家都希望自己的网站所有页面都被蜘蛛爬取到,这样用户通过搜索引擎才能搜索到。
大体了解了搜索原理我们差不多可以知道,如果蜘蛛程序经常爬取我们的网站,那我们的排名肯定会慢慢上升啊,有几种常见的方式吸引蜘蛛:
如果知名的网站里面有我们网站的外链,可想而知我们的网站也不错,这里提供一个方法就是百科,百科是可以编辑的,大家可以经常去搜索各种字词,当发现某个字词的链接已经失效了,那么把自己网站的链接加上,这样我们就获得了一个来自百科的外链,是不是很机智。
一个网站的首页是整个网站权重最大的,其次就是距离首页最近的,所以如果除了首页的其他页面哪个页面重要就把它放在距离首页最近。
如果你的页面经常有内容变动,那么蜘蛛程序就要不断的抓取你的页面把新的内容存储到数据库,应用也一样,内容经常更新,谷歌爬虫就会经常抓取你的应用内容,慢慢的就会增加排名。所以大家遇到的应用上线好久都没人下载,慢慢来,经常更新下内容,或许有帮助哈。
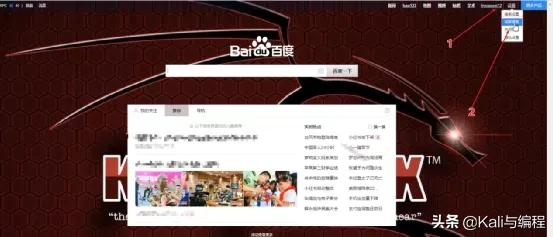
什么是页面结构?大家可以尝试在搜索框搜索一些字词,然后看下搜索结果都展示了什么,比如我搜索了机票:

首先是最大的标题,对应 html 标签的 title,其次是域名,然后是描述,最下面是网页里面的 Tab,所以我们的网站也要有这些结构,当然这几个是最基本的格式,还有其他格式,后面慢慢分析,比如:

以上是我最近学习到的一些方法,现在的搜索引擎也越来越复杂并且智能,比如我们搜索苹果,搜索引擎怎么知道我们是要搜苹果水果,还是苹果公司呢,我也非常好奇它会怎么判断,这个问题接下来慢慢去研究。
更多精彩文章关注公众号:jin广越