摘要:
计算机操作系统内存管理是十分重要的,因为其中涉及到很多设计很多算法。《深入理解计算机系统》这本书曾提到过,现在操作系统存储的设计就是“带着镣铐跳舞”,造成计算机一种一种容量多,速度快的假象。包括现在很多系统比如数据库系统的设计和操作系统做法相似。所以在学习操作系统之余我来介绍并总结一些操作系统的内存管理。
首先我们看一下计算机的存储层次结构

按照金字塔结构可以分为四种类型: 寄存器,快速缓存,主存和外存。而
寄存器和L1缓存都在Processor内部。在金字塔中,越往下价格越低速度越慢但容量越大。
还有两种存储空间需要分清:
- 地址空间:又称逻辑地址空间,源程序经过编译后得到的目标程序,存在于它所限定的地址范围内,这个范围称为地址空间。地址空间是逻辑地址的集合。
- 内存空间: 又称存储空间或物理地址空间。是指主存中一系列存储信息的物理单元(划重点)的集合,这些单元的编号称为物理地址或绝对地址。
简言之就这两个空间分别是程序员能够观测到的存储空间和真实的物理空间。
需求与管理的目标
需求:
- 每个程序员希望没有第三方因素干扰程序运行
- 计算机希望将有限的资源尽可能为多个用户提供服务
为了满足需求的目标:
- 计算机至少同时存在一个用户程序和一个服务器程序(操作系统内核管理)
- 每个程序互不干扰,所以其地址空间应该相互独立。
- 每个程序使用的空间应该被保护,最怕运行的时候程序中断。就和看电影的时候无法播放一样难受。
程序的内存管理
操作系统在内存中的位置有以下三种可能

只有一个程序的环境下的内存管理
此时整个内存只有两个程序,即用户程序和操作系统。
操作系统所占的空间是固定的,则用户程序空间也是固定的,因此可以将用户程序永远加载到同一个地址,即用户程序永远从同一个地方开始运行。这种情况下,用户程序地址可以在运行之前就可以计算出来。
我们通过加载器计算程序运行之前的物理地址静态翻译。此时既不需要额外实现地址独立和地址保护。因为用户不需要知道物理内存的相关知识,而且也没有其它用户程序。
多个程序的环境下的内存管理
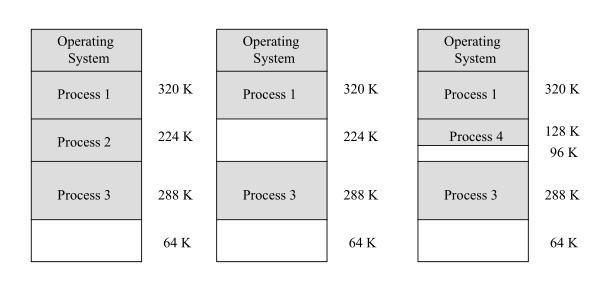
此时用户的程序空间需要通过分区来分给多个不同的程序了。每个应用程序占用一个或几个分区,这种分配支持多个程序并发执行,但难以进行内存分区的共享。
其中分区有两种方法:
一种方法: 固定(静态)式 分区分配, 让程序适应分区
顾名思义就是把内存划分为若干个固定大小的连续分区,这几个分区或者大小相等以适合多个相同程序并发,或者大小不等的分区以适合不同大小的程序。
这种分配方法优点很明显,在于非常容易实现,开销小。
缺点就是会产生很多内部碎片(也就是未被利用的存储空间),固定的分区总数也限制了并发执行的程序数目。我们简单介绍下静态分配的几种方法。
- 单一队列的分配方式
- 多队列分配方式
- 固定分区管理先使用表进行大小初始化,固定分区大小
另一种方法:可变(动态)式 分区分配, 让分区适应程序
此时分区的边界可以移动,但也产生了分区与分区之间狭小的外部碎片。
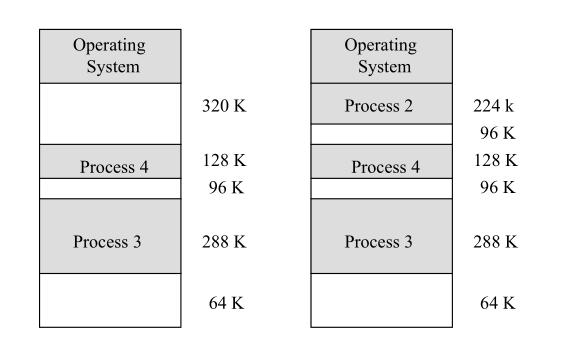
在可变分区中,知道内存的空闲空间大小就十分重要了。OS通过跟踪内存使用计算出内存有多少空闲。跟踪的方法有两种:
位图表示法:
也就是所谓的bitmap,用每一位来存放某种状态。将内存每一个分配单元赋予一个判断的用于判断状态的字位,字位取值位0表示单元闲置;字位为1表示单元被占用
- 特点
- 空间成本固定:不受内存程序数量影响
- 时间成本低:操作的时候只需要将状态值改变
- 缺少容错能力:由于内存单元发生错误的时会将状态值改变,对操作系统来讲,这个状态值是因为发生错误发生的改变还是原来的状态很难判断。
链表表示法
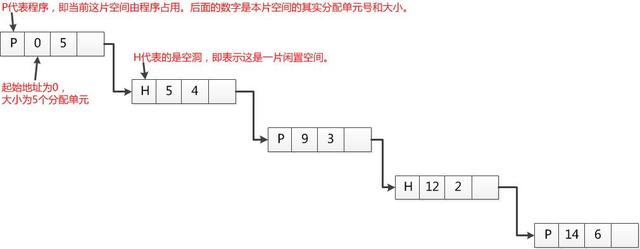
将分配单元按照是否闲置链接,P代表这个空间被占用,H代表这个这是一片闲置空间。为了方便遍历查询,每个程序空间的结点接着一个空闲空间的结点每个链表结点还有一个起始地址,与分配单元的大小,用代码表示为
enum Status{P=0,H=1};
struct LinkNode{
enum Status status;//P表示程序,H表示空闲
struct LinkNode *begin_address;//起始地址
size_t size;//闲置空间大小
struct LinkNode *next;
};
- 特点空间成本:取决于程序数量时间成本:链表不停的遍历速度很慢,同时还要进行链表的插入和删除修改。有一定的容错能力,可以通过程序空间结点和空闲空间结点相互验证。
可变分区的内存分配
OS通过上面两种跟踪方法知道内存空闲容量,而现在操作系统一般都以链表的形式进行内存空闲容量跟踪。如果有新的程序需要读入内存,可变分区就要对空闲的分区进行内存分配。
内存分配使用两张表:已分配分区表和未分配分区表。用C++描述如下:
//未分配分区表
struct FreeBlock {
int id; // 内存分区号
int address; // 该分区的首地址
unsigned length; // 分区长度
};
//已分配分区表
struct AllocatedBlock {
int id; // 内存分区号
int address; // 该分区的首地址
int pid; // 进程 ID
unsigned length; // 分区长度
};
然后OS用双向链表将所有未分配分区表进行串联
struct{
FreeBlock data;
Node* prior;
Node* next;
}Node;
未分配分区表在整个系统空间上的结构如下:
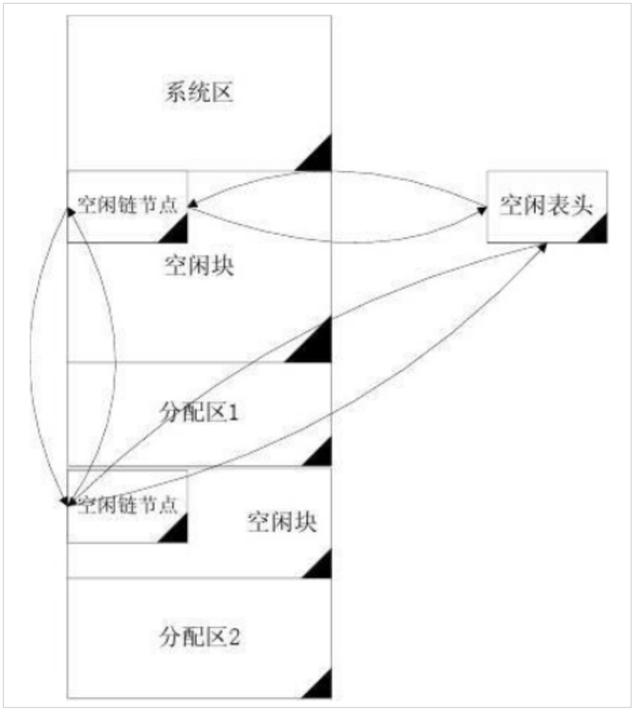
基于 顺序搜索 的分配算法:
这里我们介绍四种基于顺序搜索的寻找空闲存储空间的算法:
- 首次适应算法( First Fit ) :每个空白区按其地址顺序连在一起,从这个空白区域链的始端开始查找,选择第一个足以满足请求的空白块。
- 下次适应算法( Next Fit ) :将存储空间中空白区构成一个循环链,每次为存储请求查找合适的分区时,总是从上次查找结束的下一个空闲块开始,只要找到一个足够大的空白区,就将它划分后分配出去。
- 最佳适应算法( Best Fit ) : 为一个作业选择分区时,总是寻找其大小最接近(小于等于)于作业所要求的存储区域。
- 最坏适应算法( Worst Fit ) :为作业选择存储区域时,总是寻找最大的空白区。
算法举例!!
系统中空闲分区表如下按照地址递增次序排列,现有三个作业分配申请内存空间100K,30K,7K。
区号大小地址状态132K20K未分配28K52K未分配3120K60K未分配4331K180K未分配
- 首次适应:从上到下寻找合适的大小申请作业100K,从低地址到高地址找到3号分区,分配完后3号分区起始地址变为100K+60K=160K,剩余空间为120K-100K=20K申请作业30K,从低地址到高地址找到1号分区,分配完后1号分区起始地址变为20K+30K=50K,剩余空间为32K-30K=2K申请作业7K,从低地址到高地址找到2号分区,分配完后2号分区起始地址变为52K+7K=59K,剩余空间为8K-7K=1K结论:优先利用内存低地址部分的空闲分区。但由于低地址部分不断被划分,留下许多难以利用的很小的空闲分区(碎片或零头) ,而每次查找又都是从低地址部分开始,增加了查找可用空闲分区的开销。
- 下次适应申请作业100K,找到3号分区,分配完后3号分区起始地址变为100K+60K=160K,剩余空间为120K-100K=20K申请作业30K,从3号分区后继续出发,找到4号分区,分配完后4号分区起始地址变为180K+30K=210K,剩余空间为331K-30K=301K申请作业7K,从4号分区后继续出发,找到1号分区,分配完后1号分区起始地址变为20K+7K=27K,剩余空间为32K-7K=25K结论:使存储空间的利用更加均衡,不致使小的空闲区集中在存储区的一端,但这会导致缺乏大的空闲分区。
- 最佳适应算法申请作业100K,找到最适合的3号分区,分配完后3号分区起始地址变为100K+60K=160K,剩余空间为120K-100K=20K申请作业30K,找到最适合的1号分区,分配完后1号分区起始地址变为20K+30K=50K,剩余空间为32K-30K=2K申请作业7K,找到最适合的2号分区,分配完后1号分区起始地址变为52K+7K=59K,剩余空间为8K-7K=1K结论:若存在与作业大小一致的空闲分区,则它必然被选中,若不存在与作业大小一致的空闲分区,则只划分比作业稍大的空闲分区,从而保留了大的空闲分区。最佳适应算法往往使剩下的空闲区非常小,从而在存储器中留下许多难以利用的小空闲区(碎片) 。
- 最坏适应算法申请作业100K,找到4号分区,分配完后3号分区起始地址变为180K+60K=240K,剩余空间为331K-100K=231K申请作业30K,此时被分配过的4号分区依然容量最大,于是还是找到4号分区,分配完后4号分区起始地址变为240+30K=250K,剩余空间为231K-30K=201K申请作业7K,此时被分配过的4号分区依然容量最大,找到4号分区,分配完后4号分区起始地址变为250+7K=257K,剩余空间为201K-7K=194K结论:总是挑选满足作业要求的最大的分区分配给作业。这样使分给作业后剩下的空闲分区也较 大,可装下其它作业。由于最大的空闲分区总是因首先分配而划分,当有大作业到来时,其存储空间的申请往往会得不到满足。
基于顺序搜索的分配算法实际上只适合小型的操作系统,大中型系统使用了是比较复杂的索引搜索的动态分配算法。
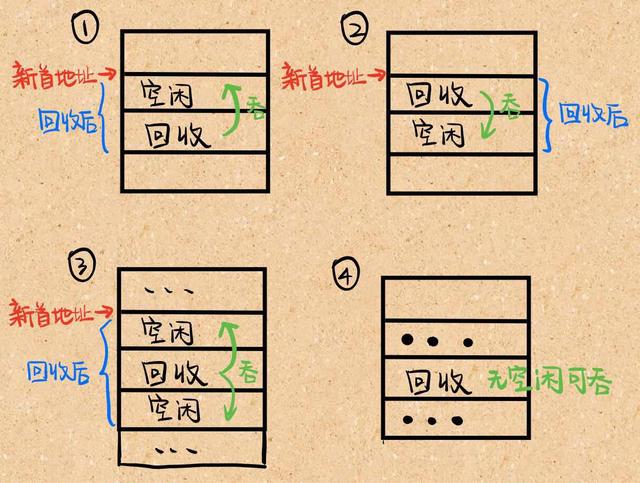
如何回收内存
- 回收分区上邻接一个空闲分区,合并后首地址为空闲分区的首地址,大小为二者之和。
- 回收分区下邻接一个空闲分区,合并后首地址为回收分区的首地址,大小为二者之和。
- 回收分区上下邻接空闲分区,合并后首地址为上空闲分区的首地址,大小为三者之和。
- 回收分区不邻接空闲分区,这时在空闲分区表中新建一表项,并填写分区大小等信息。
用iPad画了一个简单的示意图如下:
最后
内存分配实际上是操作系统非常重要的一环,如果仅限于理论而不写代码实践则容易迷惘,很多具体的实现与都比较困难。如上面的基于顺序搜索的最佳适应算法,比如几个分区的表示方法,都用到了数据结构和算法的知识。如果能用C或者C++完成上述几个算法和操作的具体实现,相信一定会大有脾益的。