随着ChatGPT大火,GPU成为了目前最热单品,一个顶级的GPU可以卖到数万美元。由于对其产品的需求激增,英伟达(NVIDIA)的市场估值更是飙升至2万亿美元以上。
你有没有好奇:为什么AI会带火GPU?AI计算一定要用GPU吗?

今天我们就来一起聊一下GPU到底是什么?
▉ 什么是GPU,与CPU有何区别?
在GPU火之前,提到最多的就是CPU,那么二者有什么区别呢?CPU是不是会被GPU取代呢?

下面我们来看下二者的具体区别:
CPU是Central Processing Unit的错写,CPU通常被称为计算机的"大脑",主要来承担计算的处理功能,操作系统和应用程序运行等操作都必须依赖它来进行,CPU 还决定着计算机的整体速度。
GPU是Graphics Processing Unit的缩写,其最初的设计是用于辅助3D渲染,能同时并行更多指令,其非常适合现在比较热门的动漫渲染、图像处理、人工智能等工作负载。
简单来说,CPU是为延迟优化的,而GPU则是带宽优化的。CPU更善于一次处理一项任务,而且GPU则可以同时处理多项任务。就好比有些人善于按顺序一项项执行任务,有些人可同时进行多项任务。
为演示 CPU 与 GPU 的不同,英伟达曾经邀请亚当·萨维奇 (Adam Savage) 和杰米·海尼曼 (Jamie Hyneman) 利用机器人技术和彩弹再现了一幅广为人知的艺术作品--蒙娜丽莎的微笑。这个视频充分展示了CPU和GPU工作的过程。如下面的视频:
了不起的云计算
,赞
60
可以通过打比方来通俗的解释二者的区别。CPU就好比一辆跑车,而GPU则相当于一辆货车,二者的任务都是从A位置将100 Packages运送到B位置,CPU(跑车)可以在RAM中快速获取一些内存数据(货物),而GPU(货车)执行速度较慢(延迟更高)。但是CPU(跑车)每次只能运送2 Packages,需要50次才能运送完成。
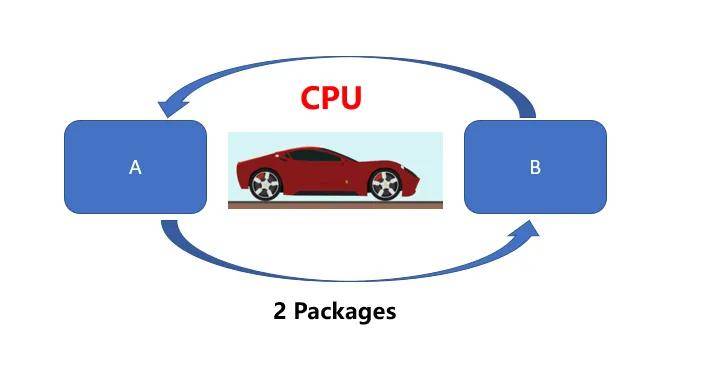
然而GPU(货车)则可以一次获取更多内存数据进行运输。
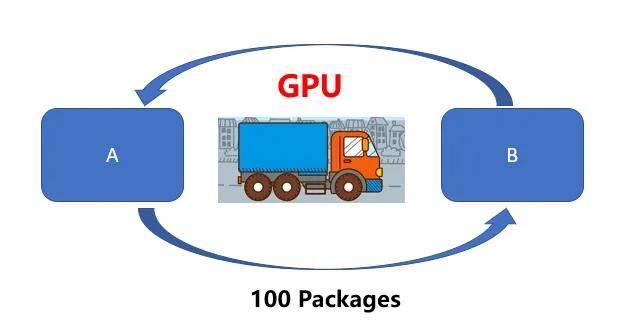
换句话说,CPU更倾向于快速处理少量数据(例如算术运算:5*6*7),GPU更擅长处理大量重复数据(例如矩阵运算:(A*B)*C)。因此,虽然CPU单次运送的时间更快,但是在处理图像处理、动漫渲染、深度学习这些需要大量重复工作负载时,GPU优势就越显著。
目前AI计算的数据类型跟图像处理,深度学习的类型更相似,这也是导致GPU供不应求的重要原因。
那么是什么CPU和GPU有何不同呢?那还具体来看一下。
▉ GPU和CPU有何不同?
首先是二者架构核心不同
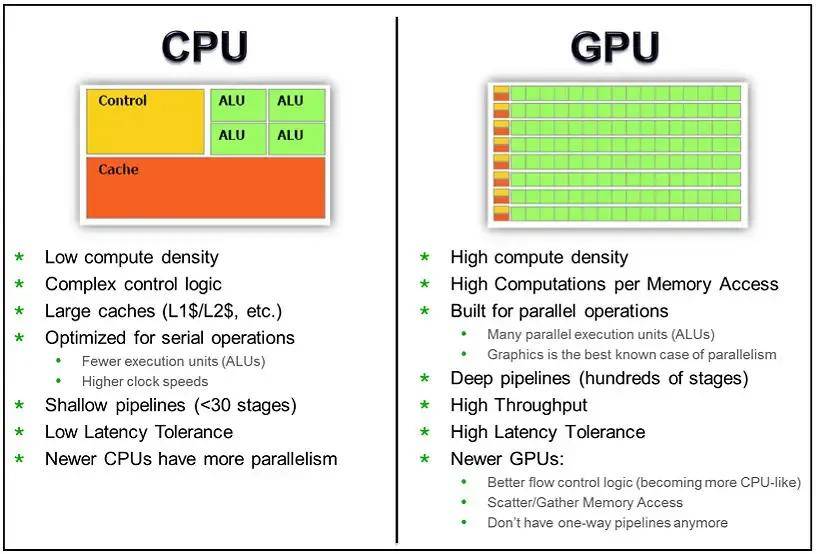
通过下面两张图可以有助于我们理解CPU和GPU工作方式的不同。上文中我们提到,CPU是为顺序的串行处理而设计的,GPU则是为数据的并行而设计的,GPU有成百上千个更小、更简单的内容,而CPU则是有几个大而复杂的内核。
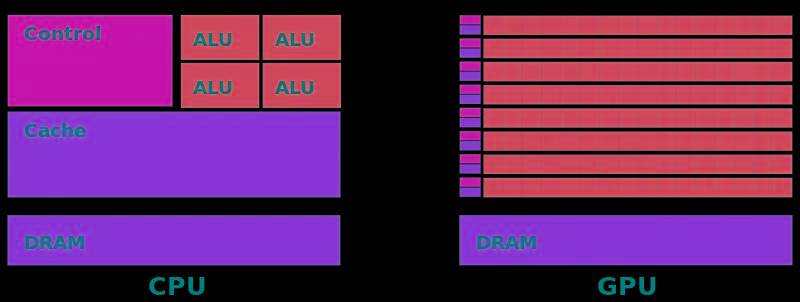
GPU内核经过优化,可以同时对多个数据元素进行类似的简单处理操作。而且CPU则针对顺序指令处理进行了优化,这也导致二者的核心处理能力的不同。
网上有一个比喻用来比较 GPU 和 CPU 核心的区别,我觉得非常贴切,CPU的核心像学识渊博的教授,GPU的核心更像一堆小学生,只会简单的算数运算,可即使教授再神通广大,也不能一秒钟内计算出500次加减法,因此对简单重复的计算来说单单一个教授敌不过数量众多的小学生,在进行简单的算数运算这件事上,500个小学生(并发)可以轻而易举打败教授。
其次是内存架构不同
除了计算差异之外,GPU还利用专门的高带宽内存架构将数据送到所有核心,目前GPU通常用的是GDDR或HBM内存,它们提供的带宽比CPU中的标准DDR 内存带宽的带宽更高。
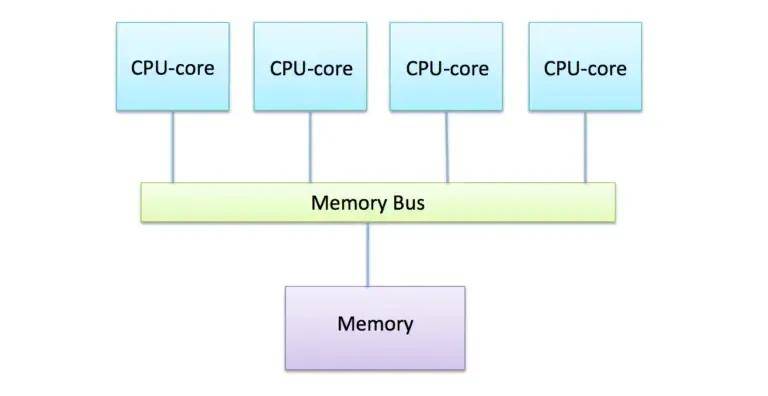
GPU处理的数据被传输到这个专门的内存中,以最大限度地减少并行计算期间的访问延迟。GPU的内存是分段的,因此可以执行来自不同内核的并发访问以获得最大吞吐量。
相比之下,CPU内存系统对缓存数据的低延迟访问进行了高度优化。对总带宽的重视程度较低,这会降低数据并行工作负载的效率。
第三,是并行性
专用内核和内存的结合使GPU能够比CPU更大程度地利用数据并行性。对于像图形、渲染这样的任务,相同的着色器程序可以在许多顶点或像素上并行运行。
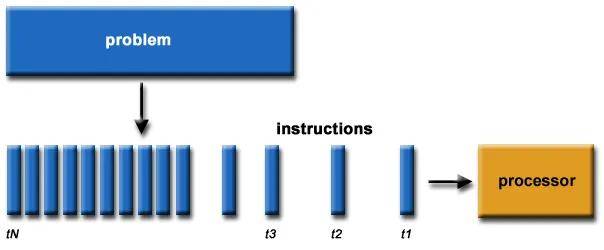
现代GPU包含数千个核心,而高端CPU最多只有不到100个核心。通过更多的核,GPU可以以更高的算术强度在更宽的并行范围内处理数据。对于并行工作负载,GPU核心可以实现比CPU高100倍或更高的吞吐量。
相比之下,阿姆达尔定律意味着CPU对一个算法所能获得的并行加速是有限的。即使有100个内部核心,由于串行部分和通信,实际速度也限制在10倍或更低。由于其大规模并行架构,GPU可以实现几乎完美的并行加速。
第四,是即时(JIT)编译方面
GPU的另一个优点是即时(JIT)编译,它减少了调度并行工作负载的开销。GPU驱动程序和运行时具有JIT编译功能,可以在执行之前将高级着色器代码转换为优化的设备指令。
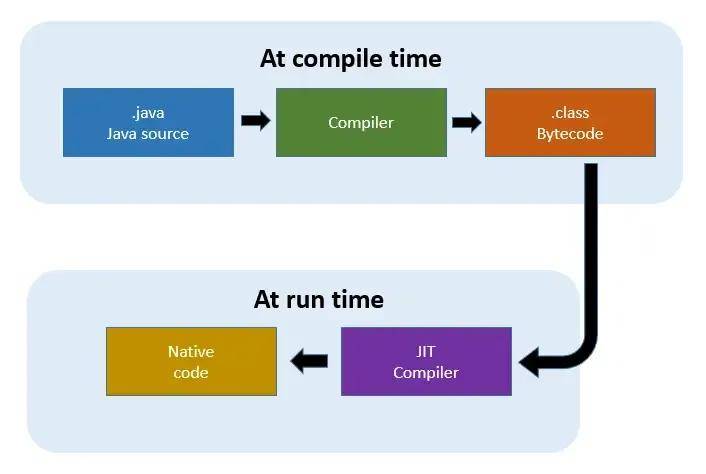
这为程序员提供了灵活性,同时避免了CPU所需的传统离线编译步骤。JIT还支持基于运行时信息的优化,综合效果将GPU开销降低到几乎为零。
相比之下,CPU必须坚持预编译的机器码,不能根据运行时行为自适应地重新编译,因此CPU的调度开销更高,灵活性也更差。
第五,在编程模型方面
与CPU相比,GPU还提供了一个更加出色的并行编程模型CUDA,开发人员可以更快速编写并行代码,而不必担心低级别的线程、同步和通信等问题。
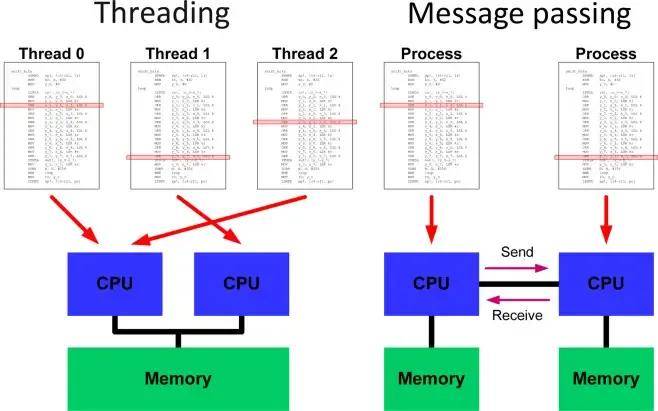
CUDA和OpenCL提供C/ C++编程语言,其中代码专注于跨抽象线程的并行计算,凌乱的协调细节在幕后被无形地处理。
相反,CPU并行性要求使用OpenMP等库直接处理线程。在线程管理、锁和避免竞争条件方面,存在明显的额外复杂性。这使得从高层考虑并行性变得更加困难。
第六,二者响应方式不同
CPU基本上是实时响应,对单任务的速度要求很高,所以就要用很多层缓存的办法来保证单任务的速度。
GPU往往采用的是批处理的机制,即:任务先排好队,挨个处理。
第七,二者的应用方向不同
CPU所擅长的像操作系统这一类应用,需要快速响应实时信息,需要针对延迟优化,所以晶体管数量和能耗都需要用在分支预测、乱序执行、低延迟缓存等控制部分。
GPU适合对于具有极高的可预测性和大量相似的运算以及高延迟、高吞吐的架构运算。目前广泛应用于三大应用市场:游戏、虚拟现实和人工智能。

另外,GPU还可以应用于自动驾驶、医疗影像分析、金融风控等领域。不过,由于不同应用场景对GPU性能的要求不同,因此在选择GPU时需要考虑其计算能力、功耗和应用领域等因素。需要根据任务类型选择最合适的GPU,并进行优化以发挥其性能优势。
▉ GPU的下一步是什么?
由于内核数量和运行速度的提高,GPU的数字处理能力正在稳步提高。但这些改进主要是由台湾台积电(TSMC)等公司在芯片制造方面的改进所推动的。
目前,单个晶体管(任何计算机芯片的基本组成部分)的尺寸正在减小,这使得在相同数量的物理空间中可以放置更多的晶体管。但这并不代表传统GPU对于人工智能相关的计算任务是最佳的。
正如GPU最初设计是为图形提供专门的处理来加速计算机一样,各种加速器也被设计用来加速机器学习任务。由AMD和NVIDIA等公司正在为传统的GPU制造各种加速器来提供其对人工智能等场景的计算需求,例如NVIDIA CUDA以及AMD的ROCm都能够为开发者提供了一个全面的环境,用于创建、优化和部署 GPU 加速应用,确保在各种平台上实现高性能和可扩展性。
除此之外,例如谷歌的张量处理单元和Tenstorrent的Tensix Cores芯片,都是从头开始设计,被用于加速深度神经网络。
通常,数据中心GPU和其他AI加速器通常比传统GPU附加卡配备更多内存,这对于训练大型AI模型至关重要。人工智能模型越大,GPU的能力就要越强,准确度越高。
为进一步加快训练速度,处理更大AI模型(例如ChatGPT),研发者可将许多数据中心GPU汇集到一起形成超级计算机。而这需要更复杂软件方可正确利用可用的数字处理能力。另一种方法则是创建一个非常大规模的加速器,例如芯片初创企业Cerebras生产的“晶圆级处理器”(wafer-scale processor)。
同时,CPU方面的发展并未停滞。AMD和英特尔的最新CPU内置低级指令,可加速深度神经网络所需的数字运算。这一附加功能主要有助于“推理”任务,即利用其他已经开发的AI模型。
但目前来说,要训练人工智能模型,首先需要GPU或者类似GPU的大型加速器。
为特定的机器学习算法创建更专业的加速器是可能的。例如,最近一家名为Groq的公司生产了一种“语言处理单元”(LPU),专门设计用于沿着ChatGPT的路线运行大型语言模型。
但历史表明,任何爆火的机器学习算法都很快地达到顶峰然后式微——因此昂贵的GPU或加速器硬件可能很快就过时。
目前,中国的GPU芯片在市场份额上仍然占据较小的比例,但国产GPU芯片的入局者也越来越多,越来越多的国内企业向图形处理领域转型,比如芯动科技、景嘉微等,国产GPU芯片也有了更好的发展机遇。随着美国实施更多的出口管制措施,或将为"中国芯"崛起制造机会窗口,这可能导致英伟达在中国市场面临更大的竞争压力。