谁将成为屠龙者?
2024开年,去年大涨的科技股一片惨跌,但引领AI浪潮的总龙头英伟达依然势头不减。
没有哪家芯片公司不眼红英伟达的地位,随着AI产业的蛋糕越做越大,硬件赛道也肉眼可见得拥挤起来。大量初创公司正试图流向英伟达GPU的预算里分一杯羹。
媒体汇总了目前处于竞争最前线的12家公司。这些初创企业平均历史只有五年,融资额度最高的已有7.2亿美元,它们都是英伟达的有力挑战者。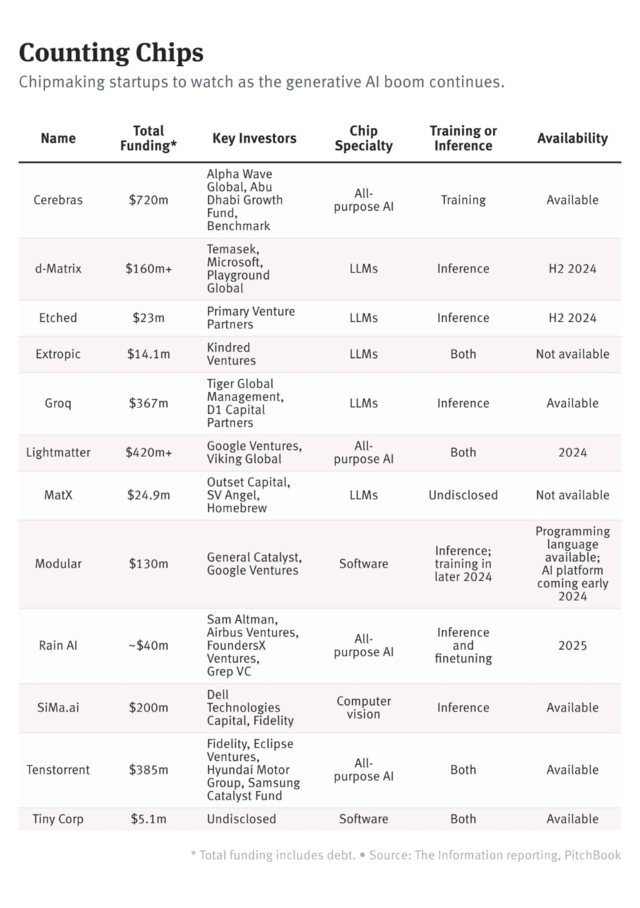
Cerebras以制造巨型芯片闻名。由Gary Lauterbach和Andrew Feldman联合创立。两人还曾经联合创办专注于超高密度计算机服务器业务的公司Seammicro,在2012年被AMD(146.56, -1.46, -0.99%)以高达3.57亿美元的价格收购。
Cerebras的主要产品是可用于AI训练的超级计算机芯片和系统,专为超级计算任务而构建,此类芯片的大小约为普通GPU的56倍。
Cerebras的客户集中于国防、学术实验室等机构。旗舰产品CS-2超算系统已经部署在美国能源部阿贡国家实验室、匹兹堡超算中心、爱丁堡大学超算中心等地。

不过,虽然已经获得高达7亿美元的融资,但受制于英伟达GPU和CUDA生态的主导地位,Cerebras在争取商业客户方面面临着艰巨的挑战。
1月份,公司宣布将与美国顶尖医疗机构梅奥诊所合作,梅奥诊所将使用Cerebras的计算芯片和软件,以数十年的匿名医疗记录和数据为基础,开发专有AI模型。
据报道,一些模型将能够读写文本,比如为新病人总结病历中最重要的部分。其他模型可以分析复杂的医学图片或分析基因组数据。
Cerebras首席执行官Andrew Feldman称,这是一项为期数年、价值“数百万美元”的协议。
创办于2019年的d-Matrix正在开发一种专用芯片和软件,用于运行机器学习模型,公司的芯片可以处理和内存结合在一起,而处理和内存通常是芯片上独立和不同的组件。
d-Matrix的芯片产生的热量更少,因此需要的冷却也更少,因此比主流的GPU和CPU芯片更具成本效益。公司CEO表示,许多公司都希望利用大模型设计AI应用,成本非常重要。
d-Matrix选择专注于推理,即运行AI模型,而非训练。公司认为,随着时间的推移,模型会越来越大,运行成本也会越来越高。公司已有客户在测试其芯片和软件,并计划在24年上半年将投入商用。
Etched由两位哈佛辍学生Gavin Uberti和Chris Zhu于去年6月创立,公司计划生产一款名为Sohu的AI推理加速芯片,推理性能为H100的10倍。公司成立不久后估值即达到3400万美元。
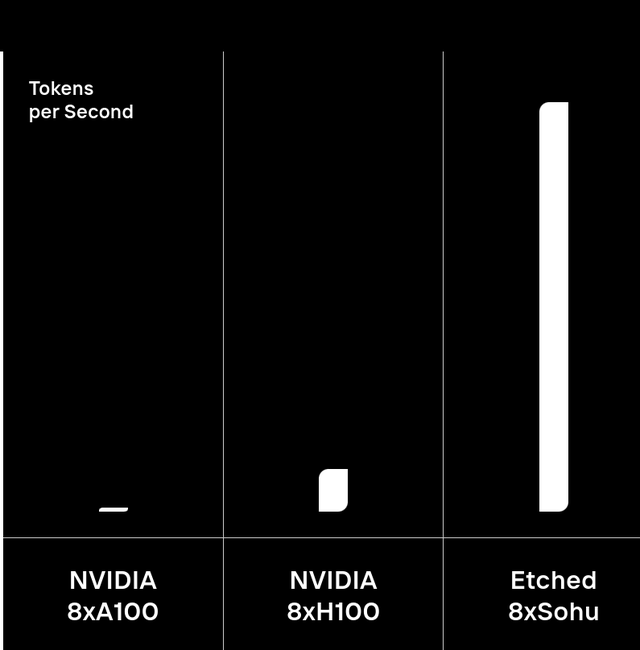
据报道,在制作工艺上,Sohu采用将变压器架构直接刻芯片核心的革命性方法。因此性能可以达到前所未有的高度,与传统GPU相比,Sohu在模拟中运行大模型的速度要快140倍。Sohu还支持通过树搜索更好地编码,能够并行比较数百个响应,同时还能进行多重推测解码(Multicast speculative decoding),可以实时生成新的内容。
Etched的博客称,这种架构将允许以无与伦比的效率运行万亿参数模型。该系统只有一个内核,可容纳完全开源的软件堆栈,可扩展至100T参数模型。
Extropic是这几家初创公司里最神秘的那个。公司创始人出身谷歌(144.24, 0.57, 0.40%)专注前沿技术探索的“登月工厂”部门“X”。据介绍,Extropic专注于量子计算,同时计划开发一款专门用于运行大模型的芯片,但目前仍未有任何关于具体产品的细节曝出。
去年年底,公司刚刚完成1410万美元的种子轮融资。
根据公司的新闻稿,随着生成式人工智能的兴起,世界对可扩展、高成本效益和高效计算的需求急剧增加,Extropic希望在未来,让计算机把熵作为一种资产加以利用,通过编程自我学习,并以前所未有的效率运行:
Extropic的计算范式建立在热力学原理之上,旨在将生成式人工智能与世界的基本物理学无缝融合。我们的目标是将生成式人工智能最终嵌入物理过程,突破物理定律在空间、时间和能量方面规定的效率极限。
Graphcore成立于2016年,总部位于英国布里斯托尔。公司主要产品的智能处理单元(LPU),且聚焦于大模型推理。
公司产品最大的特点就是极快的生成速度,可以确保流畅的终端体验。在消费类AIGC应用中,用户对速度要求很高,而Groq LPU搭配开源模型Meta Llama 2 70B可以实现每秒生成300个单词,在7分钟内就能生成与莎士比亚的《哈姆雷特》相同数量的单词,这比普通人的打字速度快75倍。
Groq联合创始人兼首席执行官Jonathan Ross认为,对于在产品中使用人工智能的公司来说,推理成本正在成为一个问题,因为随着使用这些产品的客户数量增加,运行模型的成本也在迅速增加。与英伟达GPU相比,Groq LPU集群将为大模型推理提供更高的吞吐量、更低的延迟和更低的成本。
此外,受制于HBM3和CoWoS封装的产能,英伟达GPU目前的产能无法完全满足客户需求,而Groq LPU的独特之处在于,它不依赖于三星或海力士的HBM,也不依赖于台积电(101.24, 0.02, 0.02%)的CoWoS封装技术,因此不会面临类似英伟达那样的产能瓶颈。
Lightmatter利用激光器发出的光在芯片和服务器群之间传输数据,公司由麻省理工学院的学生利用该校的专利技术创立。
据公司联合创始人兼首席执行官Nicholas Harris介绍,与英伟达、AMD和英特尔(47.12, -0.52, -1.09%)等通过线缆传输数据的芯片厂商相比,Lightmatter的产品可以让数据中心的能耗成本降低约80%。
MatX由前谷歌员工创办,首席执行官Reiner Pope为谷歌Pathways大模型的开发者之一,首席技术官Mike Gunter则是谷歌TPU的研发人员之一。
MatX正在开发用于文本应用的LLM专用芯片。公司表示,与英伟达GPU硬件相比,其自研芯片的运行速度更快,成本更低,可支持包括图像生成在内的多种人工智能应用。
MatX称,公司已经得到几家风险投资公司的支持,但未披露具体的资金,还称已得到“著名大模型开发商的大力支持”,但也未披露具体公司。
Modular专注于打造用于训练和运行大模型的开发平台和编码语言,用户可在该平台上使用各类AI工具,包括谷歌开源软件TensorFlow和Meta的开源软件PyTorch。
公司认为,AI开发如今面临受到过于复杂和分散的技术基础设施的阻碍,Modulal的使命是消除大规模构建和维护AI系统的复杂性。
构建和运行人工智能应用程序需要大量的计算能力,为控制成本,一家公司可能会使用不同类型的AI芯片,但这些芯片的软件往往互不兼容。尤其是,英伟达用于编写机器学习应用程序的Cuda软件只能在自家芯片上运行,这基本上将开发者锁定在其GPU上。Cuda的用户粘性极强,有报道称,一家计算机视觉初创公司花了两年时间才得以改用非英伟达芯片。
Modular希望通过开发一种Cuda替代方案来改变这种状况,解决不同芯片的软件兼容性问题,让使用非英伟达芯片变得更容易。
传统GPU的训练和推理过程需要消耗产生高昂成本,这部分成本部分源于这些芯片在从内存和处理部件传输数据时产生的热量,因此,GPU需要持续冷却,从而增加了数据中心的电力成本。
而Rain AI的NPU芯片可以模拟人类的生物大脑,将内存和处理功能结合在一起,不仅在计算速度和能效方面表现出色,还可以根据周围环境实时定制或微调人工智能模型。不过公司目前还没有生产出成品。
据媒体报道,一份2019年签订的意向书显示,OpenAI计划斥资5100万美元购买Rain AI NPU芯片,这些芯片将被用于GPT模型的训练和部署。
Sima.ai专注于为边缘计算设备开发硬件和软件,应用于飞机、无人机、汽车和医疗设备等场景,而非数据中心。
公司创始人Krishna Rangasayee曾在芯片制造商赛灵思(Xilinx)工作近二十年。此前,在接受媒体采访时,他表示,许多行业由于种种原因无法使用基于云的AI服务,Sima.ai将专注于服务那些去中心化的边缘计算设备。
例如,自动驾驶汽车需要即时做出决策,只有内置的AI才能满足其对延迟的苛刻要求。而在医疗保健等行业,公司可能不希望将敏感数据发送到云端,而希望将其保存在设备中。
2023年6月,Sima.ai表示已开始量产其第一代边缘人工智能芯片。公司表示,正在与制造业、汽车和航空等领域的50多家客户合作。
Tenstorrent由三位前AMD员工创办,总部位于加拿大多伦多。
Tenstorrent以异构和Chiplet设计的形式来开发RISC-V和AI芯片。目前已经开发出基于12nm工艺的Grayskull和Wormhole两款芯片,FP8算力高达328TFlops。公司的目标是把价格压到类似性能GPU的1/5到1/10。
2021年,Tenstorrent还推出了DevCloud,可以让AI开发人员无需购买硬件即可运行大模型。
不过,最近几年,也许是感受到了英伟达等硬件厂商的压力,Tenstorrent将重心转移到了技术许可和服务领域。
Tiny Corp由自动驾驶初创公司Comma AI的创始人和前首席执行官George Hotz创办,其产品将以名为tinygrad的开源深度学习工具打造,据悉可帮助开发人员加快训练和运行大语言模型。
Hotz认为,tinygrad可以成为Pytorch(源自Meta的深度学习产品)的“有力竞争者”。但目前他还没有透露关于产品的具体细节。
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。