1 前言
导包这个词我相信编程人员不会陌生。如何很好地在Python中导入别人的包以及自己写的工具函数?这时需要分清楚和用好的,特此总结以飨读者。
2 优雅地导入别人的包
当然这里主要指你使用pip(conda)安装到Python环境中的包。这里导包就很简单了,因为在Python解释器在解释程序时会在系统中扫描相关包的路径,不至于找不到。例如你安装了NumPy包,你可以这样导入:
import numpy但是在写Python程序时,你的程序会显得繁琐,在Python编程社区中,我们通常会为其设置一个简称,如:
import numpy as np这样在程序中代码会简洁一些,别人看到np也会知道你导的包是numpy,这已经是行业通用的习惯了。
有时候一个工具包会有多级工具,或者说一个py文件下会有多个函数,假如你想使用numpy中的sin()函数,你可以使用这种方式导入:
from numpy import sin如果你想sin、cos()、tan()等函数,你也可以这样使用通配符“*”导入:
from numpy import *也就是说你把numpy下所有函数导入,虽然可以像往常的时候那样使用,但是并不建议,最好是需要什么函数,你就导入什么函数。需要补充的是:这个“*”所导入的函数都在对应包的__init__.py文件中的__all__ = ['module_1', 'module_2']中。
除此之外,还需要注意的是,不仅numpy下有sin函数,系统的math函数也是有sin函数的,如果你的程序报错了也需要检查一下,特别是在使用from numpy import *。如果两个函数的输入和输出是相同的还好,如果两个函数功能有些差异等就可能报错,如果必须的导入的话,就为对应的函数起一个别名,如:
from numpy import sin as np_sin或者不导入具体的函数,使用下面的方式:
import numpy as np
np.sin(10)这种方式看起来也是比较简单明了的。
3 优雅地使用自己写的函数包
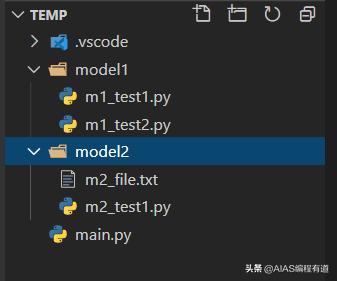
上面导包方式还是比较简单的,但是导入自己的包还是会经常出错的。有时候我们会自己写一些工具函数,但是每每调用是总会出现不同的错误,我们看看如何优雅地导入自己写的函数,或者跨文件夹的文件。在此之前先看看当前测试项目的目录结构和几个路径相关函数。
3.1 项目目录结构和几个路径相关的函数
当前项目的结构如下:

下面来看看几个路径,有如下程序:
import os
import sys
def main():
absPath = os.path.abspath(__file__) # 返回运行当前程序py文件的路径
print('absPath', absPath)
temPath = os.path.dirname(absPath) # 往上返回一级目录,得到文件所在的路径
print('temPath', temPath)
temPath = os.path.dirname(temPath) # 在往上返回一级,得到文件夹所在的路径
print('temPath', temPath)
print(sys.path) # Python解释器查找Python包路径有哪些(Python解释器安装地址因人而异)
if __name__ == "__main__":
main()运行结果如下:
absPath f:testTempmain.py
temPath f:testTemp
temPath f:test
['f:\test\Temp', 'C:\Development\Python\Anaconda3\python37.zip', 'C:\Development\Python\Anaconda3\DLLs', 'C:\Development\Python\Anaconda3\lib', 'C:\Development\Python\Anaconda3', 'C:\Development\Python\Anaconda3\lib\site-packages', 'C:\Development\Python\Anaconda3\lib\site-packages\win32', 'C:\Development\Python\Anaconda3\lib\site-packages\win32\lib', 'C:\Development\Python\Anaconda3\lib\site-packages\Pythonwin']可以看到这时的项目路径变成了'f:\test\Temp\model1',也就是说一个项目的主程序(自己总结,方便理解) 在运行时就决定了整个项目的路径,这为后面的导包提供了依据。需要注意的是导入自写的包后,自写的包被调用时,其整个项目路径依然是项目入口程序那个py文件所对应的路径(这个py文件所处的文件夹)。知道这个后,我们看看以下各种导包情况如何解决,默认只执行main.py这个文件,也就是说确定了这个项目路径(main.py调用其他模块的包)。
3.2 程序入口文件调用各个模块的包
因为默认只执行main.py这个文件,这里以main.py文件调用model1中m1_test1.py的model1_test1()函数为例,看看如何调用,示例程序如下:
其中m1_test1.py的程序如下:
import sys
def model1_test1():
print('model1_test1 is been called!')
if __name__ == "__main__":
print(sys.path)项目入口函数main.py代码如下:
import os
import sys
import model1.m1_test1 as m1t1
def main():
m1t1.model1_test1()
if __name__ == "__main__":
main()程序运行结果:
model1_test1 is been called!因为项目路径是在main.py所在的文件夹,而model1又与main.py处于同一文件级别,则在调用model1模块下的py文件时可以直接从model1开始书写。也需要注意 ,调用model1_test1.py文件时, model1.m1_test1 中的 m1_test1 为对应py文件的文件名。
3.3 同级文件自写py文件引用
以model1模块为例,用m1_test1.py调用m1_test2.py中的model1_test2()函数,在3.2的基础上,为model1_test1.py修改成如下代码:
3.3 同级文件自写py文件引用
以model1模块为例,用m1_test1.py调用m1_test2.py中的model1_test2()函数,在3.2的基础上,为model1_test1.py修改成如下代码:其中m1_test2.py文件中的代码如下:
def model1_test2():
print('model1_test2 is been called!')可以看出,我们在main.py中去运行时,即使两个文件在同一级在导包时也需要从model1开始书写,如果写成这样import m1_test2 as m1t2的话,会出现:
Traceback (most recent call last):
File "f:testTempmain.py", line 3, in <module>
import model1.m1_test1 as m1t1
File "f:testTempmodel1m1_test1.py", line 2, in <module>
import m1_test2 as m1t2
ModuleNotFoundError: No module named 'm1_test2'如果两个同级文件所处深度太深,例如m1_test1.py和m1_test2.py文件在model1/sum_model/sub_sub_model目录下,如果从model1开始写,那导包语句岂不是特别长,这时可以使用以下方式进行修改:
import sys
sys.path.Append('model1/')
import m1_test2 as m1t2当你想测试m1_test2.py文件函数时(直接运行m1_test1.py,即将m1_test1.py所在文件夹当做项目文件路径)这种sys.path导入方式也不会影响程序的运行。
3.4 跨模块导入包
现在我们的程序保持的状态是使用sys.path解决model1中m1_test1.py导入m1_test2 .py的方式。现在我们看看在model1中py文件如何使用model2模块中的py文件。这里我可以想到使用如下导入方式:
import model1.m1_test2 as mt2这种方式就行了嘛。现在我们来看看实际是不是这样的,main.py文件修改如下:
import os
import sys
import model2.m2_test1 as m2t1
def main():
m2t1.model2_test1()
if __name__ == "__main__":
main()m2_test1.py程序如下:
import model1.m1_test2 as m1t2
def model2_test1():
print('model2_test1 is been called!')
if __name__ == "__main__":
m1t2()运行main.py文件查看结果:
model2_test1 is been called!结果正是我们估计的。如果你猜到这么做了,基本上已经理解整个导包的流程。 但想使用sys.path改进,即m2_test1.py程序如下:
import sys
sys.path.append('model1/')
import m1_test2 as m1t2
def model2_test1():
print('model2_test1 is been called!')
if __name__ == "__main__":
m1t2()对于在main.py运行时,结果正常,但是,直接运行m2_test1.py程序时,就会出错,出错结果可想而知,除非你把model1的全路径添加到sys.path中。
3.5 让自写包变得更加标准
如果让你的包变得更加标准的话,这时就需要在对应的模块下添加__init__.py文件了,这个文件中的内容可以什么都没有,但会告诉解释器,这个文件所在文件夹就是一个标准的包了。可以通过配置__init__.py文件限制from module import *中可以导入的py文件等。
3.6 读取文件
在实际的开发过程中,也可能会出现读取同级文件,或跨包文件。类似于包,读取文件的操作则有所不同。读取同级文件如下,把main.py文件修改如下:
import os
import sys
import model2.m2_test1 as m2t1
def main():
m2t1.read_file()
if __name__ == "__main__":
main()m2_test1.py添加如下函数即可(绝对路径方式):
def read_file():
import os
import sys
file_path = 'm2_file.txt'
abs_path = os.path.abspath(__file__) # 获取当前py文件路径
dir_path = os.path.dirname(abs_path) # 获取当前py文件所在目录路径
file_path = os.path.join(dir_path, file_path) # 拼接
with open(file_path) as reader:
print(reader.read())读取跨包的文件方法如下(使用项目路径定位),修改main.py文件代码如下:
import os
import sys
import model1.m1_test2 as m1t2
def main():
m1t2.read_file()
if __name__ == "__main__":
main()修改m1_test2.py代码如下:
def model1_test2():
print('model1_test2 is been called!')
def read_file():
import os
project_root = os.getcwd() # 获取项目根目录
file_path = 'm2_file.txt'
file_path = os.path.join(project_root, 'model2', file_path)
with open(file_path) as reader:
print(reader.read())运行main.py文件即可。
4 总结
总的来说,上面的方法能够应付大多导包和读取文件的问题。但在实际开发过程中,还需要灵活运用,避免按图索骥,生搬硬套。